
As if still-image deepfakes aren’t bad enough, we may soon have to contend with generated videos of anyone who dares to put a photo of themselves online: with Animate Anyone, bad actors can puppeteer people better than ever.
The new generative video technique was developed by researchers at Alibaba Group’s Institute for Intelligent Computing. It’s a big step forward from previous image-to-video systems like DisCo and DreamPose, which were impressive all the way back in summer but are now ancient history.
What Animate Anyone can do is not by any means unprecedented, but has passed that difficult space between “janky academic experiment” and “good enough if you don’t look closely.” As we all know, the next stage is just plain “good enough,” where people won’t even bother looking closely because they assume it’s real. That’s where still images and text conversation are currently, wreaking havoc on our sense of reality.
Image-to-video models like this one start by extracting details, like facial feature, patterns and pose, from a reference image like a fashion photo of a model wearing a dress for sale. Then a series of images is created where those details are mapped onto very slightly different poses, which can be motion-captured or themselves extracted from another video.
Previous models showed that this was possible to do, but there were lots of issues. Hallucination was a big problem, as the model has to invent plausible details like how a sleeve or hair might move when a person turns. This leads to a lot of really weird imagery, making the resulting video far from convincing. But the possibility remained, and Animate Anyone is much improved, though still far from perfect.
The technical specifics of the new model are beyond most, but the paper emphasizes a new intermediate step that “enables the model to comprehensively learn the relationship with the reference image in a consistent feature space, which significantly contributes to the improvement of appearance details preservation.” By improving the retention of basic and fine details, generated images down the line have a stronger ground truth to work with and turn out a lot better.
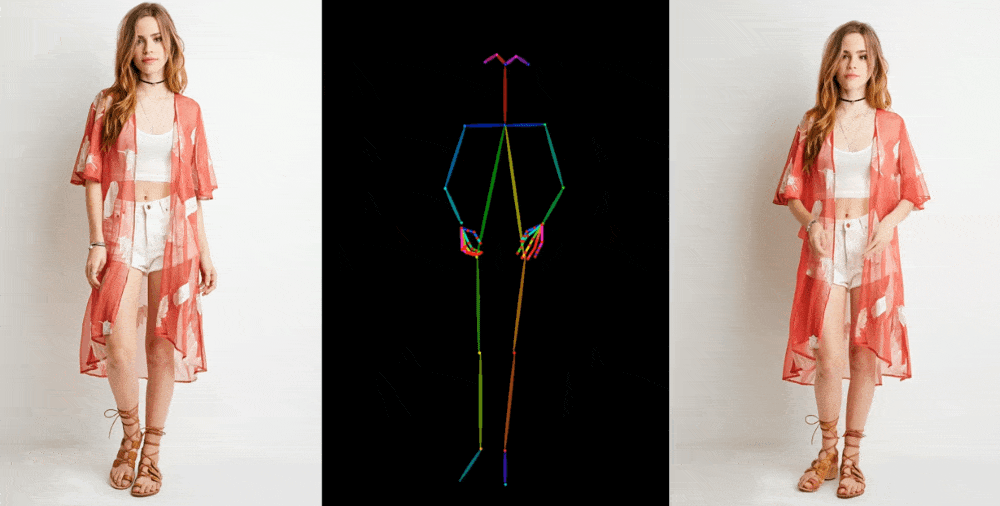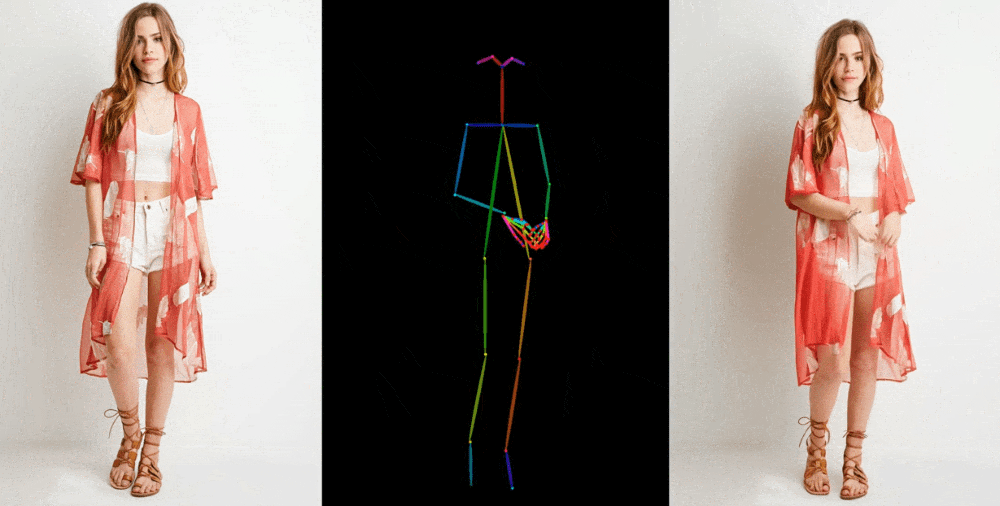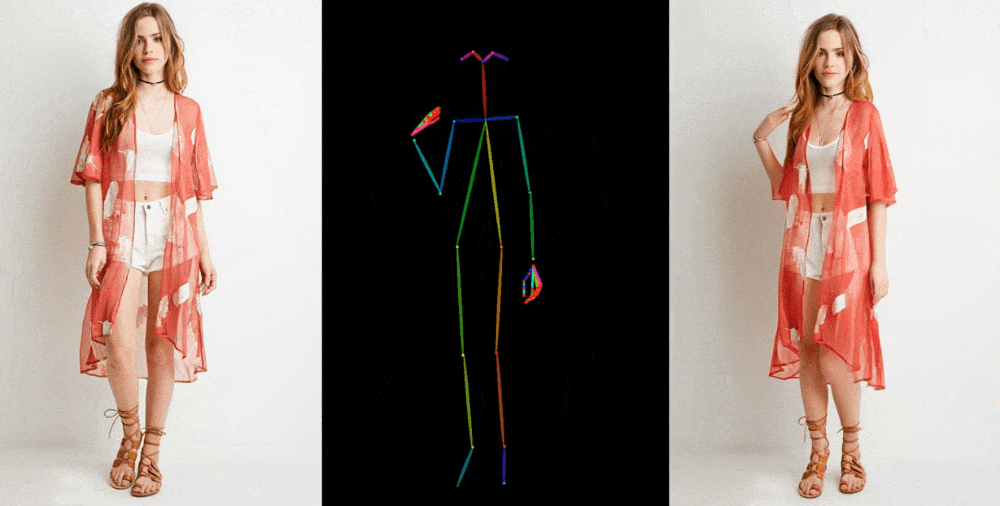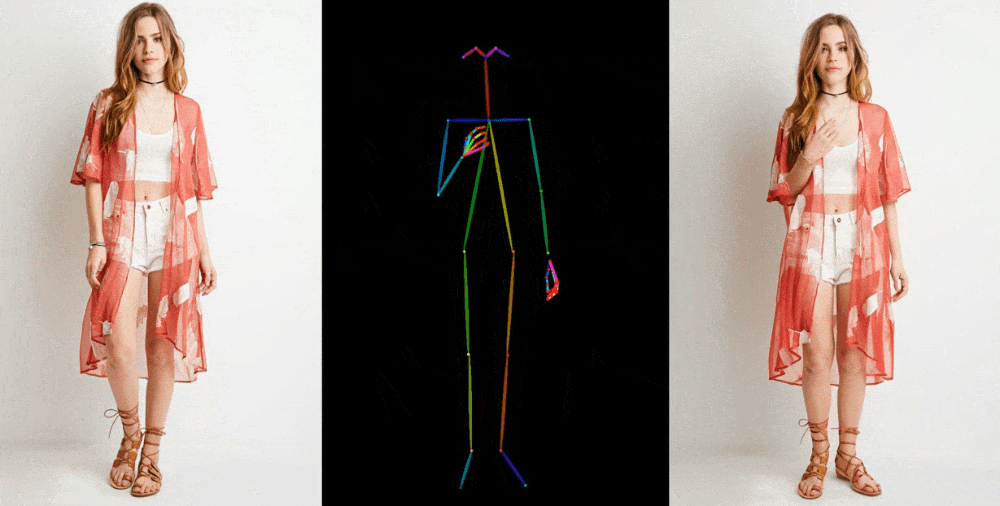
Image Credits: Alibaba Group
They show off their results in a few contexts. Fashion models take on arbitrary poses without deforming or the clothing losing its pattern. A 2D anime figure comes to life and dances convincingly. Lionel Messi makes a few generic movements.
They’re far from perfect — especially about the eyes and hands, which pose particular trouble for generative models. And the poses that are best represented are those closest to the original; if the person turns around, for instance, the model struggles to keep up. But it’s a huge leap over the previous state of the art, which produced way more artifacts or completely lost important details like the color of a person’s hair or their clothing.
It’s unnerving thinking that given a single good-quality image of you, a malicious actor (or producer) could make you do just about anything, and combined with facial animation and voice capture tech, they could also make you express anything at the same time. For now, the tech is too complex and buggy for general use, but things don’t tend to stay that way for long in the AI world.
At least the team isn’t unleashing the code into the world just yet. Though they have a GitHub page, the developers write: “we are actively working on preparing the demo and code for public release. Although we cannot commit to a specific release date at this very moment, please be certain that the intention to provide access to both the demo and our source code is firm.”
Will all hell break loose when the internet is suddenly flooded with dancefakes? We’ll find out, and probably sooner than we would like.