Google’s Transformer solves a tricky problem in machine translation


Image Credits: Bryce Durbin / TechCrunch
Machine learning has turned out to be a very useful tool for translation, but it has a few weak spots. The tendency of translation models to do their work word by word is one of those, and can lead to serious errors. Google details the nature of this problem, and their solution to it, in an interesting post on its Research blog.
The problem is explained well by
river.
Obviously “bank” means something different in each sentence, but an algorithm chewing its way through might very easily pick the wrong one — since it doesn’t know which “bank” is the right one until it gets to the end of the sentence. This kind of ambiguity is everywhere once you start looking for it.
Me, I would just rewrite the sentence (Strunk and White warned about this), but of course that’s not an option for a translation system. And it would be very inefficient to modify the neural networks to basically translate the whole sentence to see if there’s anything weird going on, then try again if there is.
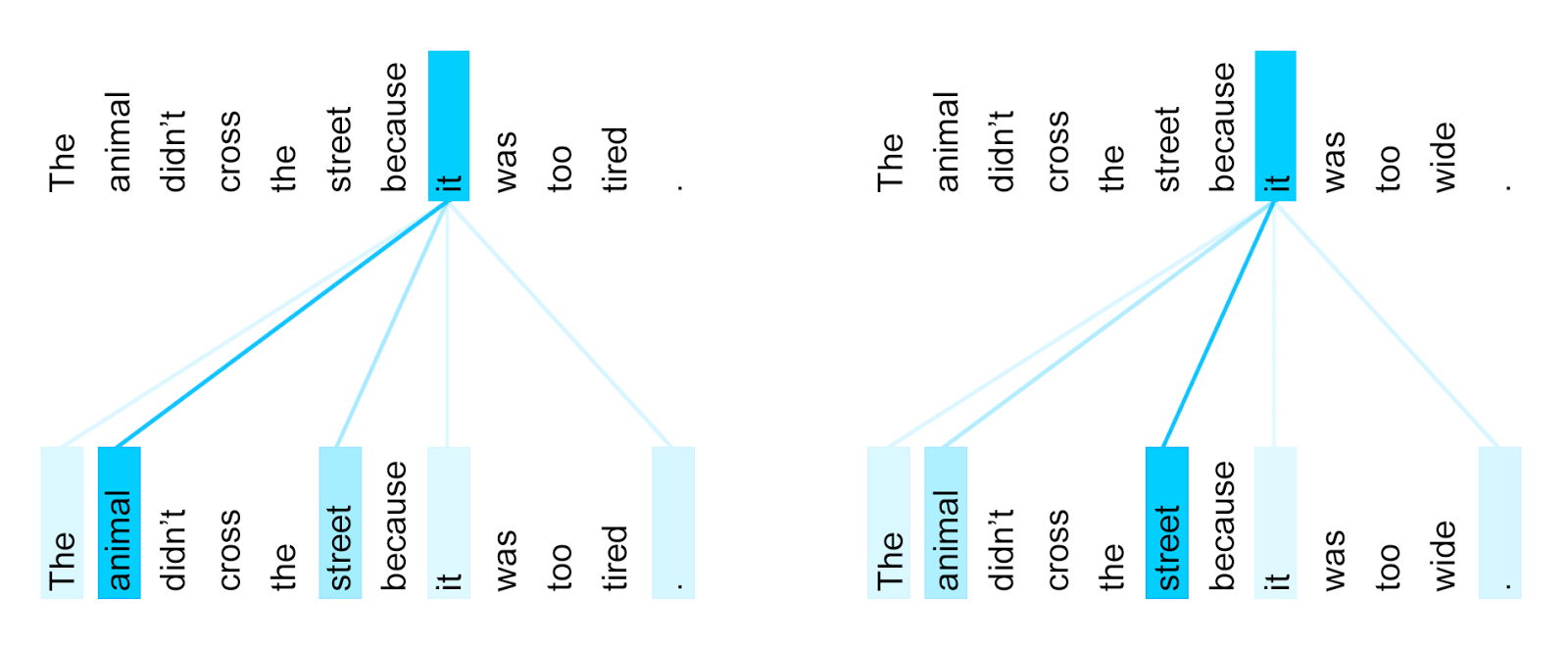
Google’s solution is what’s called an attention mechanism, built into a system it calls Transformer. It compares each word to every other word in the sentence to see if any of them will affect one another in some key way — to see whether “he” or “she” is speaking, for instance, or whether a word like “bank” is meant in a particular way.
When the translated sentence is being constructed, the attention mechanism compares each word as it is appended to every other one. This gif illustrates the whole process. Well, kind of.
![]()
An interesting side effect of Google’s approach is that it gives a window into the system’s logic: because Transformer gives each word a score in relation to every other word, you can see what words it thinks are related, or potentially related: