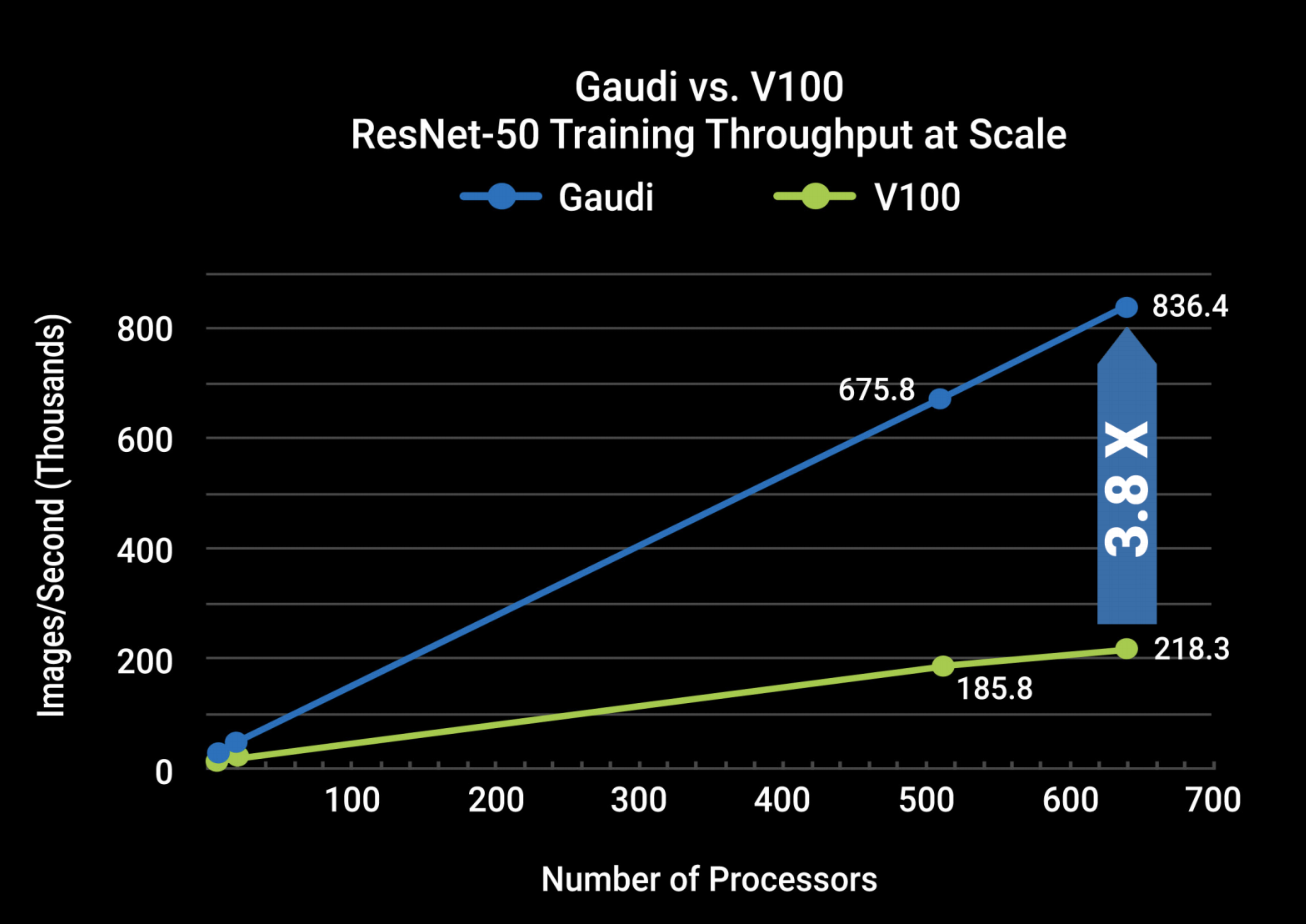
Habana Labs, a Tel Aviv-based AI processor startup, today announced its Gaudi AI training processor, which promises to easily beat GPU-based systems by a factor of four. While the individual Gaudi chips beat GPUs in raw performance, it’s the company’s networking technology that gives it the extra boost to reach its full potential.
Gaudi will be available as a standard PCIe card that supports eight ports of 100GB Ethernet, as well as a mezzanine card that is compliant with the relatively new Open Compute Project accelerator module specs. This card supports either the same 10 100GB Ethernet ports or 20 ports of 50GB Ethernet. The company is also launching a system with eight of these mezzanine cards.

Last year, Habana Labs previously launched its Goya inferencing solution. With Gaudi, it now offers a complete solution for businesses that want to use its hardware over GPUs with chips from the likes of Nvidia. Thanks to its specialized hardware, Gaudi easily beats an Nvidia T4 accelerator on most standard benchmarks — all while using less power.
“The CPU and GPU architecture started from solving a very different problem than deep learning,” Habana CBO Eitan Medina told me. “The GPU, almost by accident, happened to be just better because it has a higher degree of parallelism. However, if you start from a clean sheet of paper and analyze what a neural network looks like, you can, if you put really smart people in the same room […] come up with a better architecture.” That’s what Habana did for its Goya processor and it is now taking what it learned from this to Gaudi.

For developers, the fact that Habana Labs supports all of the standard AI/ML frameworks, as well as the ONNX format, should make the switch from one processor to another pretty painless.
“Training AI models require exponentially higher compute every year, so it’s essential to address the urgent needs of the data center and cloud for radically improved productivity and scalability. With Gaudi’s innovative architecture, Habana delivers the industry’s highest performance while integrating standards-based Ethernet connectivity, enabling unlimited scale,” said David Dahan, CEO of Habana Labs. “Gaudi will disrupt the status quo of the AI Training processor landscape.”
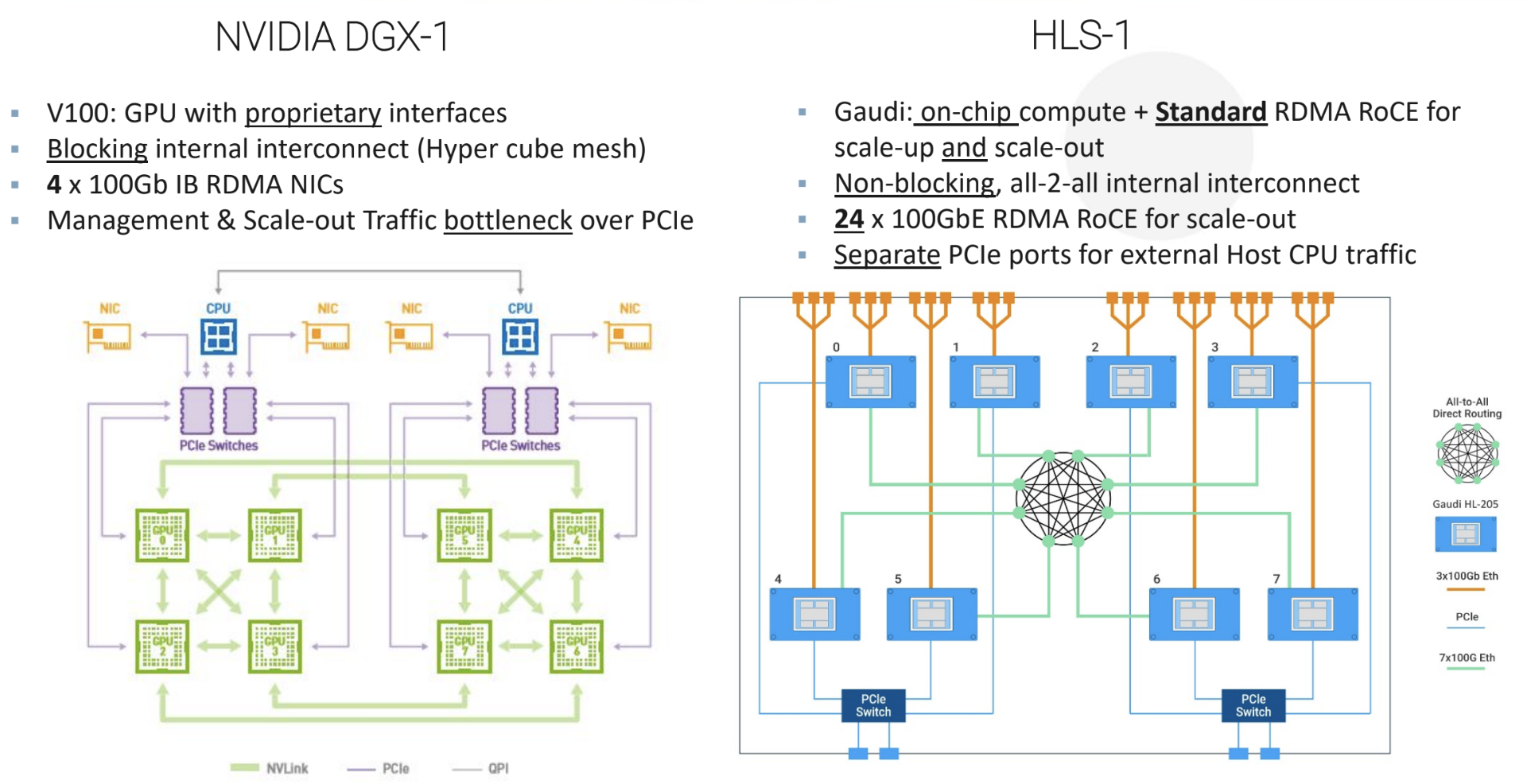
As the company told me, the secret here isn’t just the processor itself but also how it connects to the rest of the system and other processors (using standard RDMA RoCE, if that’s something you really care about).
Habana Labs argues that scaling a GPU-based training system beyond 16 GPUs quickly hits a number of bottlenecks. For a number of larger models, that’s becoming a necessity, though. With Gaudi, that becomes simply a question of expanding the number of standard Ethernet networking switches so that you could easily scale to a system with 128 Gaudis.
“With its new products, Habana has quickly extended from inference into training, covering the full range of neural-network functions,” said Linley Gwennap, principal analyst of The Linley Group. “Gaudi offers strong performance and industry-leading power efficiency among AI training accelerators. As the first AI processor to integrate 100G Ethernet links with RoCE support, it enables large clusters of accelerators built using industry-standard components.”