YouTube has long had an automatic captioning system that, thanks to Google’s machine learning advances in recent years, has gotten pretty good at automatically transcribing spoken words in a video. As the company announced today, its technology is now able to take this a step further by also captioning some of the ambient sounds like [LAUGHTER], [APPLAUSE] and [MUSIC].
For now, the automatic effects captioning is actually restricted to those exactly these three sounds. The reason for this, Google says, is that these are also exactly the sounds that most video producers manually caption right now.
“While the sound space is obviously far richer and provides even more contextually relevant information than these three classes, the semantic information conveyed by these sound effects in the caption track is relatively unambiguous, as opposed to sounds like [RING] which raises the question of “what was it that rang – a bell, an alarm, a phone?,” Google engineer Sourish Chaudhuri explains in today’s announcement.
Now that Google has the systems in place to caption those sounds, though, it should be relatively easy to also caption other sounds.
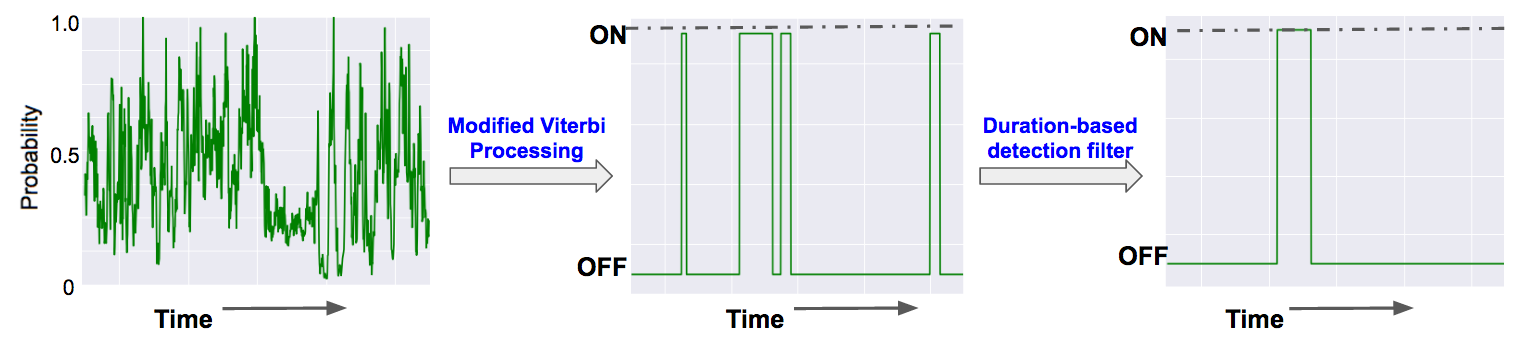
In the backend, YouTube’s sound captioning system is based on a Deep Neural Network model the team trained on a set of weakly labeled data. Whenever a new video is now uploaded to YouTube, the new system runs and tries to identify these sounds. For those of you who want to know more about how the team achieved this (and how it used a modified Viterbi algorithm), Google’s own blog post provides more details.