
Twitter today is rolling out a new product track on its API platform, as part of its ongoing efforts to rebuild the Twitter API from the ground up. The track, which aims to serve the needs of the academic research community’s efforts, offers broader access to the Twitter archive and fewer restrictions on tweet retrievals, so researchers can access the entire history of the public conversation on Twitter’s platform.
In addition to gaining access to all the Twitter API v2 endpoints released to date and elevated access, researchers will gain access to more precise filtering capabilities.
Specifically, they’ll be able to access the full-archive search endpoint, which offers access to everything being said on Twitter. They can narrow searches for these historical tweets using start time and end time parameters.
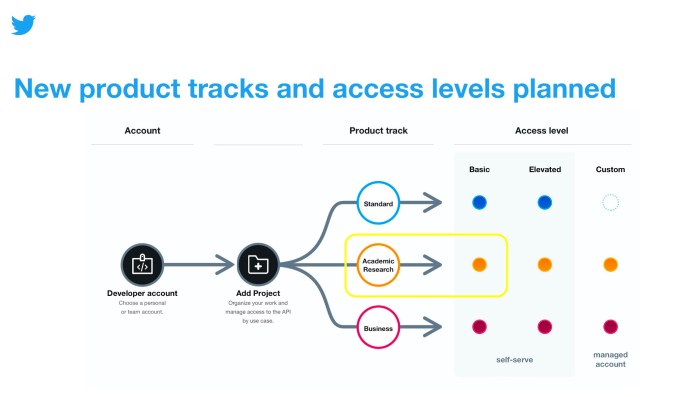
Image Credits: Twitter
Researchers will also gain a significantly higher monthly cap on the number of tweets they can pull using the Twitter API v2. While on the Basic level of API access, this cap is set to 500,000. The Basic level of access on the Academic Research track is an initial monthly cap of up to 10 million tweets. This applies to the Recent Search, Filtered Stream, Full-archive search, and user tweet and mentions timelines endpoints, Twitter says.
The Academic Research track will gain access to certain operators that aren’t otherwise available, too, with the goal of helping them pull more precise user data. Today, these include: $ (aka cashtag), bio, bio_name, bio_location, place, place_country, point_radius, bounding_box, -is:nullcast, has:cashtags and has:geo.
Researchers can also add 1,000 concurrent rules when using the filter stream endpoint, instead of the limit of 25 available in the Standard track. Queries in the recent search endpoint can be 1,024 characters long, compared with 512 characters in the Standard track.
Because of the elevated levels of access, those who want to gain access to the Academic Research product track have to first submit an application.
All applicants have to either be a master’s student, doctoral candidate, post-doc, faculty or research-focused employee at an academic institution or university. They will also need to have a clearly defined research objective and must be able to detail their specific plans for how they intend to use, analyze and share Twitter data from their research.
Plus, the data used from the Academic Research product track can’t be used for any commercial purposes, Twitter notes.
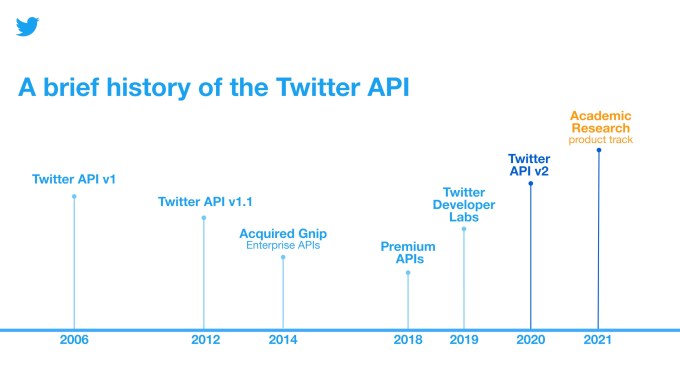
Image Credits: Twitter
Academic researchers have been taking advantage of the Twitter API since its first introduction in 2006 and have used the data to study a variety of topics, Twitter says, like state-backed efforts to disrupt the public conversation, floods and climate change, attitudes and perceptions about COVID-19 and efforts to promote healthy conversation online.
However, the earlier version of the Twitter API didn’t make it easy for researchers to gain access to Twitter data — something the company wanted to correct with API v2.
Twitter to date has catered to the research community in other ways, with additions like a website dedicated to academic research, updates to its developer policy to make it easier to reproduce and validate others’ research, and even special endpoints, like the COVID-19 stream endpoint released in April 2020. But it hasn’t fully thought through, until the API v2, how it could build tools that would actually aid researchers in doing their work, instead of the researchers having to figure out ways to work around Twitter’s limitations.
The Academic Research product track was tested in private beta starting in Oct. 2020, and now this is being opened more broadly, where it will be made freely available.
Twitter says it’s planning to add higher levels of access across all its product tracks in the future, including this one, in time. The later levels will help researchers who need even more data than what’s being offered with today’s launch. Twitter also noted it’s looking into adding flexible access as well, which would help account for times when developers were consuming more or less data throughout the year.