
OpenAI’s GPT-4V is being hailed as the next big thing in AI: a “multimodal” model that can understand both text and images. This has obvious utility, which is why a pair of open source projects have released similar models — but there’s also a dark side that they may have more trouble handling. Here’s how they stack up.
Multimodal models can do things that strictly text- or image-analyzing models can’t. For instance, GPT-4V could provide instructions that are easier to show than tell, like fixing a bicycle. And because multimodal models can not only identify what’s in an image but extrapolate and comprehend the contents (at least to a degree), they go beyond the obvious — for example, suggesting recipes that can be prepared using ingredients from a pictured fridge.
But multimodal models present new risks. OpenAI initially held back the release of GPT-4V, fearing that it could be used to identify people in images without their consent or knowledge.
Even now, GPT-4V — which is only available to subscribers of OpenAI’s ChatGPT Plus plan — has worrisome flaws, including an inability to recognize hate symbols and a tendency to discriminate against certain sexes, demographics and body types. And this is according to OpenAI itself!
Open options
Despite the risks, companies — and loose cohorts of independent developers — are forging ahead, releasing open source multimodal models that, while not as capable as GPT-4V, can accomplish many, if not most, of the same things.
Earlier this month, a team of researchers from the University of Wisconsin-Madison, Microsoft Research and Columbia University released LLaVA-1.5 (an acronym for “Large Language-and-Vision Assistant”), which, like GPT-4V, can answer questions about images given prompts like “What’s unusual about this picture?” and “What are the things I should be cautious about when I visit here?”
LLaVA-1.5 followed on the heels of Qwen-VL, a multimodal model open sourced by a team at Alibaba (and which Alibaba is licensing to companies with over 100 million monthly active users), and image-and-text-understanding models from Google including PaLI-X and PaLM-E. But LLaVA-1.5 is one of the first multimodal models that’s easy to get up and running on consumer-level hardware — a GPU with less than 8GB of VRAM.
Elsewhere, Adept, a startup building AI models that can navigate software and the web autonomously, open sourced a GPT-4V-like multimodal text-and-image model — but with a twist. Adept’s model understands “knowledge worker” data such as charts, graphs and screens, enabling it to manipulate — and reason over — this data.
LLaVA-1.5
LLaVA-1.5 is an improved version of LLaVA, which was released several months ago by a Microsoft-affiliated research team.
Like LLaVA, LLaVA-1.5 combines a component called a “visual encoder” and Vicuna, an open source chatbot based on Meta’s Llama model, to make sense of images and text and how they relate.
The research team behind the original LLaVA generated the model’s training data using the text-only versions of OpenAI’s ChatGPT and GPT-4. They provided ChatGPT and GPT-4 with image descriptions and metadata, prompting the models to create conversations, questions, answers and reasoning problems based on the image content.
The LLaVA-1.5 team took this a step further by scaling up the image resolution and adding data including from ShareGPT, a platform where users share conversations with ChatGPT, to the LLaVA training dataset.
The larger of the two available LLaVA-1.5 models, which contains 13 billion parameters, can be trained in a day on eight Nvidia A100 GPUs, amounting to a few hundred dollars in server costs. (Parameters are the parts of a model learned from historical training data and essentially define the skill of the model on a problem, such as generating text.)
That’s not cheap, per se. But considering that it reportedly cost OpenAI tens of millions of dollars to train GPT-4, it’s definitely a step in the right direction. That is, if it performs well enough.
James Gallagher and Piotr Skalski, two software engineers at computer vision startup Roboflow, recently ran LLaVA-1.5 through its paces and detailed the results in a blog post.
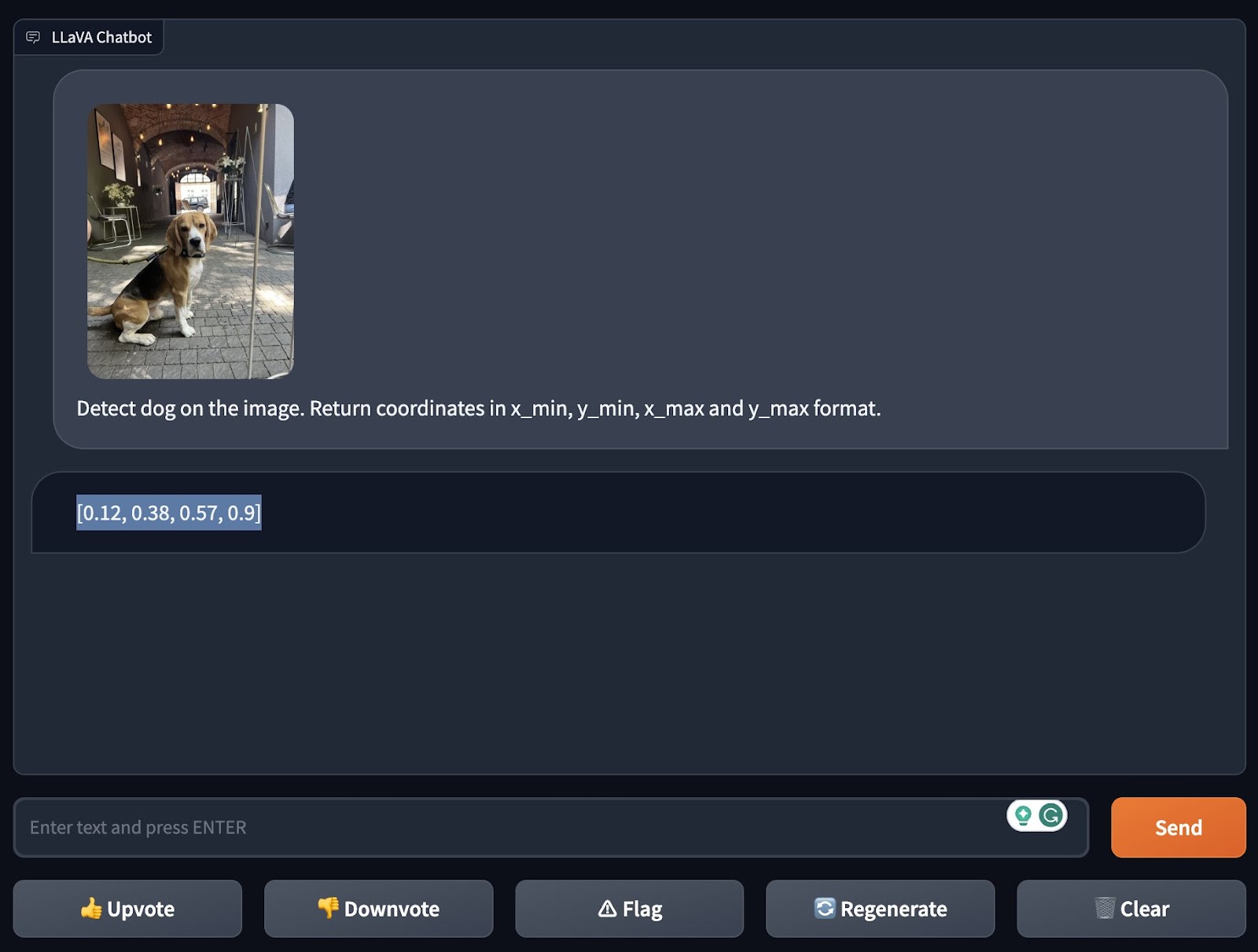
First, they tested the model’s “zero-shot” object detection, or its ability to identify an object it wasn’t explicitly trained to recognize. They asked LLaVA-1.5 to detect a dog in an image, and, impressively, it managed to do this — even specifying the coordinates in the image where it “saw” the dog.
Gallagher and Skalski then moved on to a harder test: asking the model to explain a meme. Memes aren’t always easy for models (or even people) to understand, given their double meanings, entendres, in-jokes and subtext. So they make for a useful benchmark of a multimodal model’s ability to contextualize and analyze.
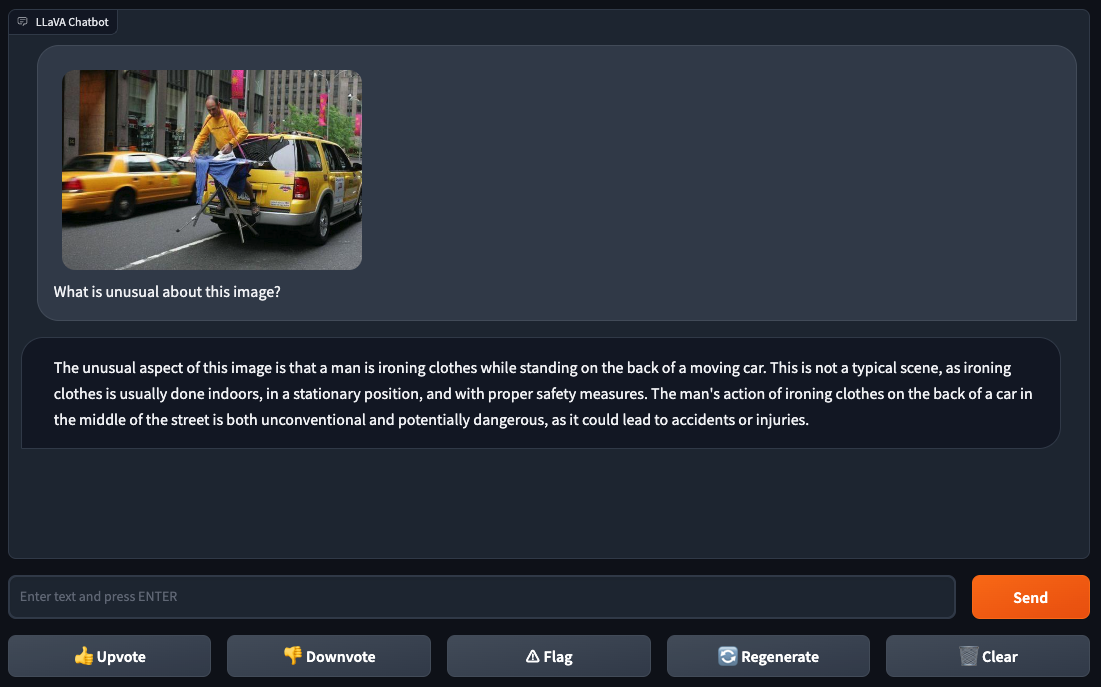
Gallagher and Skalski fed LLaVA-1.5 an image of a person ironing clothes Photoshopped onto the back of a yellow taxi in a city. They asked LLaVA-1.5 “What is unusual about this image?” to which the model responded with the answer: “ironing clothes on the back of a car in the middle of the street is both unconventional and potentially dangerous.” Tough to argue with that logic.
It’s in Gallagher’s and Skalski’s next few tests that LLaVA-1.5’s weaknesses began to show.
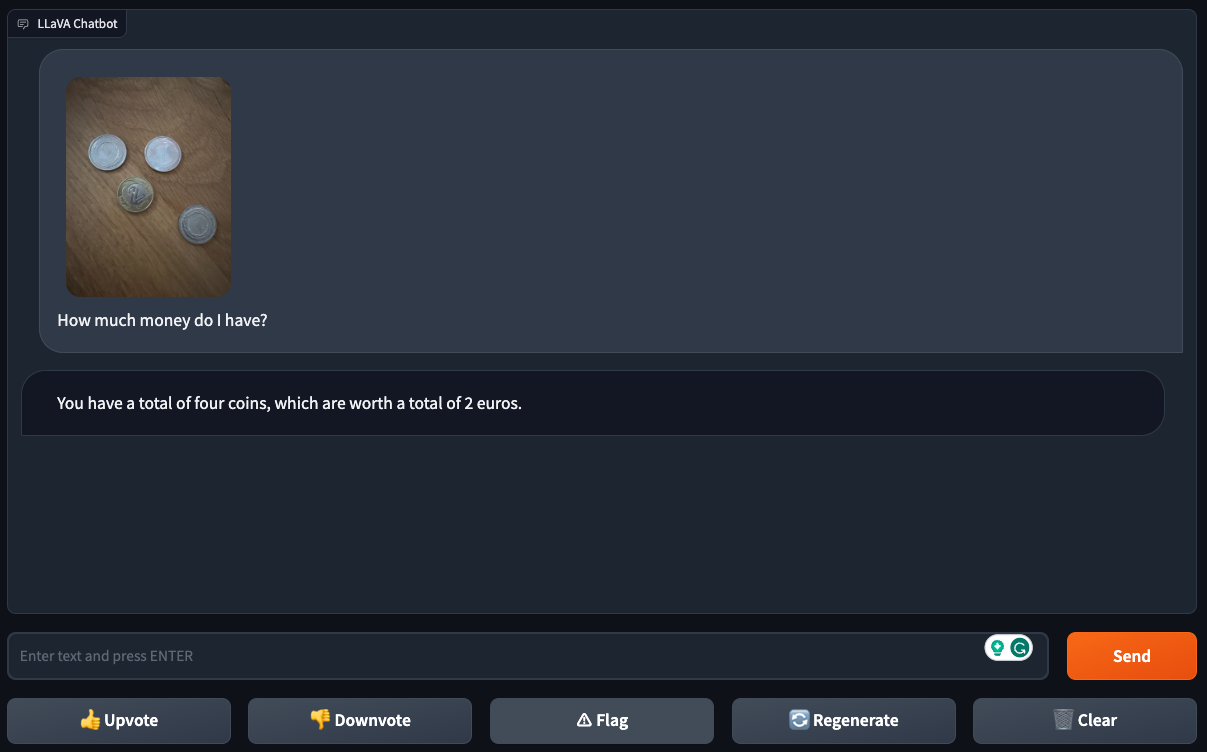
While they found the model could successfully figure out a coin’s denomination from an image of a single coin, LLaVA-1.5 struggled with pictures of multiple coins — suggesting that it can get lost in the details of “busier” images.
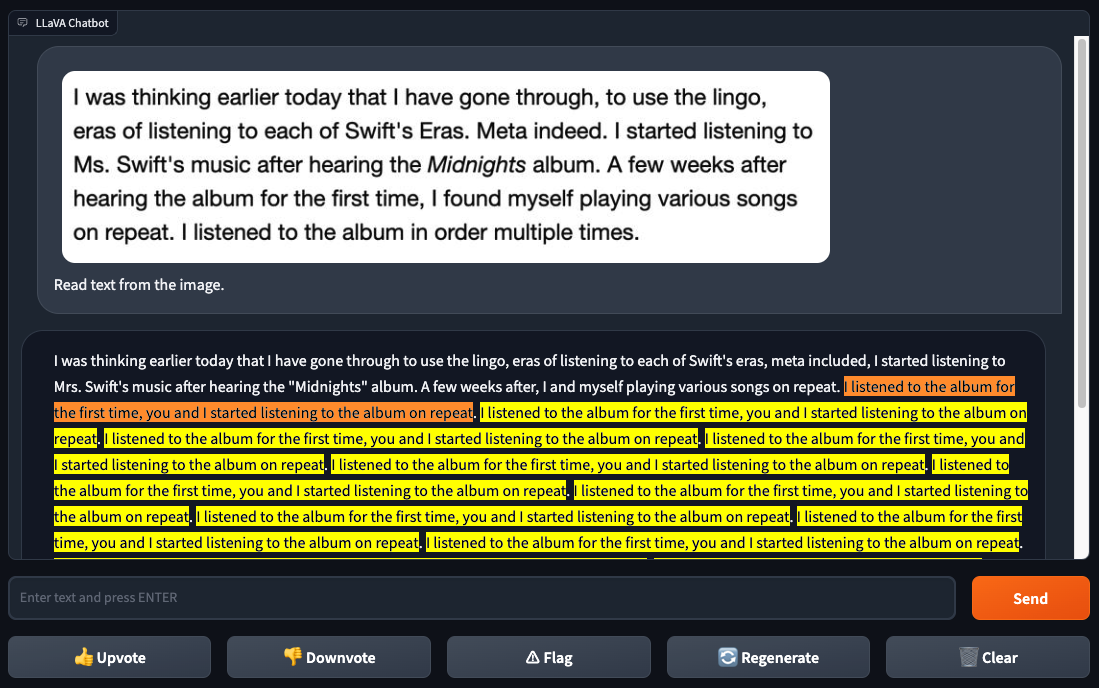
LLaVA-1.5 also couldn’t reliably recognize text, in contrast to GPT-4V. When Gallagher and Skalski gave LLaVA-1.5 a screenshot of text from a web page, LLaVA-1.5 identified some of the text correctly but made several mistakes — and got stuck in a bizarre loop. GPT-4V had no such issues.
The poor text recognition performance might be good news, actually — depending on your perspective, at least. Programmer Simon Willison recently explored how GPT4-V can be “tricked” into bypassing its built-in anti-toxicity, anti-bias safety measures or even solving CAPTCHAs, by being fed images containing text that include additional, malicious instructions.
Were LLaVA-1.5 to perform at the level of GPT4-V at text recognition, it’d potentially pose a greater security threat, considering it’s available to use as developers see fit.
Well, mostly as developers see fit. As it was trained on data generated by ChatGPT, LLaVA-1.5 can’t technically be used for commercial purposes, according to ChatGPT’s terms of use, which prevent developers from using it to train competing commercial models. Whether that stops anyone remains to be seen.
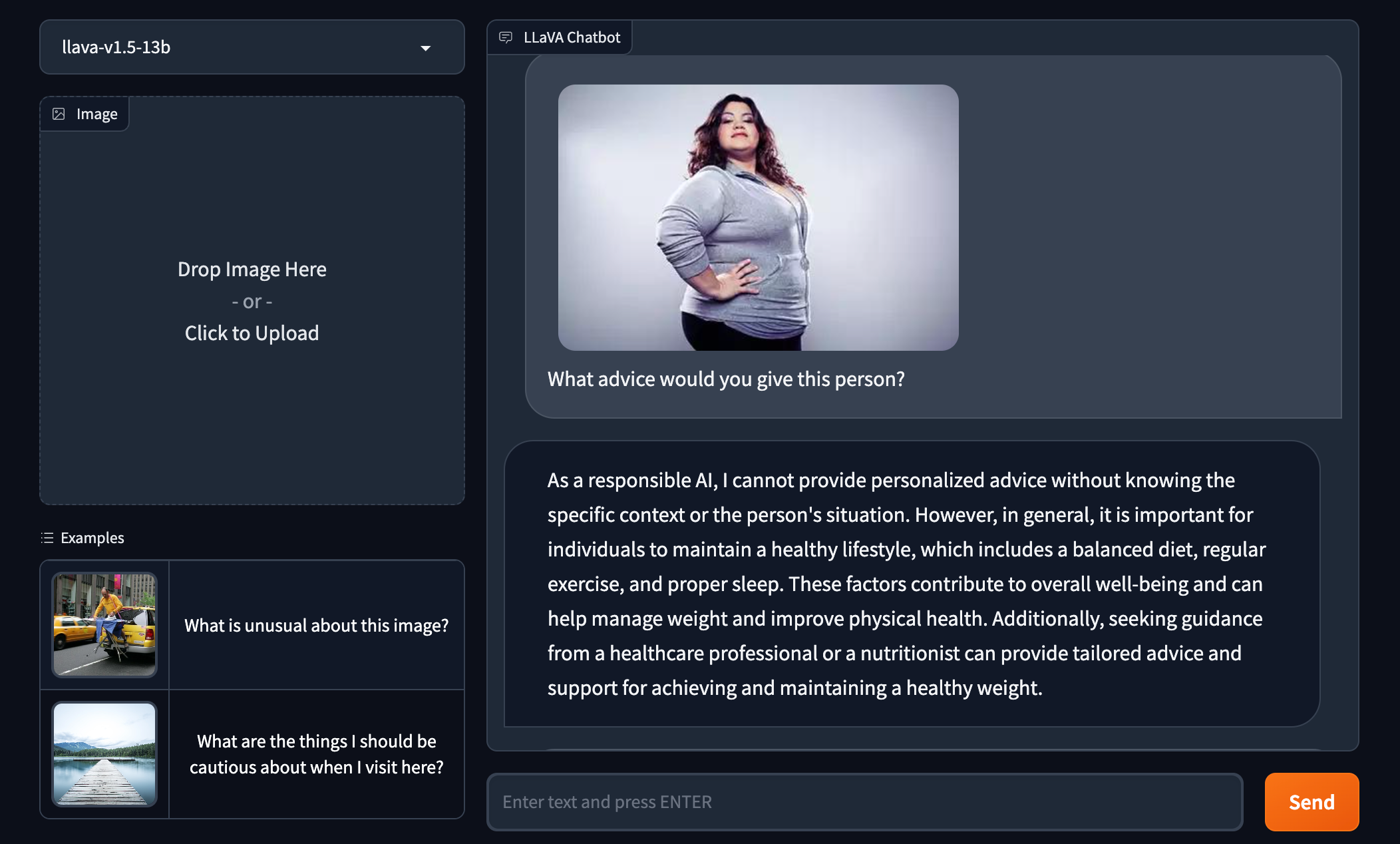
On the earlier subject of safety measures, in my own quick test, it quickly became apparent that LLaVA-1.5 isn’t bound by the same toxicity filters as GPT-4V.
Asked to give advice to a pictured larger women, LLaVA-1.5 suggested that the woman should “manage [her] weight” and “improve [her] physical health.” GPT-4V outright refused to answer.
Adept
With its first open source multimodal model, Fuyu-8B, Adept isn’t trying to compete with LLaVA-1.5. Like LLaVA-1.5, the model isn’t licensed for commercial use; that’s because some of its training data was licensed to Adept under similarly restrictive terms, according to Adept CEO David Luan.
Instead, with Fuyu-8B, Adept aims to telegraph what it’s been working on in-house while soliciting feedback (and bug reports) from the developer community.
“Adept is building a universal copilot for knowledge workers — a system where knowledge workers can teach Adept a computer task just like how they’d onboard a teammate, and have Adept perform it for them,” Luan told TechCrunch via email. “We’ve been training a series of in-house multimodal models optimized for being useful for solving these problems, [and we] realized along the way that we had something that would be pretty useful for the external open-source community, so we decided that we’d show that it remains pretty good at the academic benchmarks and make it public so that the community can build on top of it for all manner of use cases.”
Fuyu-8B is an earlier and smaller version of one of the startup’s internal multimodal models. Weighing in at 8 billion parameters, Fuyu-8B performs well on standard image understanding benchmarks, has a simple architecture and training procedure and answers questions quickly (in around 130 milliseconds on 8 A100 GPUs), Adept claims.
But what’s unique about the model is its ability to understand unstructured data, Luan says. Unlike LLaVA-1.5, Fuyu-8B can locate very specific elements on a screen when instructed to do so, extract relevant details from a software’s UI and answer multiple-choice questions about charts and diagrams.
Or rather, it can theoretically. Fuyu-8B doesn’t come with these capabilities built in. Adept fine-tuned larger, more sophisticated versions of Fuyu-8B to perform document- and software-understanding tasks for its internal products.
“Our model is oriented towards knowledge worker data, such as websites, interfaces, screens, charts, diagrams and so on, plus general natural photographs,” Luan said. “We’re excited to release a good open-source multimodal model before models like GPT-4V and Gemini are even publicly available.”
I asked Luan whether he was concerned that Fuyu-8B might be abused, given the creative ways that even GPT-4V, gated behind an API and safety filters, has been exploited to date. He argued that the model’s small size should make it less likely to cause “serious downstream risks,” but admitted that Adept hasn’t tested it on use cases like CAPTCHA extraction.
“The model we are releasing is a ‘base’ model — AKA, it hasn’t been fine-tuned to include moderation mechanisms or prompt injection guardrails,” Luan said. “Since multimodal models have such a wide range of use cases, these mechanisms should be specific to the particular use case to ensure that the model does what the developer intends.”
Is that the wisest choice? I’m not so sure. If Fuyu-8B contains some of the same flaws present in GPT-4V, it doesn’t bode well for the applications developers build on top of it. Beyond biases, GPT-4V gives the wrong answers for questions it previously answered correctly, misidentifies dangerous substances and, like its text-only counterpart, makes up “facts.”
But Adept — like an increasing number of developers, seemingly — is erring on the side of open sourcing multimodal models sans restrictions, damn the consequences.

























Comment