
Research papers come out far too rapidly for anyone to read them all, especially in the field of machine learning, which now affects (and produces papers in) practically every industry and company. This column aims to collect some of the most relevant recent discoveries and papers — particularly in but not limited to artificial intelligence — and explain why they matter.
This week brings a few unusual applications of or developments in machine learning, as well as a particularly unusual rejection of the method for pandemic-related analysis.
One hardly expects to find machine learning in the domain of government regulation, if only because one assumes federal regulators are hopelessly behind the times when it comes to this sort of thing. So it may surprise you that the U.S. Environmental Protection Agency has partnered with researchers at Stanford to algorithmically root out violators of environmental rules.
When you see the scope of the issue, it makes sense. EPA authorities need to process millions of permits and observations pertaining to Clean Water Act compliance, things such as self-reported amounts of pollutants from various industries and independent reports from labs and field teams. The Stanford-designed process sorted through these to isolate patterns like which types of plants, in which areas, were most likely to affect which demographics. For instance, wastewater treatment in urban peripheries may tend to underreport pollution and put communities of color at risk.
The very process of reducing the compliance question to something that can be computationally parsed and compared helped clarify the agency’s priorities, showing that while the technique could identify more permit holders with small violations, it may draw attention away from general permit types that act as a fig leaf for multiple large violators.
Another large source of waste and expense is processing scrap metal. Tons of it goes through sorting and recycling centers, where the work is still mostly done by humans, and as you might imagine, it’s a dangerous and dull job. Eversteel is a startup out of the University of Tokyo that aims to automate the process so that a large proportion of the work can be done before human workers even step in.

Image Credits: Eversteel
Eversteel uses a computer vision system to classify incoming scrap into nearly two dozen categories, and to flag impure (i.e., an unrecyclable alloy) or anomalous items for removal. It’s still at an early stage, but the industry isn’t going anywhere, and the lack of any large data set for training their models (they had to make their own, informed by steelworkers and imagery) showed Eversteel that this was indeed virgin territory for AI. With luck, they’ll be able to commercialize their system and attract the funding they need to break into this large but tech-starved industry.
Another unusual but potentially helpful application of computer vision is in soil monitoring, a task every farmer has to do regularly to monitor water and nutrient levels. When they do manage to automate it, it’s done in a rather heavy-handed way. A team from the University of South Australia and Middle Technical University in Baghdad show that the sensors, hardware and thermal cameras used now may be overkill.

Image Credits: UNISA/Middle Technical University
Surprisingly, their answer is a standard RGB digital camera, which analyzes the color of the soil to estimate moisture. “We tested it at different distances, times and illumination levels, and the system was very accurate,” said Ali Al-Naji, one of the creators. It could (and is planned to) be used to make a cheap but effective smart irrigation system that could improve crop yield for those who can’t afford industry-standard systems.
Smart speakers are everywhere, but this one’s a bit different. University of Washington researchers have created a device that uses ultrasound to remotely monitor the user’s heartbeat, allowing it to detect arrhythmia and potentially other problems with reasonable accuracy.
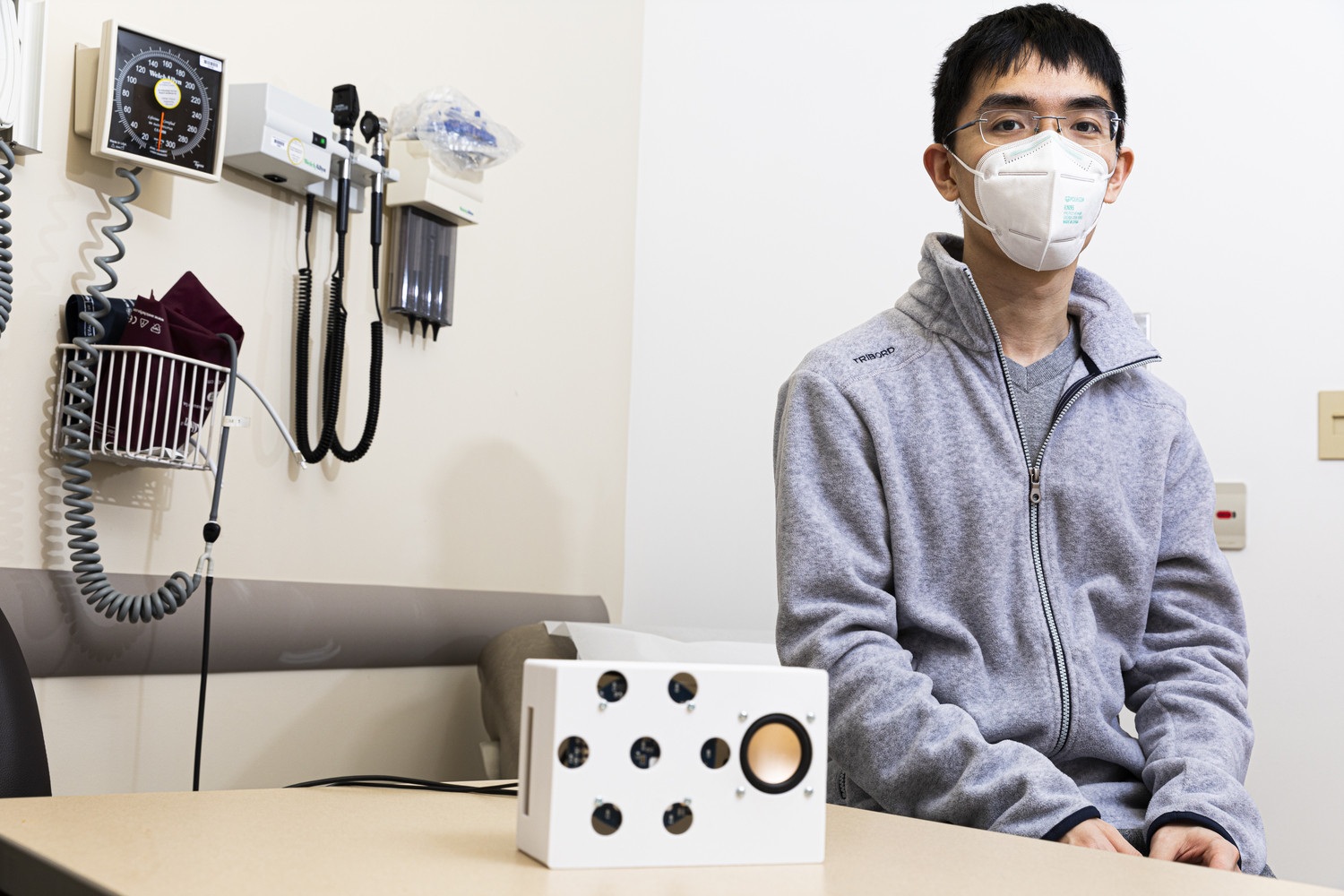
University of Washington researchers have developed a new skill for a smart speaker that acts as a contactless monitor for both regular and irregular heartbeats. Here, lead author Anran Wang, a UW doctoral student in the Paul G. Allen School of Computer Science & Engineering, sits with the smart speaker prototype (white box in foreground) the team used for the study. Image Credits: Mark Stone/University of Washington
Lead author and grad student at UW Anran Wang explained the difficulty of the problem: “The motion from someone’s breathing is orders of magnitude larger on the chest wall than the motion from heartbeats, so that poses a pretty big challenge. And the breathing signal is not regular so it’s hard to simply filter it out. Using the fact that smart speakers have multiple microphones, we designed a new beam-forming algorithm to help the speakers find heartbeats.”
The system uses a self-supervised machine learning model to tease out the tiny relevant signal from the noise. Prolific UW inventor and professor Shyam Gollakota said he was “pleasantly surprised” that it worked. A low-cost, noninvasive test that can be performed easily at home could help identify heart disorders that might otherwise slip through the cracks.
Back to the expected
Sorting through large amounts of data has become a specialty of machine learning, and a new front in the battle against giant data sets is using unsupervised learning to tease out patterns without the need for human know-how. Los Alamos National Labs researchers’ SmartTensors tool is meant for doing just this for data sets on the terabyte scale.
Image Credits: Los Alamos National Labs
Supervised learning, where an agent is taught with examples how to, say, tell apart images of cats from those of dogs, is not always practical for a number of reasons, or the data may not need that kind of labeling. Unsupervised learning lets the agent find its own patterns, which may or may not correspond to ones humans know about or even thought to look for. The LANL system is built to do this with huge data sets from across scientific disciplines, from seismology to text.
The Julia-based factorization and feature finder frameworks are available and documented here — if you knew what some of those words were, this may be useful to you.
The LANL work is perhaps not so unexpected as to fit with the theme of this article, but interestingly, an effort one might expect to bear fruit — applying machine learning techniques to COVID-19 diagnosis — has not done so. A Cambridge report looked at hundreds of attempts to use machine learning in the context of the pandemic and found that none of them hold up.
“Our review finds that none of the models identified are of potential clinical use due to methodological flaws and/or underlying biases,” the team writes in the paper published in Nature Machine Intelligence.
This should not be taken as a failure per se, simply an indication that approaches need to be adjusted. A cutting-edge technology being applied to an unprecedented and quickly evolving global pandemic is as much about littering the ground with null hypotheses and mistaken approaches as it is about finding something that works. It is perhaps a bit remarkable that the researchers found nothing worth saving, but they hope that their advice in the paper will raise the success rate above zero.
Deepfakes are another area of concern in the world of AI, and the arms race of creating versus detecting them has become a sort of discipline in its own right. An example of the state of things is this technique from the University of Buffalo for recognizing deepfakes by looking closely at the reflections in the eyes of the person or “person.”

Image Credits: www.thispersondoesnotexist.com and the University at Buffalo
The reflections of the world on the eye should be similar, but in deepfakes they often aren’t — one of many small inconsistencies that the generative adversarial networks that create these faces don’t notice. Of course, the next generation of deepfakes will take this into account … and so the cycle continues.
Last is some work from Facebook on learning from video. The company has a uniquely enormous data set to work with, and it was worked hard at scaling up techniques that work on still images or short clips so they can be applied to videos.

Image Credits: Facebook
It’s not just adding compute power or efficiency, though. Understanding video for Facebook means connecting it to context and other videos. Ten videos may show people doing very different movements in very different places, but when you add in sound, you find that they’re all dancing to the same song. That’s important! And combining the data from these two streams in different ways can produce new and interesting ways to surface or organize content. So part of the new pipeline is integrating the visual and auditory aspects of this multiformat medium.
The audio side of video also means a lot of varied language being used in naturalistic circumstances, instead of the more carefully recorded and curated libraries often used to train language models. Facebook’s wav2vec 2.0 learns quickly (meaning it doesn’t need thousands of hours of labeled data) and outperformed a more traditional model handily when it came to understanding real-world audio.
Quick, effective language understanding is important for a huge number of reasons, but for Facebook it matters in virtual communication — real-time captioning in Messenger, VR and other situations (as well as, no doubt, better gleaning of interests for ad purposes). They’re currently working on a giant model that works in 25 languages, so expect another announcement along these lines soon.
As a final note, congratulations to Danish researcher Christian Wulff-Nilsen, who shows with his near-optimal solution for the Single-Source Shortest Path problem that the fundamentals of graph navigation (at the heart of many “AI”-type problems) can be improved upon. “The closest thing to optimal that will ever be, even if we look 1,000 years into the future,” he suggested. We’ll check back in 3021.