
In a perfect world, Twitter’s Head of Infrastructure and Operations Mazdak Hashemi can walk over to a data center and kick out a power cable to a server, and the service will continue to run fine. He’s not going to do that just yet, but he and his team have been devising ways to simulate those sorts of failures within Twitter and ensure that the service remains up and running.
“If you look at our scale there could be a number of failures to our infrastructure. You could have a power failure, a rack failure, bad configs or a network failure at all times,” Hashemi said. “So we decided by saying other than getting surprised, what’s the best way to check some failures.”
The engineering team has basically devised a series of tests that, in a controlled way, inject failures into the system to simulate those kinds of events. The goal is to make sure that everyone is prepared in the case that those server racks go offline, or someone accidentally kicks a power cable and sends a whole node offline.
Twitter will inject small failures into the service to test how it responds within production and infrastructure systems. It monitors the health of the system for Twitter’s services to ensure there are no site-wide incidents and rolls back those failure conditions, and there are a series of tools that keep the team notified on an ongoing basis throughout the test. The goal is to monitor for things like power loss to the company’s server clusters, or network loss when pushing new configurations.
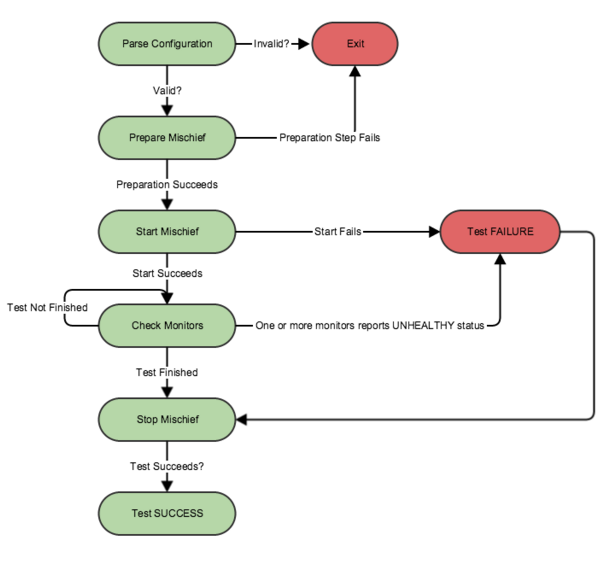
All this together is part of a series of tools the company has implemented to make sure that Twitter, in any scenario, does’t curl up into a ball and start crying. The Fail Whale used to be an ever-present part of the company’s service, but today much of the company’s efforts are centered around ensuring that it remains dead.
One hope is that, eventually, the tool will become open source, which will allow the community to discover new use cases for it or even improve it. “The difference between Twitter and some other companies — everything is real time,” Hashemi said. “There’s no, ‘hey you go prep for Black Friday, you prep for the Super Bowl.’ Obviously when you’re aware of certain days coming, you do some preparation, but for us every day could be a Black Friday. Every day could be a Super Bowl. It’s sort of unknown. Anything can happen across the globe”
That’s not to say that’s the only thing that the testing involves. There’s always an opportunity to walk over to a server rack and yank out a few network cables to test that the service continues to run in the case of a rack going offline. The goal of all these tests is to ensure that each team — which includes a site reliability engineer — is prepared for a real-world disaster scenario, no matter what scale.
“Ultimately I want to get to a place where I walk to a data center and unplug a cable and say what’s the impact,” Hashemi said. “Would I do it today? Maybe. But I probably don’t want to do it yet. In some areas I feel very comfortable, but if you go to the higher layer, the impact would be higher. But the ultimate test for our team is that we walk in and start randomly unplugging things and see what happens.”


























Comment