Keeping up with an industry as fast-moving as AI is a tall order. So until an AI can do it for you, here’s a handy roundup of recent stories in the world of machine learning, along with notable research and experiments we didn’t cover on their own.
This week, it was impossible to tune out — for this reporter included, much to my sleep-deprived brain’s dismay — the leadership controversy surrounding AI startup OpenAI. The board ousted Sam Altman, CEO and a co-founder, allegedly over what they saw as misplaced priorities on his part: commercializing AI at the expense of safety.
Altman was — in large part thanks to the efforts of Microsoft, a major OpenAI backer — reinstated as CEO and most of the original board replaced. But the saga illustrates the perils of AI companies, even those as large and influential as OpenAI, as the temptation to tap into… monetization-oriented sources of funding grows ever-stronger.
It’s not that AI labs necessarily want to become enmeshed with commercially-aligned, hungry-for-returns venture firms and tech giants. It’s that the sky-high costs of training and developing AI models makes it nigh impossible to avoid this fate.
According to CNBC, the process of training a large language model such as GPT-3, the predecessor to OpenAI’s flagship text-generating AI model, GPT-4, could cost over $4 million. That estimate doesn’t factor in the cost of hiring data scientists, AI experts and software engineers — all of whom command high salaries.
It’s no accident that many large AI labs have strategic agreements with public cloud providers; compute, especially at a time when the chips to train AI models are in short supply (benefiting vendors like Nvidia), has become more valuable than gold to these labs. Chief OpenAI rival Anthropic has taken on investments from both Google and Amazon and Character.ai, meanwhile, have the backing of Google Cloud, which is also their exclusive compute infrastructure provider.
But, as this week showed, these investments come at a risk. Tech giants have their own agendas — and the weight to throw around to see their bidding done.
OpenAI attempted to maintain some independence with a unique, “capped-profit” structure that limits investors’ total returns. But Microsoft showed that compute can be just as valuable as capital in bringing a startup to heel; much of Microsoft’s investment in OpenAI is in the form of Azure cloud credits, and the threat of withholding these credits would be enough to get any board’s attention.
Barring massively increased investments in public supercomputing resources or AI grant programs, the status quo doesn’t look likely to change soon. AI startups of a certain size — like most startups — are forced to cede control over their destinies if they wish to grow. Hopefully, unlike OpenAI, they make a deal with the devil they know.
Here are some other AI stories of note from the past few days:
- OpenAI isn’t going to destroy humanity: Has OpenAI invented AI tech with the potential to “threaten humanity”? From some of the recent headlines, you might be inclined to think so. But there’s no cause for alarm, experts say.
- California eyes AI rules: California’s Privacy Protection Agency is preparing for its next trick: Putting guardrails on AI. Natasha writes that the state privacy regulator recently published draft regulations for how people’s data can be used for AI, taking inspiration from existing rules in the European Union.
- Bard answers YouTube questions: Google has announced that its Bard AI chatbot can now answer questions about YouTube videos. Although Bard already had the ability to analyze YouTube videos with the launch of the YouTube Extension back in September, the chatbot can now give you specific answers about queries related to the content of a video.
- X’s Grok set to launch: Shortly after screenshots emerged showing xAI’s chatbot Grok appearing on X’s web app, X owner Elon Musk confirmed that Grok would be available to all of the company’s Premium+ subscribers sometime this week. While Musk’s pronouncements about time frames for product deliveries haven’t always held up, code developments in X’s own app reveal that Grok integration is well underway.
- Stability AI releases a video generator: AI startup Stability AI last week announced Stable Video Diffusion, an AI model that generates videos by animating existing images. Based on Stability’s existing Stable Diffusion text-to-image model, Stable Video Diffusion is one of the few video-generating models available in open source — or commercially, for that matter.
- Anthropic releases Claude 2.1: Anthropic recently released Claude 2.1, an improvement on its flagship large language model that keeps it competitive with OpenAI’s GPT series. Devin writes that the new update to Claude has three major improvements: context window, accuracy and extensibility.
- OpenAI and open AI: Paul writes that the OpenAI debacle has shone a spotlight on the forces that control the burgeoning AI revolution, leading many to question what happens if you go all-in on a centralized proprietary player — and what happens if things then go belly-up.
- AI21 Labs raises cash: AI21 Labs, a company developing generative AI products along the lines of OpenAI’s GPT-4 and ChatGPT, last week raised $53 million — bringing its total raised to $336 million. A Tel Aviv-based startup creating a range of text-generating AI tools, AI21 Labs was founded in 2017 by Mobileye co-founder Amnon Shashua, Ori Goshen and Yoav Shoham, the startup’s other co-CEO.
More machine learnings
Making AI models more candid about when they need more information to produce a confident answer is a difficult problem, since really, the model doesn’t know the difference between right and wrong. But by making the model expose its inner workings a bit, you can get a better sense of when it’s more likely to be fibbing.
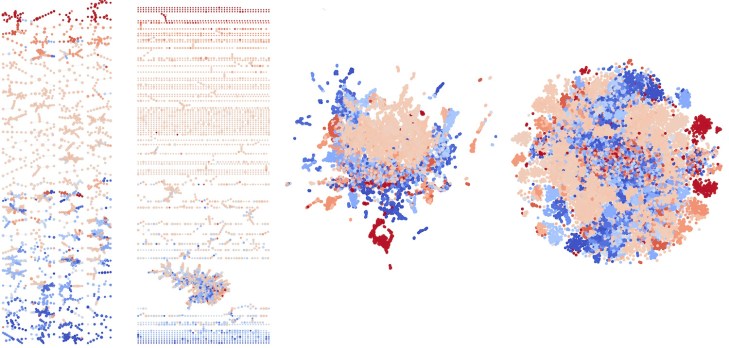
Image Credits: Purdue University
This work by Purdue creates a human-readable “Reeb map” of how the neural network represents visual concepts in its vector space. Items it deems similar are grouped together, and overlaps with other areas could indicate either similarities between those groups or confusion on the model’s part. “What we’re doing is taking these complicated sets of information coming out of the network and giving people an ‘in’ into how the network sees the data at a macroscopic level,” said lead researcher David Gleich.

Image Credits: Los Alamos National Lab
If your dataset is limited, it might be best if you don’t extrapolate too much from it, but if you must… perhaps a tool like “Senseiver,” from Los Alamos National Lab, is your best bet. The model is based on Google’s Perceiver, and is able to take a handful of sparse measurements and — apparently — make surprisingly accurate predictions by filling in the gaps.
This could be for things like climate measurements, other scientific readings or even 3D data like low-fidelity maps created by high-altitude scanners. The model can run on edge computers, like drones, which may now be able to perform searches for specific features (in their test case, methane leaks) instead of just reading the data then bringing it back to be analyzed later.
Meanwhile, researchers are working on making the hardware that runs these neural networks more like a neural network itself. They made a 16-electrode array and then covered it with a bed of conductive fibers in a random but consistently dense network. Where they overlap, these fibers can either form connections or break them, depending on a number of factors. In a way it’s lot like the way neurons in our brains form connections and then dynamically reinforce or abandon those connections.
The UCLA/University of Sydney team said the network was able to identify hand-written numbers with 93.4% accuracy, which actually outperformed a more conventional approach at a similar scale. It’s fascinating for sure but a long way from practical use, though self-organizing networks are probably going to find their way into the toolbox eventually.

Image Credits: UCLA/University of Sydney
It’s nice to see machine learning models helping people out, and we’ve got a few examples of that this week.
A group of Stanford researchers are working on a tool called GeoMatch intended to help refugees and immigrants find the right location for their situation and skills. It’s not some automated procedure — right now these decisions are made by placement officers and other officials who, while experienced and informed, can’t always be sure their choices are backed up by data. The GeoMatch model takes a number of characteristics and suggests a location where the person is likely to find solid employment.
“What once took multiple people hours of research can now be done in minutes,” said the project’s leader, Michael Hotard. “GeoMatch can be incredibly useful as a tool that simplifies the process of gathering information and making connections.”
At University of Washington, robotics researchers just presented their work on creating an automated feeding system for people who can’t eat on their own. The system has gone through lots of versions and evolved with feedback from the community, and “we’ve gotten to the point where we can pick up nearly everything a fork can handle. So we can’t pick up soup, for example. But the robot can handle everything from mashed potatoes or noodles to a fruit salad to an actual vegetable salad, as well as pre-cut pizza or a sandwich or pieces of meat,” said co-lead Ethan K. Gordon in a Q&A posted by the university.

Image Credits: University of Washington
It’s an interesting chat, showing how projects like these are never really “done,” but at every stage they can help more and more people.
There are a few projects out there for helping blind folks make their way around the world, from Be My AI (powered by GPT-4V) to Microsoft’s Seeing AI, a collection of purpose-built models for everyday tasks. Google had its own, a pathfinding app called Project Guideline that was intended to help keep people on track when walking or jogging down a path. Google just made it open source, which generally means they’re giving up on something — but their loss is other researchers’ gain, because the work done at the billion-dollar company can now be used in a personal project.
Last up, a bit of fun in FathomVerse, a game/tool for identifying sea creatures the way apps like iNaturalist and so on identify leaves and plants. It needs your help, though, because animals like anemones and octopi are squishy and hard to ID. So sign up for the beta and see if you can help get this thing off the ground!

Image Credits: FathomVerse