Google has long made it possible for its users to run Hadoop — a framework for storing and processing large amounts of data — on its Cloud Platform. Until now, however, the only way to get in and out of Hadoop on Cloud Platform was through Google’s Cloud Storage service. Starting today, however, Google also makes it possible to run Hadoop jobs against data in its BigQuery SQL and Cloud Datastore NoSQL databases.
To do this, Google has launched connectors for these two products that complement the existing Cloud Storage implementation.
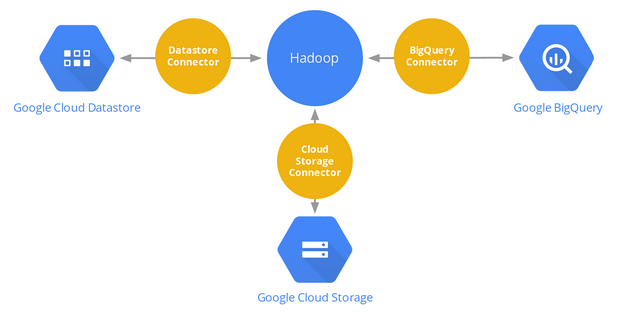
As Google points out, one advantage of this setup is that the connectors allow users to “directly access data stored in Google Cloud Platform’s storage services from Hadoop and other Big Data open source software that use Hadoop’s IO abstractions.” This way, the data can be used by multiple services without duplications.
Google’s announcement comes only a day after Microsoft announced its latest initiatives around big data analytics. Hadoop is a core part of Microsoft’s data services and its Azure cloud computing platform, too.
Both Google and Microsoft (as well as most other Hadoop-based services) abstract away most of the complexities of setting up a Hadoop cluster. Google’s implementation, however, does take a slightly more manual approach than Microsoft’s. For example, users have to run install scripts to get started, but if you’re using Hadoop for big data analysis, that isn’t likely to be a deal breaker and may actually give you a bit more flexibility than other approaches.