
This week is the Computer Vision and Pattern Recognition conference in Las Vegas, and Google researchers have several accomplishments to present. They’ve taught computer vision systems to detect the most important person in a scene, pick out and track individual body parts and describe what they see in language that leaves nothing to the imagination.
First, let’s consider the ability to find “events and key actors” in video — a collaboration between Google and Stanford. Footage of scenes like basketball games contain dozens or even hundreds of people, but only a few are worth paying attention to. The CV system described in this paper uses a recurrent neural network to create an “attention mask” for every frame, then track relevance of each object as time proceeds.
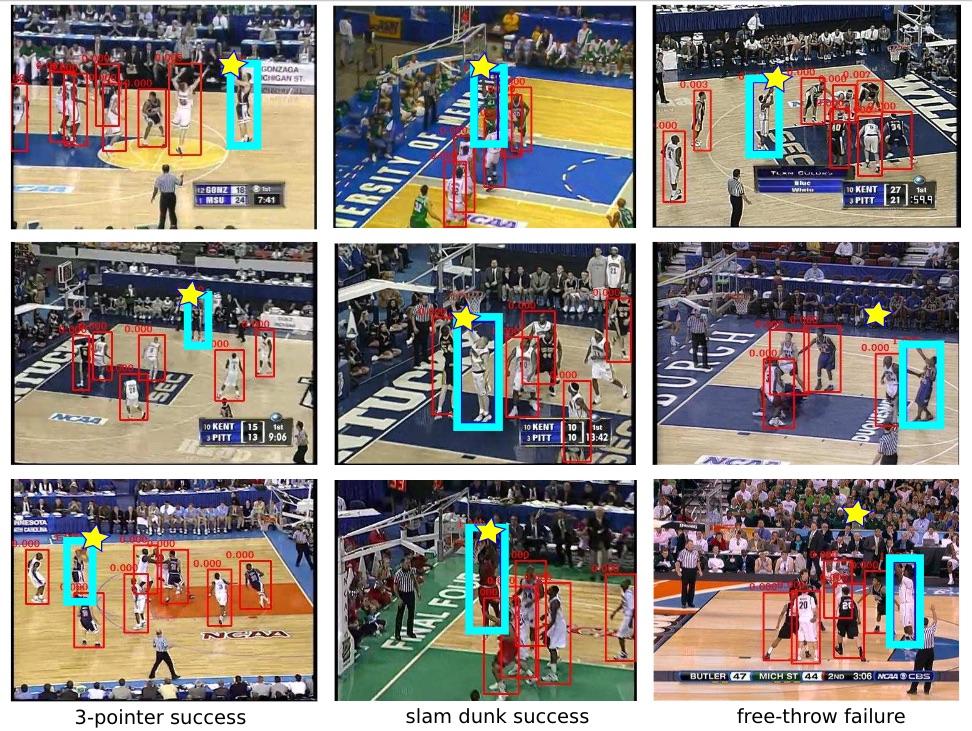
Over time the system is able to pick out not only the most important actor, but potential important actors, and the events with which they are associated. Think of it like this: it could tell that someone going in for a lay-up could be important, but that the most important player there is the one who furnishes the denial. The implications for intelligently sorting through crowded footage (think airports, busy streets) are significant.
Next is a more whimsical paper: Researchers have created a CV system for discovering the legs of tigers. Well… there’s a little more to it than that.
The tigers (and some horses) simply served as “articulated object classes” — essentially, objects with continuously moving parts — for the system to watch and understand. By identifying independently moving parts and their motion and position relative to the rest of the animal, the limbs can be identified frame by frame. The advance here is that the program is capable of making that identification across many videos, even when the animal is moving in different ways.

It’s not that we desperately need data about the front left legs of tigers, but again, the ability to find and track individual parts of an arbitrary person, animal or machine (or tree, or garment, or…) is a powerful one. Imagine being able to scrape video just for tagged animals, or people with phones in their hands or bicycles with panniers. Naturally the surveillance aspect makes for potential creepiness, but academically speaking, the work is fascinating. The paper was a collaboration between the University of Edinburgh and Google.
Last is a new ability for computer vision that may be a bit more practical for everyday use. CV systems have long been able to classify objects they see: a person, a table or surface, a car. But in describing them they may not always be as exact as we’d like. On a table of wine glasses, which one is yours? In a crowd of people, which one is your friend?

This paper, from researchers at Google, UCLA, Oxford and Johns Hopkins, describes a new method by which a computer can specify objects without question of confusion. It combines some basic logic with the powerful systems behind image captioning — the ones that produce something like “a man in red eating ice cream is sitting down” for a photo more or less meeting that description.
The computer looks through the descriptors available for the objects in question and finds a combination of them that, together, can only apply to one object. So among a group of laptops, it could say “the grey laptop that is turned on,” or if several are on, it could add “the grey laptop that is turned on and showing a woman in a blue dress,” or the like.
It’s one of those things people do constantly without thinking about it — of course, we can also point — but that is in fact quite difficult for computers. Being able to describe something to you accurately is useful, of course, but it goes the other way: you may some day say to your robot butler “grab me the amber ale that’s behind the tomatoes.”
Naturally, all three of these papers (and more among the many Google is presenting) use deep learning and/or some sort of neural network — it’s almost a given in computer vision research these days, since they have gotten so much more powerful, flexible and easy to deploy. For the specifics of each network, however, consult the paper in question.


























Comment