As DevOps takes off, site reliability engineers are flying high


Image Credits: Westend61 / Getty Images
Each year, LinkedIn tracks the top emerging jobs and roles in the U.S.
The top four roles of 2020 — AI specialist, robotics engineer, data scientist and full-stack engineer — are all closely affiliated with driving forward technological innovation. Today, we’d like to recognize number five on the list, without which innovation in any domain would not be possible: the site reliability engineer (SRE).
We see the emergence of site reliability engineers not as a new trend, but one closely coupled with the theme of DevOps over the last decade. As coined, it was supposed to be something that you do and not something that you are. However, as time has passed, DevOps has found its way into roles and titles, often replacing “application production support” or “production engineering.”
What we are seeing now and predicting into the future is the rise of site reliability engineer as a title relating to the practice of DevOps and better describing the work to be done. At the time of our writing, there are more than 9,000 open roles for SREs on LinkedIn, a number that is only growing.
Software focused on helping engineers ensure reliability and uptime isn’t a new phenomenon, and the market has supported numerous billion-plus dollar exits, including companies like AppDynamics and Datadog. Nonetheless, we see an impending tipping point in tooling catering to the SRE persona across their entire workflow. We’ll discuss why the market is taking off and share our view of the landscape and the many inspired founders building technology to transform the practice of reliability — a foundational block for innovation across every industry.
Why now?
- The service is the product: As more applications have moved to being delivered as a service, moving from the realm of IT to SaaS, the service itself has become the product. Anything delivered as a service must keep an eye toward the old, basic concept of customer service. This shift began at the application layer (e.g., Salesforce, Workday, ServiceNow) and over time has spread to infrastructure layer software (e.g., Datadog, HashiCorp) and has even impacted on-prem software. As Grant Miller, CEO at Replicated, put it further, “Traditional on-prem software vendors have transitioned away from delivering binary executables (.jar, .war, .exe, etc.) and expecting their customers to set up the necessary components manually. Now, vendors are leveraging Kubernetes as the substrate to deliver a much more automated and reliable experience to their customers, and redefining what ‘on-prem software’ traditionally meant.”
- Rise of Kubernetes and ensuing service sprawl: Independent of applications shifting to being consumed as a service, a given company’s proprietary lines of code are being split up into tens and hundreds of complex components. No surprise here for anyone reading this: Kubernetes and microservices have been a blessing in some ways and a curse of complexity in others.
- Necessary tooling is in place: We think of the SRE landscape along a chronology: pre-incident, incident and post-incident. In 2020, many companies have invested in tools to help identify and escalate when a problem arises, including monitoring and logging (e.g., Datadog), alerting and incident response (e.g., PagerDuty), and issue tracking (e.g., Jira). With these tools firmly in place, the focus can shift to mitigating incidents before they happen and increasing resilience after an incident occurs.
- Increased executive attention: Reliability has big implications for operating margins for software service vendors: too high a standard comes with expensive cloud costs, too low results in unmet customer expectations. As Kit Merker of Nobl9 put it, “If someone has a great experience with your business, they might tell one person. If that same person had a bad experience, they’ll tell everyone he or she knows. Missing a chance to deliver value to a customer via a digital channel should be a nonstarter. That said, not all downtime is created equal so understanding when and where you can limit your investments in reliability have bottom-line impacts. Balance is the key to delivering reliable features faster.” Consequently, reliability has been escalated to the C-level and entered the board room.
- Ever-increasing consumer expectations: Our lives now depend on reliable digital services (even more so than they already did pre-COVID-19) and consumer expectations of these services, be they consumer-focused or business-focused, are only on the rise. For companies where dollars = downtime (e.g., media, e-commerce, finance), the imperative is even greater.
- Zeitgeist: Just as DevOps became “a thing,” we see the beginnings of that with SRE entering the vernacular if for no other reason than individuals doing engineering work want to be titled as such. The LinkedIn data above confirms our early suspicions here.
The landscape
Accidents happen, incidents happen. No organization is without their share, and most organizations have accepted infrequent incidents as normal operating procedure within the framework of stated reliability goals. Tooling in the form of monitoring, tracking and alerting are mature to the point of ubiquity in forward-leaning organizations, with even a second wave of innovation in companies like Grafana, Chronosphere and Honeycomb. The innovation around this area occurs as underlying architectures shift, for example from on-premise to monolithic cloud to microservices (MSA).
On either side of the incident spectrum, innovation is more greenfield.

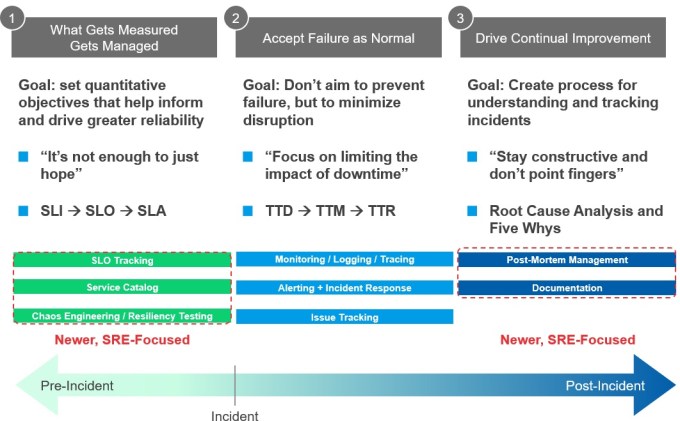
Image Credits: Jason Kong (opens in a new window)
Pre-incident: The Google engineering organization is often considered part and parcel with the SRE concept and tooling. Well deserved, because they built functionality, nomenclature and culture around the idea of determining in advance what ought to be measured. Google also took a customer-centric lens, tying to the consumer’s perception of results versus the metrics and vitals in a vacuum.
We can’t all be Google, so luckily many other entrepreneurs and vendors have stepped up to the plate. We see two key areas of innovation:
- SLO Tracking: This boils down to [X should be true], [Y portion of the time], [or else…?] — equating to [service level indicators], [service level objectives] and [service level agreements]. This requires a customer orientation. For SLOs to become useful they must take the myriad metrics, focus on the ones critical to the business and fit that into the dev/SRE/business feedback loop. Operating with SLOs in mind allows for a business-oriented decision of when to invest in resiliency versus when to invest in new features. If only “both” were always an option. Companies like Nobl9 are building SLO tooling that considers reliability metrics across multiple monitoring sources and connects them to business KPIs, all within modern GitOps workflows with SLOs-as-code.
- Service Catalogs: As organizations scale and services proliferate, it would be impossible for an individual to know each service, the service owner, where it’s running, current version, dependencies, and the relationships amongst, well, all of them. Companies like effx have emerged to help organizations put the structure in place to build a catalog of components, track service ownership and ultimately ensure services are healthy.
Post-incident:
- Post-mortem: ”Toil” may not be a conventionally bad four-letter word but for an engineer it seems to be the nemesis. Once or twice, fine, but >2x and that’s reason enough to automate. Layering on the business impact of that single or double incident is where the SLO tradeoff comes into play — pay down technical debt or take more risk? Slack is certainly an excellent ad hoc solution that won’t go away but companies like Blameless and FireHydrant are trying to take it one step further: Can you automate workflows and create behavior change within organizations in order to institutionalize “context,” quantify tradeoffs, and ultimately improve resilience? This category has as much to do with the people as it does with the processes.


Image Credits: Jason Kong (opens in a new window)
We anticipate hearing a lot more about end-to-end SRE platforms and look forward to seeing the space take shape. We predict that next-generation monitoring, logging, tracing and incident management platforms that capture core architectural changes will continue to grow in popularity and gain share, maybe faster than the products and services going after the 0–>1 budget versus replacement budget.
The lines are not as firmly delineated as suggested here and product/platform expansion is likely, as is consolidation and M&A. The software delivery supply chain has seen tie-ups and we may be in the midst of a rebundling on this continuum too.
None of this innovation is possible without the organizational and culture change required within each organization. It seems inevitable, just as DevOps and the move to continuous integration, continuous delivery eventually became inevitable. We’ll be watching closely.









