This week in AI: AI heavyweights try to tip the regulatory scales


Image Credits: PhonlamaiPhoto / Getty Images
Keeping up with an industry as fast-moving as AI is a tall order. So until an AI can do it for you, here’s a handy roundup of the last week’s stories in the world of machine learning, along with notable research and experiments we didn’t cover on their own.
This week, movers and shakers in the AI industry, including OpenAI CEO Sam Altman, embarked on a goodwill tour with policymakers — making the case for their respective visions of AI regulation. Speaking to reporters in London, Altman warned that the EU’s proposed AI Act, due to be finalized next year, could lead OpenAI ultimately to pull its services from the bloc.
“We will try to comply, but if we can’t comply we will cease operating,” he said.
Google CEO Sundar Pichai, also in London, emphasized the need for “appropriate” AI guardrails that don’t stifle innovation. And Microsoft’s Brad Smith, meeting with lawmakers in Washington, proposed a five-point blueprint for the public governance of AI.
To the extent that there’s a common thread, tech titans expressed a willingness to be regulated — so long as it doesn’t interfere with their commercial ambitions. Smith, for instance, declined to address the unresolved legal question of whether training AI on copyrighted data (which Microsoft does) is permissible under the fair use doctrine in the U.S. Strict licensing requirements around AI training data, were they to be imposed at the federal level, could prove costly for Microsoft and its rivals doing the same.
Altman, for his part, appeared to take issue with provisions in the AI Act that require companies to publish summaries of the copyrighted data they used to train their AI models, and make them partially responsible for how the systems are deployed downstream. Requirements to reduce the energy consumption and resource use of AI training — a notoriously compute-intensive process — were also questioned.
The regulatory path overseas remains uncertain. But in the U.S., the OpenAIs of the world may get their way in the end. Last week, Altman wooed members of the Senate Judiciary Committee with carefully-crafted statements about the dangers of AI, and his recommendations for regulating it. Sen. John Kennedy (R-LA) was particularly deferential: “This is your chance, folks, to tell us how to get this right … Talk in plain English and tell us what rules to implement,” he said.
In comments to The Daily Beast, Suresh Venkatasubramanian, Brown University’s director of the Center for Tech Responsibility, perhaps summed it up it best: “We don’t ask arsonists to be in charge of the fire department.” And yet that’s what’s in danger of happening here, with AI. It’ll be incumbent on legislators to resist they honeyed words of tech execs and clamp down where it’s needed. Only time will tell if they do.
Here are the other AI headlines of note from the past few days:
- ChatGPT comes to more devices: Despite being U.S.- and iOS-only ahead of an expansion to 11 more global markets, OpenAI’s ChatGPT app is off to a stellar start, Sarah writes. The app has already passed half a million downloads in its first six days, app trackers say. That ranks it as one of the highest-performing new app releases across both this year and the last, topped only by the February 2022 arrival of the Trump-backed Twitter clone, Truth Social.
- OpenAI proposes a regulatory body: AI is developing rapidly enough — and the dangers it may pose are clear enough — that OpenAI’s leadership believes that the world needs an international regulatory body akin to that governing nuclear power. OpenAI’s co-founders argued this week that the pace of innovation in AI is so fast that we can’t expect existing authorities to adequately rein in the technology, so we need new ones.
- Generative AI comes to Google Search: Google announced this week that it’s starting to open up access to new generative AI capabilities in Search after teasing them at its I/O event earlier in the month. With this new update, Google says that users can easily get up to speed on a new or complicated topic, uncover quick tips for specific questions or get deep info like customer ratings and prices on product searches.
- TikTok tests a bot: Chatbots are hot, so it’s no surprise to learn that TikTok is piloting its own, as well. Called “Tako,” the bot is in limited testing in select markets, where it will appear on the right-hand side of the TikTok interface above a user’s profile and other buttons for likes, comments and bookmarks. When tapped, users can ask Tako various questions about the video they’re watching or discover new content by asking for recommendations.
- Google on an AI Pact: Google’s Sundar Pichai has agreed to work with lawmakers in Europe on what’s being referred to as an “AI Pact” — seemingly a stop-gap set of voluntary rules or standards while formal regulations on AI are developed. According to a memo, it’s the bloc’s intention to launch an AI Pact “involving all major European and non-European AI actors on a voluntary basis” and ahead of the legal deadline of the aforementioned pan-EU AI Act.
- People, but made with AI: With Spotify’s AI DJ, the company trained an AI on a real person’s voice — that of its head of Cultural Partnerships and podcast host, Xavier “X” Jernigan. Now the streamer may turn that same technology to advertising, it seems. According to statements made by The Ringer founder Bill Simmons, the streaming service is developing AI technology that will be able to use a podcast host’s voice to make host-read ads — without the host actually having to read and record the ad copy.
- Product imagery via generative AI: At its Google Marketing Live event this week, Google announced that it’s launching Product Studio, a new tool that lets merchants easily create product imagery using generative AI. Brands will be able to create imagery within Merchant Center Next, Google’s platform for businesses to manage how their products show up in Google Search.
- Microsoft bakes a chatbot into Windows: Microsoft is building its ChatGPT-based Bing experience right into Windows 11 — and adding a few twists that allow users to ask the agent to help navigate the OS. The new Windows Copilot is meant to make it easier for Windows users to find and tweak settings without having to delve deep into Windows submenus. But the tools will also allow users to summarize content from the clipboard, or compose text.
- Anthropic raises more cash: Anthropic, the prominent generative AI startup co-founded by OpenAI veterans, has raised $450 million in a Series C funding round led by Spark Capital. Anthropic wouldn’t disclose what the round valued its business at. But a pitch deck we obtained in March suggests it could be in the ballpark of $4 billion.
- Adobe brings generative AI to Photoshop: Photoshop got an infusion of generative AI this week with the addition of a number of features that allow users to extend images beyond their borders with AI-generated backgrounds, add objects to images or use a new generative fill feature to remove them with far more precision than the previously available content-aware fill. For now, the features will only be available in the beta version of Photoshop. But they’re already causing some graphic designers consternation about the future of their industry.
Other machine learnings
Bill Gates may not be an expert on AI, but he is very rich, and he’s been right on things before. Turns out he is bullish on personal AI agents, as he told Fortune: “Whoever wins the personal agent, that’s the big thing, because you will never go to a search site again, you will never go to a productivity site, you’ll never go to Amazon again.” How exactly this would play out is not stated, but his instinct that people would rather not borrow trouble by using a compromised search or productivity engine is probably not far off base.
Evaluating risk in AI models is an evolving science, which is to say we know next to nothing about it. Google DeepMind (the newly formed super entity comprising Google Brain and DeepMind) and collaborators across the globe are trying to move the ball forward, and have produced a model evaluation framework for “extreme risks” such as “strong skills in manipulation, deception, cyber-offense, or other dangerous capabilities.” Well, it’s a start.

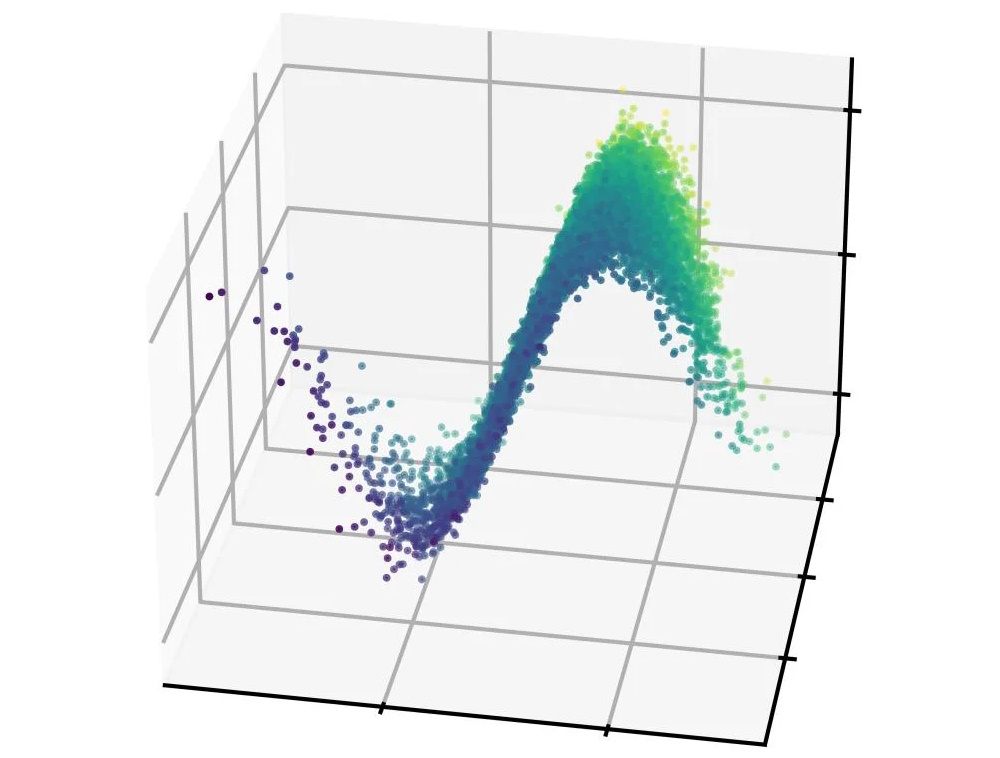
Image Credits: SLAC
Particle physicists are finding interesting ways to apply machine learning to their work: “We’ve shown that we can infer very complicated high-dimensional beam shapes from astonishingly small amounts of data,” says SLAC’s Auralee Edelen. They created a model that helps them predict the shape of the particle beam in the accelerator, something that normally takes thousands of data points and lots of compute time. This is much more efficient and could help make accelerators everywhere easier to use. Next up: “demonstrate the algorithm experimentally on reconstructing full 6D phase space distributions.” OK!
Adobe Research and MIT collaborated on an interesting computer vision problem: telling which pixels in an image represent the same material. Since an object can be multiple materials as well as colors and other visual aspects, this is a pretty subtle distinction but also an intuitive one. They had to build a new synthetic dataset to do it, but at first it didn’t work. So they ended up fine-tuning an existing CV model on that data, and it got right to it. Why is this useful? Hard to say, but it’s cool.


Frame 1: material selection; 2: source video; 3: segmentation; 4: mask Image Credits: Adobe/MIT
Large language models are generally primarily trained in English for many reasons, but obviously the sooner they work as well in Spanish, Japanese and Hindi the better. BLOOMChat is a new model built on top of BLOOM that works with 46 languages at present, and is competitive with GPT-4 and others. This is still pretty experimental so don’t go to production with it but it could be great for testing out an AI-adjacent product in multiple languages.
NASA just announced a new crop of SBIR II fundings, and there are a couple interesting AI bits and pieces in there:
Geolabe is detecting and predicting groundwater variation using AI trained on satellite data, and hopes to apply the model to a new NASA satellite constellation going up later this year.
Zeus AI is working on algorithmically producing “3D atmospheric profiles” based on satellite imagery, essentially a thick version of the 2D maps we already have of temperature, humidity, and so on.

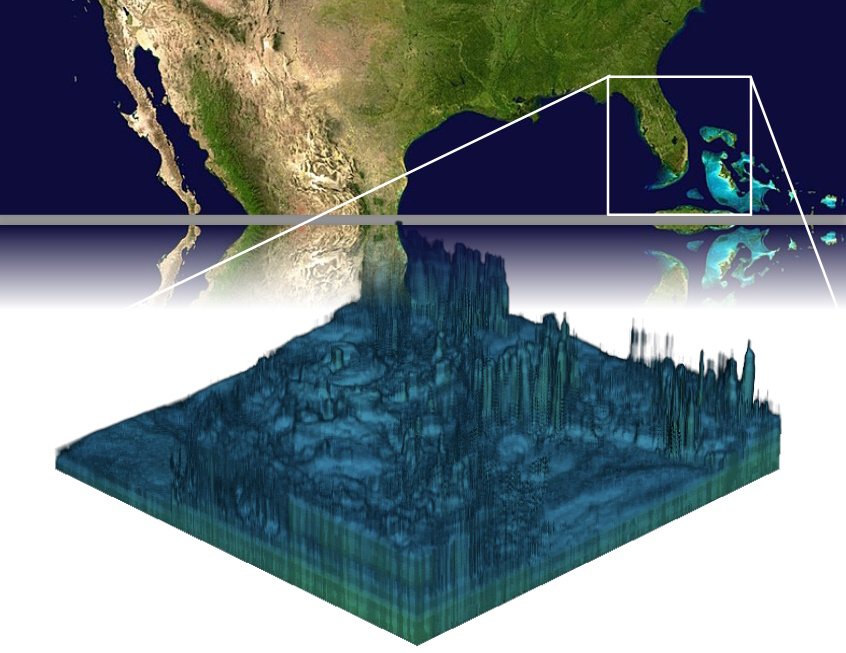
Image Credits: Zeus AI
Up in space your computing power is very limited, and while we can run some inference up there, training is right out. But IEEE researchers want to make a SWaP-efficient neuromorphic processor for training AI models in situ.
Robots operating autonomously in high-stakes situations generally need a human minder, and Picknick is looking at making such bots communicate their intentions visually, like how they would reach to open a door, so that the minder doesn’t have to intervene as much. Probably a good idea.










