
I see far more research articles than I could possibly write up. This column collects the most interesting of those papers and advances, along with notes on why they may prove important in the world of tech and startups.
This week: one step closer to self-powered on-skin electronics; people dressed as car seats; how to make a search engine for 3D data; and a trio of Earth imaging projects that take on three different types of disasters.
Sweat as biofuel
Monitoring vital signs is a crucial part of healthcare and is a big business across fitness, remote medicine and other industries. Unfortunately, powering devices that are low-profile and last a long time requires a bulky battery or frequent charging is a fundamental challenge. Wearables powered by body movement or other bio-derived sources are an area of much research, and this sweat-powered wireless patch is a major advance.
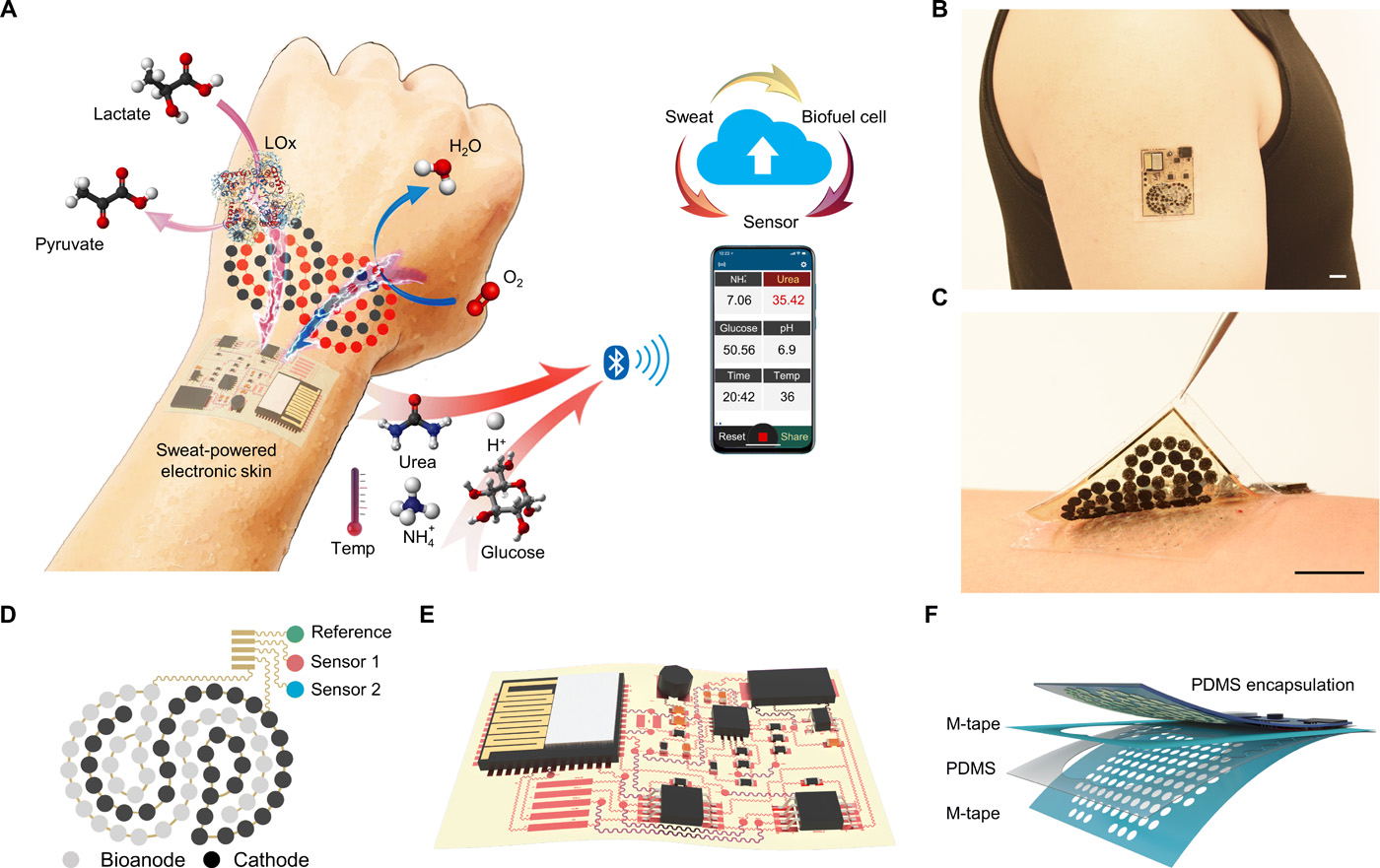
A figure from the paper showing the device and interactions happening inside it.
The device, described in Science Robotics, uses perspiration as both fuel and sampling material; sweat contains chemical signals that can indicate stress, medication uptake, and so on, as well as lactic acid, which can be used in power-generating reactions.
The patch performs this work on a flexible substrate and uses the generated power to transmit its data wirelessly. It’s reliable enough that it was used to control a prosthesis, albeit in limited fashion. The market for devices like this will be enormous and this platform demonstrates a new and interesting direction for researchers to take.
‘Ghostdrivers’ behind the wheel test pedestrian reactions

It legitimately looks like a comedy sketch, but the results are quite interesting.
Self-driving cars are sure to lead to major changes in traffic and pedestrian behaviors, but it’s hard to tell exactly what those will be. Part of the challenge is that in most places in the world, there simply aren’t any self-driving cars for people to react to — it may not even be legal to have them on the street.
Hence researchers creating “Ghostdriven” cars, with real people at the wheel but disguised as empty car seats. Yes, it’s strange, but if you think about it, it’s rather like a blind for observing wildlife.
Driving the ostentatiously empty cars around areas where no self-driving cars are permitted or expected allowed the researchers to see a variety of responses among pedestrians. Some were wary, some bold, some scared, others curious.
“We discovered that there are many different localized rules and norms for how people interact with autonomous cars and with each other,” said Cornell’s Wendy Ju in a release describing the research. “This kind of research has to happen before autonomous systems are in place.”
As she says, this type of study is necessary to inform both policy and AI behavior. A car in Mexico may need to signal its intentions differently from one in the Netherlands. And cars from different behavioral zones may need to know this about one another to keep their riders safe.
Searching 3D medical data
Tools for imaging the body have become quite sophisticated, and now produce quite enormous, high-resolution 3D models of things like healthy or diseased organs, neural pathways, and other important systems. But methods to handle, share and organize that data haven’t advanced so quickly.
David Mayerich at the University of Houston is one of many around the world working on ways to index these enormous datasets.
“We’ve developed this ability to collect massive amounts of data. Now we have to provide the software to make it accessible,” he said in a UH news release. He’s got a $500,000 grand from the National Science Foundation to develop a search engine for this kind of high-resolution 3D imagery.
Just as search engines ended up defining how we now use the web, the way we organize and surface medical data could define the next generation of telemedicine and treatment.
The view from above
A trio of Earth-imaging projects caught my eye this last week — there are constantly new applications of both satellite and aerial imagery, but these three seem especially relevant.

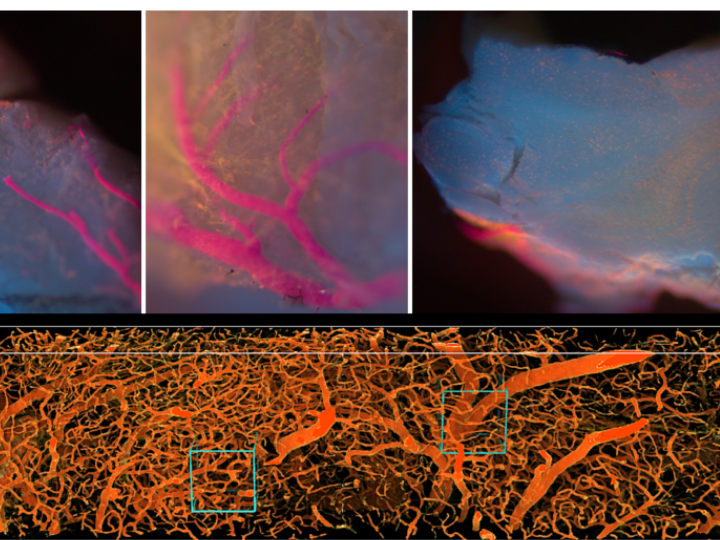
First is an MIT project that’s using lidar to map roads with more detail than ever before. Satellite data carefully sorted through by machine learning can make for very detailed maps, but finer details are needed when it comes to emergency services and maintenance.
Lidar imagery can poke through tree cover and find not just hidden roads but their condition (see top image). Knowing whether a surface is paved, dirt, rocky, muddy, occasionally flooded — and that data can be updated on short notice with the flight of a drone. That kind of information is extremely valuable during natural disasters and other emergencies.
Meanwhile, researchers from Plymouth Marine Laboratory are working on a method to track an ongoing man-made disaster: plastic littering in our oceans. There is lots of interest in tracking marine macroplastics (i.e. pieces larger than 5mm across), but it’s a surprisingly difficult problem, unless you’re looking for big patches of opaque waste.
The launch of ESA’s Earth-imaging satellites Sentinel 2A and 2B might make things easier, though. The Plymouth team describes finding plastics using multispectral imagery and generating a library of spectral signatures — mixes of light frequencies — that indicate plastic mixed with kelp, plastic mixed with oil, with silt, etc.
That we can see plastic in the ocean from space has been shown several times over, but like any other science it needs to be constantly reevaluated and updated. Soon this type of data will be standard in the growing business of Earth-imaging indexes.
Lastly, Duke researchers are utilizing the huge increase in Earth imagery captured by Planet to better estimate and predict pollution. Concentrations of microparticles flucutate with weather and industry, but the best way to track them is via expensive ground stations — and you can’t exactly build one of those every few miles.

The team instead used a library with more than 10,000 satellite images showing varying levels of pollution and fed that data to a machine learning system along with verified ground truth measurements. The system learned to pick out tiny features in the images that correlate with different pollution levels and can now predict those levels to within 24% of the actual measurements (and that’s actually pretty good).
More importantly, it can predict them for very small areas, say a city block versus a whole neighborhood. That makes it ripe for use in more local studies and perhaps even for inclusion in local weather reports.
“We think this is a huge innovation in satellite retrievals of air quality and will be the backbone of a lot of research to come,” said Professor Mike Bergin, who led the team. “We’re already starting to get inquiries into using it to look at how levels of PM2.5 are going to change once the world starts recovering from the spread of COVID-19.”
