
In May, Facebook teased a new feature called 3D photos, and it’s just what it sounds like. However, beyond a short video and the name, little was said about it. But the company’s computational photography team has just published the research behind how the feature works and, having tried it myself, I can attest that the results are really quite compelling.
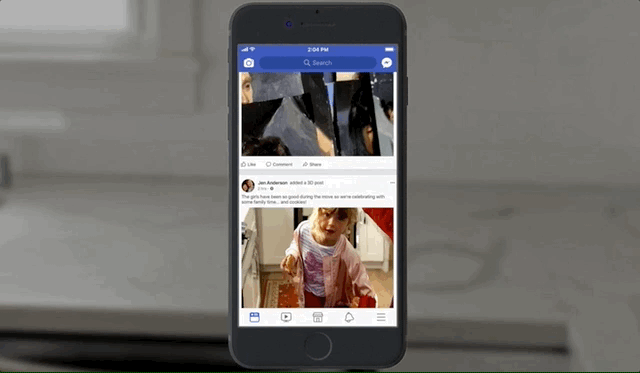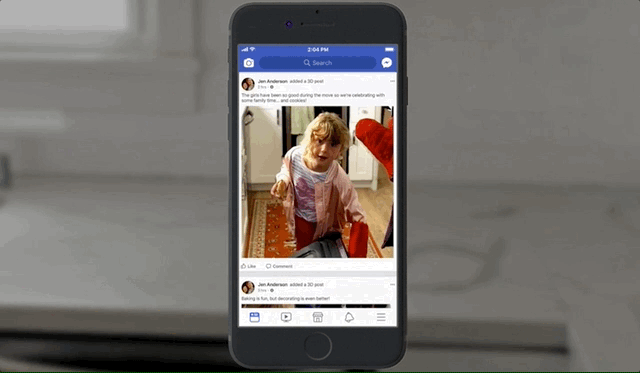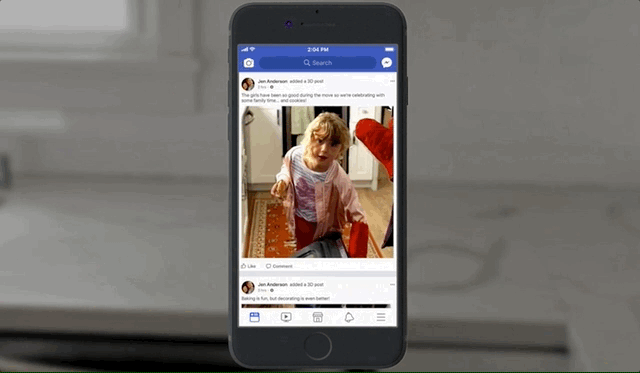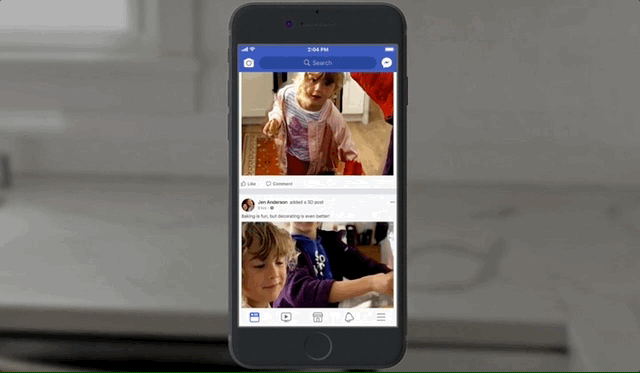
In case you missed the teaser, 3D photos will live in your news feed just like any other photos, except when you scroll by them, touch or click them, or tilt your phone, they respond as if the photo is actually a window into a tiny diorama, with corresponding changes in perspective. It will work for both ordinary pictures of people and dogs, but also landscapes and panoramas.
It sounds a little hokey, and I’m about as skeptical as they come, but the effect won me over quite quickly. The illusion of depth is very convincing, and it does feel like a little magic window looking into a time and place rather than some 3D model — which, of course, it is. Here’s what it looks like in action:
 I talked about the method of creating these little experiences with Johannes Kopf, a research scientist at Facebook’s Seattle office, where its Camera and computational photography departments are based. Kopf is co-author (with University College London’s Peter Hedman) of the paper describing the methods by which the depth-enhanced imagery is created; they will present it at SIGGRAPH in August.
I talked about the method of creating these little experiences with Johannes Kopf, a research scientist at Facebook’s Seattle office, where its Camera and computational photography departments are based. Kopf is co-author (with University College London’s Peter Hedman) of the paper describing the methods by which the depth-enhanced imagery is created; they will present it at SIGGRAPH in August.
Interestingly, the origin of 3D photos wasn’t an idea for how to enhance snapshots, but rather how to democratize the creation of VR content. It’s all synthetic, Kopf pointed out. And no casual Facebook user has the tools or inclination to build 3D models and populate a virtual space.
One exception to that is panoramic and 360 imagery, which is usually wide enough that it can be effectively explored via VR. But the experience is little better than looking at the picture printed on butcher paper floating a few feet away. Not exactly transformative. What’s lacking is any sense of depth — so Kopf decided to add it.
The first version I saw had users moving their ordinary cameras in a pattern capturing a whole scene; by careful analysis of parallax (essentially how objects at different distances shift different amounts when the camera moves) and phone motion, that scene could be reconstructed very nicely in 3D (complete with normal maps, if you know what those are).
But inferring depth data from a single camera’s rapid-fire images is a CPU-hungry process and, though effective in a way, also rather dated as a technique. Especially when many modern cameras actually have two cameras, like a tiny pair of eyes. And it is dual-camera phones that will be able to create 3D photos (though there are plans to bring the feature downmarket).
By capturing images with both cameras at the same time, parallax differences can be observed even for objects in motion. And because the device is in the exact same position for both shots, the depth data is far less noisy, involving less number-crunching to get into usable shape.
Here’s how it works. The phone’s two cameras take a pair of images, and immediately the device does its own work to calculate a “depth map” from them, an image encoding the calculated distance of everything in the frame. The result looks something like this:
 Apple, Samsung, Huawei, Google — they all have their own methods for doing this baked into their phones, though so far it’s mainly been used to create artificial background blur.
Apple, Samsung, Huawei, Google — they all have their own methods for doing this baked into their phones, though so far it’s mainly been used to create artificial background blur.
The problem with that is that the depth map created doesn’t have some kind of absolute scale — for example, light yellow doesn’t mean 10 feet, while dark red means 100 feet. An image taken a few feet to the left with a person in it might have yellow indicating 1 foot and red meaning 10. The scale is different for every photo, which means if you take more than one, let alone dozens or a hundred, there’s little consistent indication of how far away a given object actually is, which makes stitching them together realistically a pain.
 That’s the problem Kopf and Hedman and their colleagues took on. In their system, the user takes multiple images of their surroundings by moving their phone around; it captures an image (technically two images and a resulting depth map) every second and starts adding it to its collection.
That’s the problem Kopf and Hedman and their colleagues took on. In their system, the user takes multiple images of their surroundings by moving their phone around; it captures an image (technically two images and a resulting depth map) every second and starts adding it to its collection.
In the background, an algorithm looks at both the depth maps and the tiny movements of the camera captured by the phone’s motion detection systems. Then the depth maps are essentially massaged into the correct shape to line up with their neighbors. This part is impossible for me to explain because it’s the secret mathematical sauce that the researchers cooked up. If you’re curious and like Greek, click here.
{kind=link}
Not only does this create a smooth and accurate depth map across multiple exposures, but it does so really quickly: about a second per image, which is why the tool they created shoots at that rate, and why they call the paper “Instant 3D Photography.”
Next, the actual images are stitched together, the way a panorama normally would be. But by utilizing the new and improved depth map, this process can be expedited and reduced in difficulty by, they claim, around an order of magnitude.

Because different images captured depth differently, aligning them can be difficult, as the left and center examples show — many parts will be excluded or produce incorrect depth data. The one on the right is Facebook’s method.
Then the depth maps are turned into 3D meshes (a sort of two-dimensional model or shell) — think of it like a papier-mache version of the landscape. But then the mesh is examined for obvious edges, such as a railing in the foreground occluding the landscape in the background, and “torn” along these edges. This spaces out the various objects so they appear to be at their various depths, and move with changes in perspective as if they are.
Although this effectively creates the diorama effect I described at first, you may have guessed that the foreground would appear to be little more than a paper cutout, since, if it were a person’s face captured from straight on, there would be no information about the sides or back of their head.
 This is where the final step comes in of “hallucinating” the remainder of the image via a convolutional neural network. It’s a bit like a content-aware fill, guessing on what goes where by what’s nearby. If there’s hair, well, that hair probably continues along. And if it’s a skin tone, it probably continues too. So it convincingly recreates those textures along an estimation of how the object might be shaped, closing the gap so that when you change perspective slightly, it appears that you’re really looking “around” the object.
This is where the final step comes in of “hallucinating” the remainder of the image via a convolutional neural network. It’s a bit like a content-aware fill, guessing on what goes where by what’s nearby. If there’s hair, well, that hair probably continues along. And if it’s a skin tone, it probably continues too. So it convincingly recreates those textures along an estimation of how the object might be shaped, closing the gap so that when you change perspective slightly, it appears that you’re really looking “around” the object.
The end result is an image that responds realistically to changes in perspective, making it viewable in VR or as a diorama-type 3D photo in the news feed.
In practice it doesn’t require anyone to do anything different, like download a plug-in or learn a new gesture. Scrolling past these photos changes the perspective slightly, alerting people to their presence, and from there all the interactions feel natural. It isn’t perfect — there are artifacts and weirdness in the stitched images if you look closely, and of course mileage varies on the hallucinated content — but it is fun and engaging, which is much more important.
The plan is to roll out the feature mid-summer. For now, the creation of 3D photos will be limited to devices with two cameras — that’s a limitation of the technique — but anyone will be able to view them.
But the paper does also address the possibility of single-camera creation by way of another convolutional neural network. The results, only briefly touched on, are not as good as the dual-camera systems, but still respectable and better and faster than some other methods currently in use. So those of us still living in the dark age of single cameras have something to hope for.