
Research papers come out far too frequently for anyone to read them all. That’s especially true in the field of machine learning, which now affects (and produces papers in) practically every industry and company. This column aims to collect some of the most relevant recent discoveries and papers — particularly in, but not limited to, artificial intelligence — and explain why they matter.
It takes an emotionally mature AI to admit its own mistakes, and that’s exactly what this project from the Technical University of Munich aims to create. Maybe not the emotion, exactly, but recognizing and learning from mistakes, specifically in self-driving cars. The researchers propose a system in which the car would look at all the times in the past when it has had to relinquish control to a human driver and thereby learn its own limitations — what they call “introspective failure prediction.”
For instance, if there are a lot of cars ahead, the autonomous vehicle’s brain could use its sensors and logic to make a decision de novo about whether an approach would work or whether none will. But the TUM team says that by simply comparing new situations to old ones, it can reach a decision much faster on whether it will need to disengage. Saving six or seven seconds here could make all the difference for a safe handover.
It’s important for robots and autonomous vehicles of all types to be able to make decisions without phoning home, especially in combat, where decisive and concise movements are necessary. The Army Research Lab is looking into ways in which ground and air vehicles can interact autonomously, allowing, for instance, a mobile landing pad that drones can land on without needing to coordinate, ask permission or rely on precise GPS signals.
Their solution, at least for the purposes of testing, is actually rather low tech. The ground vehicle has a landing area on top painted with an enormous QR code, which the drone can see from a fairly long way off. The drone can track the exact location of the pad totally independently. In the future, the QR code could be done away with and the drone could identify the shape of the vehicle instead, presumably using some best-guess logic to determine whether it’s the one it wants.
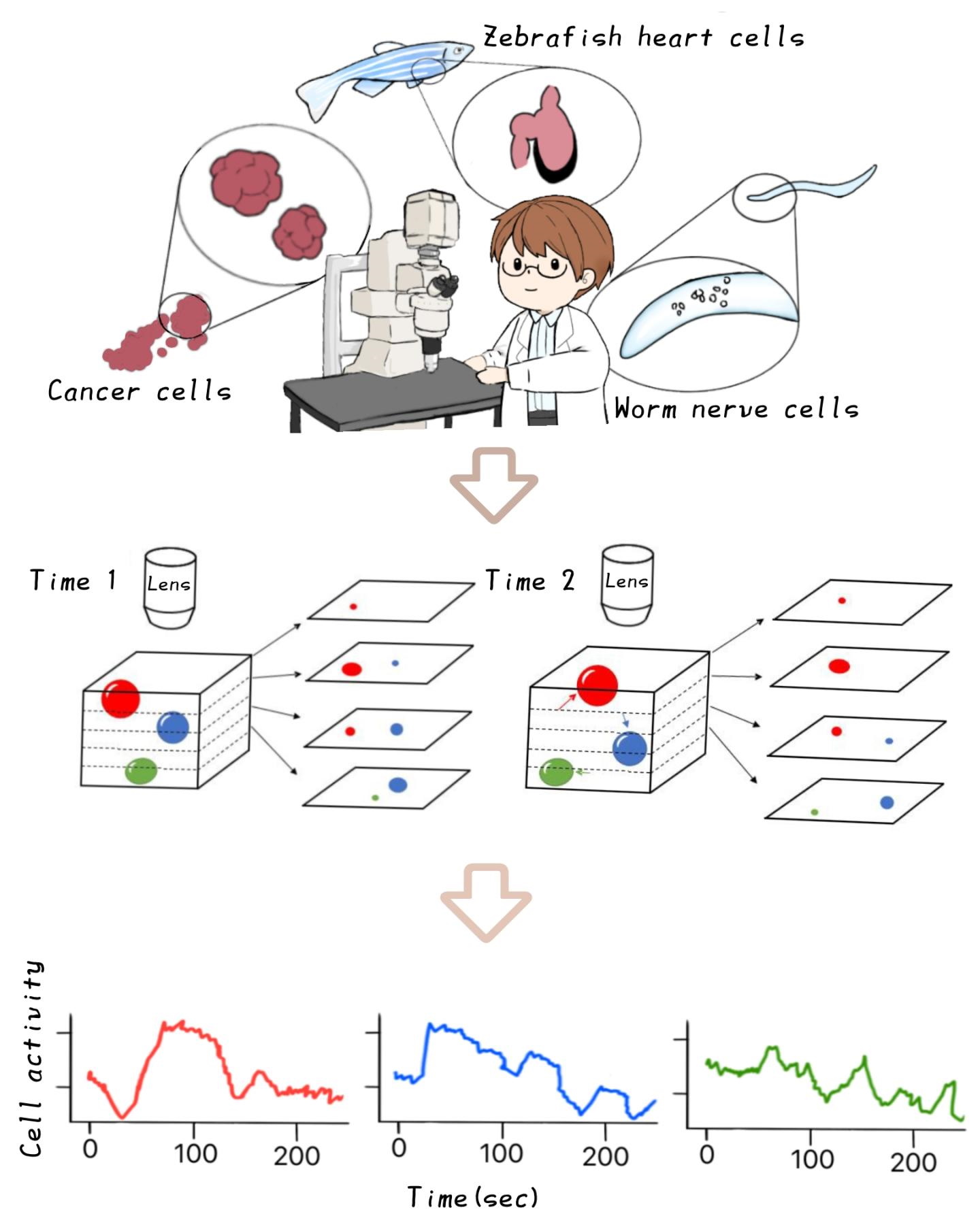
In the medical world, AI is being put to work not on tasks that are not much difficult but are rather tedious for people to do. A good example of this is tracking the activity of individual cells in microscopy images. It’s not a superhuman task to look at a few hundred frames spanning several depths of a petri dish and track the movements of cells, but that doesn’t mean grad students like doing it.
This software from researchers at Nagoya City University in Japan does it automatically using image analysis and the capability (much improved in recent years) of understanding objects over a period of time rather than just in individual frames. Read the paper here, and check out the extremely cute illustration showing off the tech at right … more research organizations should hire professional artists.
This process is similar to that of tracking moles and other skin features on people at risk for melanoma. While they might see a dermatologist every year or so to find out whether a given spot seems sketchy, the rest of the time they must track their own moles and freckles in other ways. That’s hard when they’re in places like one’s back.
MIT researchers have created a machine learning model that can identify and classify potentially dangerous skin pigmentation, flagging the riskiest ones for further inspection. It was trained on more than 20,000 images from 133 patients, and performed very well in a lab setting, catching 90% of the “suspicious pigmented lesions” experts located.

The question of how to get a good shot of your own back isn’t clear yet, but a partner or tripod could help out there, and of course this could be done at a doctor’s office as well before calling in the dermatologist. You can read the paper in Science Translational Medicine.
Interestingly, here’s one situation where researchers opted not to use computer vision — spotting cows (and elk) from space to track their movements. Ten undergrads manually highlighted 31,000 cows … you can see why some labs opt to train a cow-spotting (or sea cow-spotting) AI instead.
A similar task loathed by photographers is watching for “hot pixels,” where a single pixel in a camera’s sensor or image processing pipeline shows up as far brighter than the rest. This can be fixed easily in post-processing, of course, but it would be better if it could be eliminated entirely. Samsung published a paper that proposes exactly that, and on a scale that looks like a photographer’s worst nightmare.
Spotting these hot pixels isn’t a particularly challenging task — they’re very distinctive — but that doesn’t mean it’s easy to build a machine learning process like this into the existing pipeline. However, once an approach is proven to be effective, work can progress to efficient implementation on hardware. The model created by Samsung missed only a fraction of a percent of artificial hot pixels, but also had a pretty high false positive rate in high-contrast regions, so there’s still work to be done.
Not all patterns can afford to be picked up after the fact. Seismic activity, for instance, may be scrutinized for the possibility that it might lead to landslides or debris flow — the latter of which is the idea behind this system from ETH Zurich.
An area in Switzerland subject to dangerous debris flows (like a chunky, extra-dangerous mudslide) has been monitored for more than 10 years, but researchers were unhappy with the short time frame of the warnings it produced — in cases of natural disaster, every second counts. They installed seismometers, but had to build a machine learning model that could distinguish the characteristic vibrations of debris flow from the ordinary seismic motion produced in a mountainous area.
Trained on signals from previous flows, the system detected every one of 13 debris flows that occurred in the summer of 2020, and provided more than 20 minutes’ improvement in warning for those downstream. Now they’re looking at whether this model can be generalized to detect flows in other high risk areas. You can read the paper here.

After a disaster, there is almost always a secondary crisis of information, since communications networks are frequently down or spiking in usage. Social media, in particular, tends to be flooded with messages and media, from “Whoa, did anyone else feel that quake?” to “The power lines are down right outside my building!” Now which of these messages would you want to know about, as an emergency responder?
At Virginia Tech, researchers are looking into quick, accurate assessment of social media content in the context of a disaster with the aim of locating people and places that should be prioritized. The machine learning model they created was trained with bespoke data, human-annotated tweets that let a computer make a preliminary assessment of things that should be looked at.
And at Tohoku University, they have the interesting idea of mining news footage for imagery of areas affected by floods, extrapolating from the footage and other data which buildings will have serious damage. It’s a short jump from there to Instagram and TikTok videos showing the same, but those also present privacy issues.


























Comment