
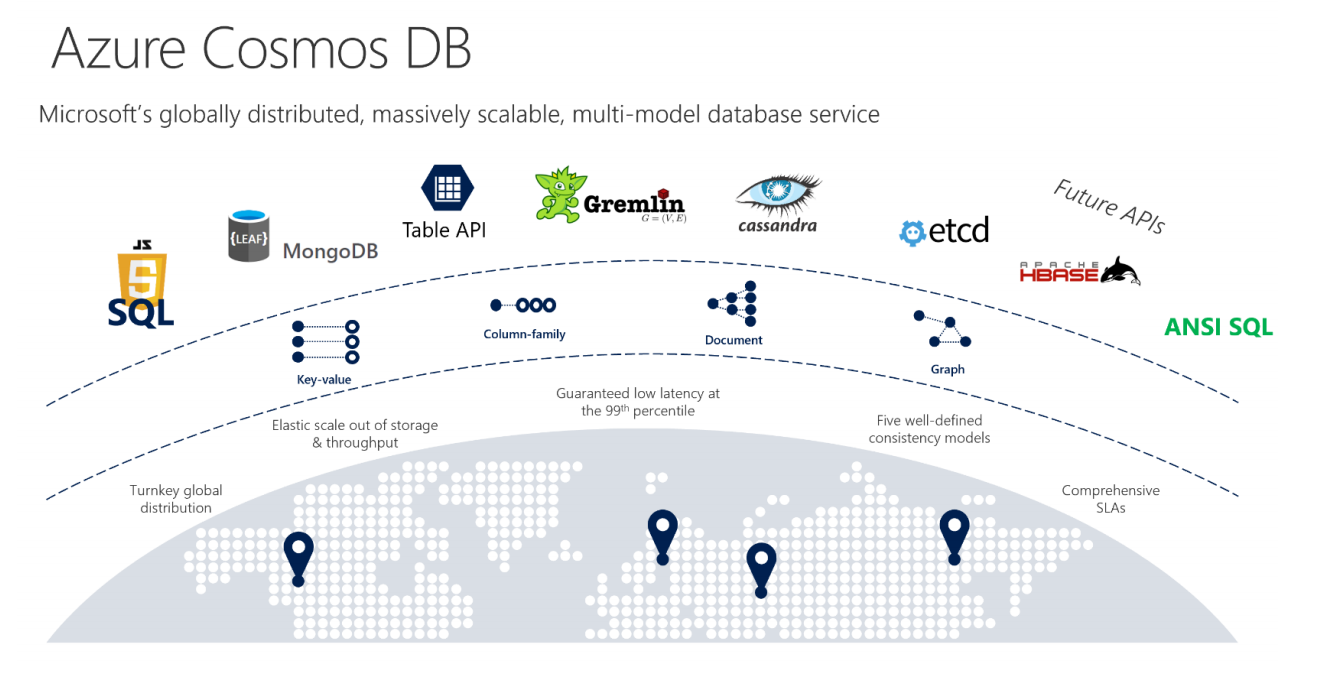
Cosmos DB is undoubtedly one of the most interesting products in Microsoft’s Azure portfolio. It’s a fully managed, globally distributed multi-model database that offers throughput guarantees, a number of different consistency models and high read and write availability guarantees. Now that’s a mouthful, but basically, it means that developers can build a truly global product, write database updates to Cosmos DB and rest assured that every other user across the world will see those updates within 20 milliseconds or so. And to write their applications, they can pretend that Cosmos DB is a SQL- or MongoDB-compatible database, for example.
CosmosDB officially launched in May 2017, though in many ways it’s an evolution of Microsoft’s existing Document DB product, which was far less flexible. Today, a lot of Microsoft’s own products run on CosmosDB, including the Azure Portal itself, as well as Skype, Office 365 and Xbox.
Today, Microsoft is extending Cosmos DB with the launch of its multi-master replication feature into general availability, as well as support for the Cassandra API, giving developers yet another option to bring existing products to CosmosDB, which in this case are those written for Cassandra.
Microsoft now also promises 99.999 percent read and write availability. Previously, it’s read availability promise was 99.99 percent. And while that may not seem like a big difference, it does show that after more of a year of operating Cosmos DB with customers, Microsoft now feels more confident that it’s a highly stable system. In addition, Microsoft is also updating its write latency SLA and now promises less than 10 milliseconds at the 99th percentile.
“If you have write-heavy workloads, spanning multiple geos, and you need this near real-time ingest of your data, this becomes extremely attractive for IoT, web, mobile gaming scenarios,” Microsoft CosmosDB architect and product manager Rimma Nehme told me. She also stressed that she believes Microsoft’s SLA definitions are far more stringent than those of its competitors.
The highlight of the update, though, is multi-master replication. “We believe that we’re really the first operational database out there in the marketplace that runs on such a scale and will enable globally scalable multi-master available to the customers,” Nehme said. “The underlying protocols were designed to be multi-master from the very beginning.”
Why is this such a big deal? With this, developers can designate every region they run Cosmos DB in as a master in its own right, making for a far more scalable system in terms of being able to write updates to the database. There’s no need to first write to a single master node, which may be far away, and then have that node push the update to every other region. Instead, applications can write to the nearest region, and Cosmos DB handles everything from there. If there are conflicts, the user can decide how those should be resolved based on their own needs.

Nehme noted that all of this still plays well with CosmosDB’s existing set of consistency models. If you don’t spend your days thinking about database consistency models, then this may sound arcane, but there’s a whole area of computer science that focuses on little else but how to best handle a scenario where two users virtually simultaneously try to change the same cell in a distributed database.
Unlike other databases, Cosmos DB allows for a variety of consistency models, ranging from strong to eventual, with three intermediary models. And it actually turns out that most CosmosDB users opt for one of those intermediary models.
Interestingly, when I talked to Leslie Lamport, the Turing award winner who developed some of the fundamental concepts behind these consistency models (and the popular LaTeX document preparation system), he wasn’t all that sure that the developers are making the right choice. “I don’t know whether they really understand the consequences or whether their customers are going to be in for some surprises,” he told me. “If they’re smart, they are getting just the amount of consistency that they need. If they’re not smart, it means they’re trying to gain some efficiency and their users might not be happy about that.” He noted that when you give up strong consistency, it’s often hard to understand what exactly is happening.
But strong consistency comes with its drawbacks, too, which leads to higher latency. “For strong consistency there are a certain number of roundtrip message delays that you can’t avoid,” Lamport noted.
The CosmosDB team isn’t just building on some of the fundamental work Lamport did around databases, but it’s also making extensive use of TLA+, the formal specification language Lamport developed in the late 90s. Microsoft, as well as Amazon and others, are now training their engineers to use TLA+ to describe their algorithms mathematically before they implement them in whatever language they prefer.
“Because [CosmosDB is] a massively complicated system, there is no way to ensure the correctness of it because we are humans, and trying to hold all of these failure conditions and the complexity in any one person’s — one engineer’s — head, is impossible,” Microsoft Technical Follow Dharma Shukla noted. “TLA+ is huge in terms of getting the design done correctly, specified and validated using the TLA+ tools even before a single line of code is written. You cover all of those hundreds of thousands of edge cases that can potentially lead to data loss or availability loss, or race conditions that you had never thought about, but that two or three years ago after you have deployed the code can lead to some data corruption for customers. That would be disastrous.”
“Programming languages have a very precise goal, which is to be able to write code. And the thing that I’ve been saying over and over again is that programming is more than just coding,” Lamport added. “It’s not just coding, that’s the easy part of programming. The hard part of programming is getting the algorithms right.”
Lamport also noted that he deliberately chose to make TLA+ look like mathematics, not like another programming languages. “It really forces people to think above the code level,” Lamport noted and added that engineers often tell him that it changes the way they think.
As for those companies that don’t use TLA+ or a similar methodology, Lamport says he’s worried. “I’m really comforted that [Microsoft] is using TLA+ because I don’t see how anyone could do it without using that kind of mathematical thinking — and I worry about what the other systems that we wind up using built by other organizations — I worry about how reliable they are.”
