
Millions of homes have voice-enabled devices, but when was the last time you heard a piece of synthesized speech longer than a handful of seconds? WellSaid Labs has pushed the field ahead with a voice engine that can easily and quickly generate hours of voice content that sounds just as good or better than the snippets we hear every day from Siri and Alexa.
The company has been working since its public debut last year to advance its tech from impressive demo to commercial product, and in the process found a lucrative niche that it can build from.
CTO Michael Petrochuk explained that early on, the company had essentially based its technology on prior research — Google’s Tacotron project, which established a new standard for realism in artificial speech.
“Despite being released two years ago, Tacotron 2 is still state of the art. But it has a couple issues,” explained Petrochuk. “One, it’s not fast — it takes three minutes to produce one second of audio. And it’s built to model 15 seconds of audio. Imagine that in a workflow where you’re generating 10 minutes of content — it’s orders of magnitude off where we want to be.”
WellSaid completely rebuilt their model with a focus on speed, quality and length, which sounds like “focusing” on everything at once, but there are always plenty more parameters to optimize for. The result is a model that can generate extremely high-quality speech with any of 15 voices (and several languages) at about half real-time — so a minute-long clip would take about 36 seconds to generate instead of a couple hours.
This seemingly basic capability has plenty of benefits. Not only is it faster, but it makes working with the results simpler and easier. As a producer of audio content, you can just drop in a script hundreds of words long, listen to what it puts out, then tweak its pronunciation or cadence with a few keystrokes. Tacotron changed the synthetic speech space, but it has never really been a product. WellSaid builds on its advances with its own to create both a usable piece of software, and arguably a better speech system overall.
As evidence, clips generated by the model — 15-second ones, so they can compete with Tacotron and others — reached a milestone of being equally well-rated as human voices in tests organized by WellSaid. There’s no objective measure for this kind of thing, but asking lots of humans to weigh in on how human something sounds is a good place to start.
As part of the team’s work to achieve “human parity” under these conditions, they also released a number of audio clips demonstrating how the model can produce much more demanding content.
It generated plausible-sounding speech in Spanish, French and German (I’m not a native speaker of any of them, so can’t say more than that), showed off its facility with complex and linguistically difficult words (like stoichiometry and halogenation), words that differ depending on context (buffet, desert), and so on. The crowning achievement must be a continuous 8-hour reading of the entirety of Mary Shelley’s “Frankenstein.”
But audiobooks aren’t the industry that WellSaid is using as a stepladder to further advances. Instead, they’re making a bundle working in the tremendously boring but necessary field of corporate training. You know, the sorts of videos that explain policies, document the use of internal tools and explain best practices for sales, management, development tools and so on.
Corporate learning stuff is generally unique or at least tailored to each company, and can involve hours of audio — an alternative to saying, “Here, read this packet” or gathering everyone in a room to watch a decades-old DVD on office conduct. Not the most exciting place to put such a powerful technology to work, but the truth is with startups that no matter how transformative you think your tech is, if you don’t make any money, you’re sunk.
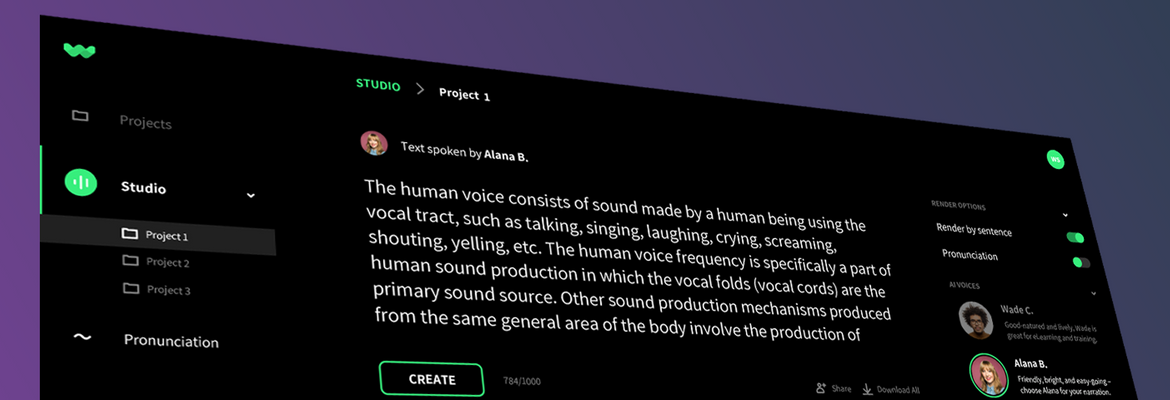
Image Credits: WellSaid Labs
“We found a sweet spot in the corporate training field, but for product development it has helped us build these foundational elements for a bigger and greater space,” explained Head of Growth Martín Ramírez. “Voice is everywhere, but we have to be pragmatic about who we build for today. Eventually we’ll deliver the infrastructure where any voice can be created and distributed.”
At first that may look like expanding the corporate offerings slowly, in directions like other languages — WellSaid’s system doesn’t have English “baked in,” and given training data in other languages should perform equally well in them. So that’s an easy way forward. But other industries could use improved voice capability as well: podcasting, games, radio shows, advertising, governance.
One significant limitation to the company’s approach is that the system is meant to be operated by a person and used for, essentially, recording a virtual voice actor. This means it’s not useful to the groups for whom an improved synthetic voice is desirable — many people with disabilities that affect their own voice, blind people who use voice-based interfaces all day long, or even people traveling in a foreign country and using real-time translation tools.
“I see WellSaid servicing that use-case in the near future,” said Ramírez, though he and the others were careful not to make any promises. “But today, the way it’s built, we truly believe a human producer should be interacting with the engine, to render it at a natural human-parity level. The dynamic rendering scenario is approaching quite fast, and we want to be prepared for it, but we’re not ready to do it today.”
The company has “plenty of runway and customers” and is growing fast — so no need for funding just now, thank you, venture capital firms.