WTF is machine learning?


Image Credits: Bryce Durbin
While the number of headlines about machine learning might lead one to think that we just discovered something profoundly new, the reality is that the technology is nearly as old as computing.
It’s no coincidence that Alan Turing, one of the most influential computer scientists of all time, started his 1950 treatise on computing with the question “Can machines think?” From our science fiction to our research labs, we have long questioned whether the creation of artificial versions of ourselves will somehow help us uncover the origin of our own consciousness, and more broadly, our role on earth. Unfortunately, the learning curve on AI is really damn steep. By tracing a bit of history, we should hopefully be able to get to the bottom of wtf machine learning really is.
If my big-data is big enough can I create intelligence?
Our first attempts at replicating ourselves involved jamming machines full of information and hoping for the best. Seriously, there was a time when the prevailing theory of consciousness was that it could arise from just a ton of information connected together. Google could be seen by some as the culmination of this vision, but while the company has indexed 30 trillion webpages, I don’t think anyone expects our search engines to start asking us if there is a god.
Rather, the beauty of machine learning is that instead of pretending computers are human and simply feeding them with knowledge, we help computers to reason and then let them generalize what they’ve learned to new information.
While not well understood, neural networks, deep learning, and reinforcement learning are all machine learning. They’re all methods of creating generalized systems that can perform analysis on new data. Put a different way, machine learning is one of many artificial intelligence techniques, and things like neural networks and deep learning are just tools that can be used to build better frameworks with broader applications.
Back in the 50s, our computing power was limited, we didn’t have access to big-data, and our algorithms were rudimentary. This meant that our ability to advance machine learning research was quite limited. However, that didn’t stop people from trying.
Back in 1952, Arthur Samuel made a chess program using a very basic form of AI called alpha beta pruning. This is a method for reducing computational load when working with search trees that represent data, but it’s not always the best strategy for every problem. Even neural networks showed their face in yesteryear with Frank Rosenblatt’s perceptron.
A complex sounding model that you should read about anyway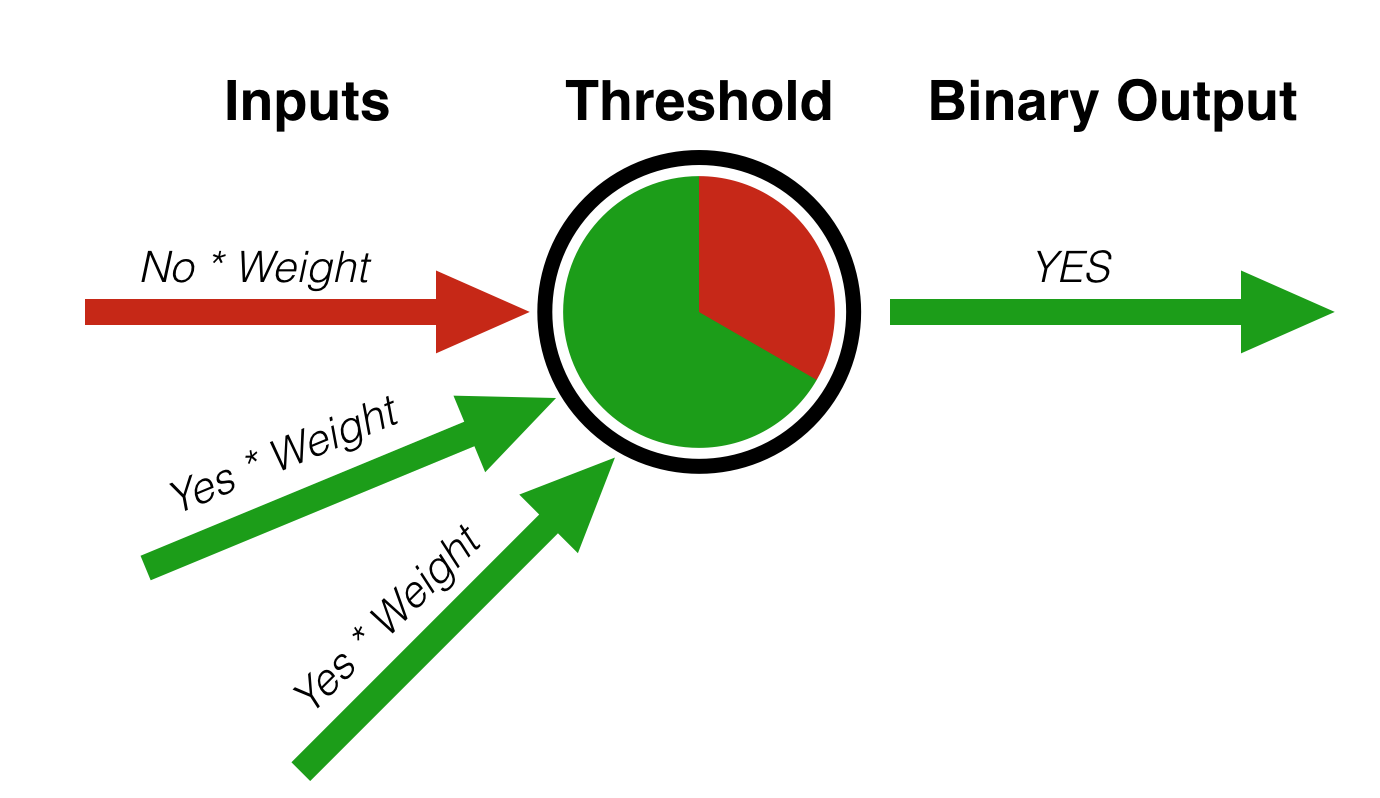

The perceptron was way ahead of its time, leveraging neuroscience to advance machine learning. On paper, the idea looked something like the sketch to the right.
To understand what it’s doing, you first have to understand that most machine learning problems can be broken down into either classification or regression. Classifiers are used to categorize data, while regression models broadly deal with extrapolating out trends to make predictions.
The perceptron is an example of a classifier — it takes a set of data and splits it into multiple sets. In this case, the existence of two traits with respective weights is enough for this object to be classified in the “green” category. Classifiers today separate the spam from your inbox and detect fraud for your bank.
Rosenblatt’s model uses a series of inputs, think features like length, weight, color, and assigns each of them a weight. The model then continuously adjusts the weights until an output is reached that falls within an accepted margin of error.
For example, one could input that the weight of an object that happens to be an apple is 100 grams. The computer doesn’t know it’s an apple, but the perceptron can classify the object as an apple-like-object or a non-apple-like-object by adjusting the classifier’s weights with respect to a known training set of data. Once the classifier has been tuned, it can ideally be reused on a data set it has never been exposed to before to classify unknown objects.
It’s ok, even AI researchers are confused by this stuff


Skipping forward a few decades, advancements in AI have continued to be about replicating the way the mind works rather than simply replicating what we perceive its contents to be. Basic, or “shallow”, neural networks are still in use today, but deep learning has caught on as the next big thing. Deep learning models are neural networks with more layers. A totally reasonable reaction to this incredibly unsatisfying explanation is to ask what I mean by layers.
To understand this, we have to remember that just because we say a computer can organize cats and humans into two different groups, the computer itself doesn’t process the task the same way a human would. Machine learning frameworks take advantage of the idea of abstraction to accomplish tasks.
To a human, faces have eyes. To a computer, faces have pixels that are light and dark that make up some abstraction of lines. Each layer of a deep learning model lets the computer identify another level of abstraction of the same object. Pixels to lines to 2D to 3D geometry.
Despite overwhelming stupidity, computers already passed the Turing test
This fundamental difference in the way humans and computers evaluate the world presents a serious challenge to creating true artificial intelligence. The Turing test was conceptualized to evaluate our progress in AI, but it largely ignores this reality. Turing’s test is a behaviorist test focused on evaluating the ability of computers to emulate human output.
However, mimicry and probabilistic reasoning are, at best, only part of the mystery of intelligence and consciousness. Some believe we successfully passed the Turing test in 2014, when a machine convinced 10 out of 30 scientists that it was human during a five minute keyboard conversation (and yet Siri still tries to search Google for every third thing we ask her).
So should I get my jacket for the AI winter?
Despite progress, scientists and entrepreneurs alike have been quick to over-promise the capabilities of AI. The resulting boom and bust cycles are commonly referred to as AI winters.
We have been able to do some unbelievable things with machine learning, like classify objects in video footage for autonomous cars and predict crop yields with satellite imagery. Long short-term memory is helping our machines deal with time-series for things like sentiment analysis in videos. Reinforcement learning, takes ideas from game theory, and includes a mechanism to assist learning through rewards. Reinforcement learning was a key part of how Alpha Go was able to upset Lee Sodol.
That said, despite all progress, the great secret of machine learning is that while we usually know the inputs and outputs of a given problem, and the explicitly programmed code to act as the intermediary, we can’t always identify how the model is going from input to output. Researchers refer to this challenge as the black box problem of machine learning.
Before getting too discouraged, we must remember that the human brain itself is a black box. We don’t really know how it works and cannot examine it at all levels of abstraction. I would be labeled crazy if I asked you to dissect a brain and point to the memories held within it. However, not being able to understand something isn’t game over, it’s game on.
This post introduced many of the basic concepts underpinning machine learning but leaves plenty on the table for future WTF is pieces. Deep learning, reinforcement learning and neural nets could all stand on their own but hopefully after reading this post you can visualize the field itself and draw connections to many of the companies we cover daily on TechCrunch.
More posts from the WTF is series