Machine learning models are getting quite good at generating realistic human faces — so good that I may never trust a machine, or human, to be real ever again. The new approach, from researchers at Nvidia, leapfrogs others by separating levels of detail in the faces and allowing them to be tweaked separately. The results are eerily realistic.
The paper, published on preprint repository Arxiv (PDF), describes a new architecture for generating and blending images, particularly human faces, that “leads to better interpolation properties, and also better disentangles the latent factors of variation.”
What that means, basically, is that the system is more aware of meaningful variation between images, and at a variety of scales to boot. The researchers’ older system might, for example, produce two “distinct” faces that were mostly the same except the ears of one are erased and the shirt is a different color. That’s not really distinctiveness — but the system doesn’t know that those are not important pieces of the image to focus on.
It’s inspired by what’s called style transfer, in which the important stylistic aspects of, say, a painting, are extracted and applied to the creation of another image, which (if all goes well) ends up having a similar look. In this case, the “style” isn’t so much the brush strokes or color space, but the composition of the image (centered, looking left or right, etc.) and the physical characteristics of the face (skin tone, freckles, hair).
These features can have different scales, as well — at the fine side, it’s things like individual facial features; in the middle, it’s the general composition of the shot; at the largest scale, it’s things like overall coloration. Allowing the system to adjust all of them changes the whole image, while only adjusting a few might just change the color of someone’s hair, or just the presence of freckles or facial hair.
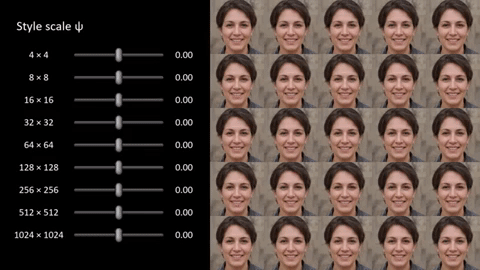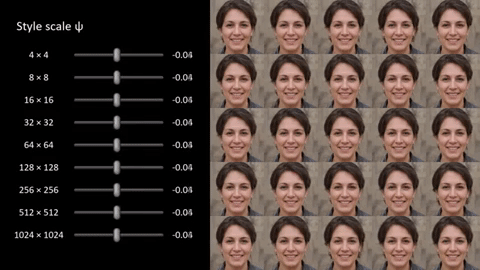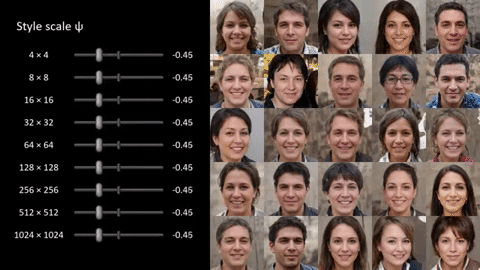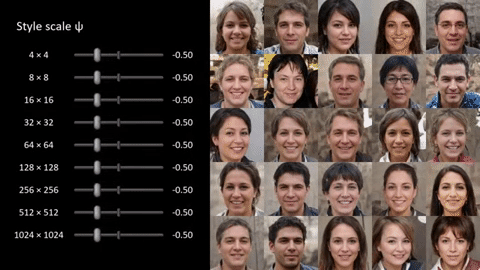
In the image at the top, notice how completely the faces change, yet obvious markers of both the “source” and “style” are obviously present, for instance the blue shirts in the bottom row. In other cases things are made up out of whole cloth, like the kimono the kid in the very center seems to be wearing. Where’d that come from? Note that all this is totally variable, not just a A + B = C, but with all aspects of A and B present or absent depending on how the settings are tweaked.
None of these are real people. But I wouldn’t look twice at most of these images if they were someone’s profile picture or the like. It’s kind of scary to think that we now have basically a face generator that can spit out perfectly normal looking humans all day long. Here are a few dozen:

It’s not perfect, but it works. And not just for people. Cars, cats, landscapes — all this stuff more or less fits the same paradigm of small, medium and large features that can be isolated and reproduced individually. An infinite cat generator sounds like a lot more fun to me, personally.
The researchers also have published a new data set of face data: 70,000 images of faces collected (with permission) from Flickr, aligned and cropped. They used Mechanical Turk to weed out statues, paintings and other outliers. Given the standard data set used by these types of projects is mostly red carpet photos of celebrities, this should provide a much more variable set of faces to work with. The data set will be available for others to download here soon.