It’s not often that you improve on a bit of math that has been around for 200 years. The Fourier transform was first proposed in 1811 by a Frenchman named Joseph Fourier, though it wasn’t until the middle of the 20th century that he was given the credit he deserved. His technique broke down a complex signal into a number of component signals, which could be transmitted or processed separately and then recombined to produce the original in a fairly nondestructive way.
In 1965 the Fourier transform got a boost as James Cooley and John Tukey discovered a way to apply the transform on the fly using a computer. And now, in 2012, another major improvement has been proposed.
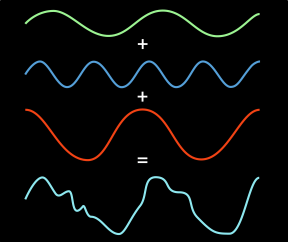
Understanding the Fourier transform isn’t so hard: if you have a piece of music that needs to be transmitted, you can’t send each instrument or frequency separately. So instead, you stack the frequencies on top of each other, and what you get is a single signal, more complicated than any of the single frequencies, but interpretable on the other end. The process of breaking down the complex signal into its component frequencies is achieved by Fourier’s method, and recomposing the original signal from those component frequencies is an inverse Fourier. And it’s not just audio that can be encoded in this way: if you consider pixels to be simply bit values for color and so on, you can express images and video using this method as well. It ends up being rather ubiquitous, actually.
But despite its age and ubiquity, the algorithm is apparently due for another boost, according to researchers at MIT. The digital, “discrete” Fourier transform established in 1965 can apparently be extremely inefficient at times, and the researchers found that for an 8×8 block of values (totaling 64), 57 can be discarded without visibly affecting image quality.
Now, it’s not just a matter of throwing things out. The new technique also changes the way the signal is sliced up into smaller signals, making it easier on the algorithm that needs to choose which pieces are important and which aren’t. And they also snip existing bits of signal down until they contain only the part necessary.
So why is this on TechCrunch? Because it’s research like this that makes things like FaceTime and Spotify possible. And it’s also from work like this that many startups are born. Improvements at the most basic level of signal processing, like this one, can produce repercussions years or decades down the line. The improved algorithm, which has not been named, could improve compression and transmission of compatible signals by as much as 10 times. Will it improve the speed of encoding so your phone will shoot 4K video? Or maybe reduce the bandwidth necessary for audio and video so that it can stream faster and in higher quality? Maybe improve data handling on your wi-fi? Hard to say at the moment, but generally one does not improve on the fundamentals of a field without causing real improvements there.
The paper is by Dina Katabi, Piotr Indyk, and their students Eric Prince and Haitham Hassanieh at MIT’s CSAIL. It has not been published, but you can read it here.