
Initially used to improve the experience for visually impaired members of the Facebook community, the company’s Lumos computer vision platform is now powering image content search for all users. This means you can now search for images on Facebook with key words that describe the contents of a photo, rather than being limited by tags and captions.
To accomplish the task, Facebook trained an ever-fashionable deep neural network on tens of millions of photos. Facebook’s fortunate in this respect because its platform is already host to billions of captioned images. The model essentially matches search descriptors to features pulled from photos with some degree of probability.
After matching terms to images, the model ranks its output using information from both the images and the original search. Facebook also added in weights to prioritize diversity in photo results so you don’t end up with 50 pics of the same thing with small changes in zoom and angle. In practice, all of this should produce more satisfying and relevant results.
Eventually Facebook will apply this technology to its growing video corpus. This could be used both in the personal context of searching a friend’s video to find the exact moment she blew out the candles on her birthday cake, or in a commercial context. The later could help raise the ceiling on Facebook’s potential ad revenue from News Feed.
Pulling content from photos and videos provides an original vector to improve targeting. Eventually it would be nice to see a fully integrated system where one could pull information, say searching a dress you really liked in a video, and relate it back to something on Marketplace or even connect you directly with an ad-partner to improve customer experiences while keeping revenue growth afloat.
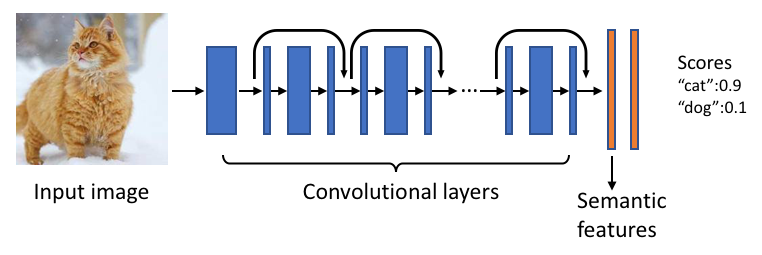
Basic structure of how object recognition works
Applying Lumos to help the visually impaired
Along with today’s new image content search feature, Facebook is updating its original Automatic Alternative Text tool. When Facebook released the tool last April, visually impaired users could leverage existing text-to-speech tools to understand the contents of photos for the first time. The system could tell you that a photo involved a stage and lights, but it wasn’t very good at relating actions to objects.
A Facebook team fixed that problem by painstakingly labeling 130,000 photos pulled from the platform. The company was able to train a computer vision model to identify actions happening in photos. Now you might now hear “people dancing on stage,” a much better, contextualized, description.
The applied computer vision race
Facebook isn’t the only one racing to apply recent computer vision advances to existing products. Pinterest’s visual search feature has been continuously improved to let users search images by the objects within them. This makes photos interactive and more importantly it makes them commercializable.
Google on the other hand open sourced its own image captioning model last fall that can both identify objects and classify actions with accuracy over 90 percent. The open source activity around TensorFlow has helped the framework gain prominence and become very popular with machine learning developers.
Facebook is focused on making machine learning easy for teams across the company to integrate into their projects. This means improving the use of the company’s general purpose FBLearner Flow.
“We’re currently running 1.2 million AI experiments per month on FBLearner Flow, which is six times greater than what we were running a year ago,” said Joaquin Quiñonero Candela, Facebook’s director of applied machine learning.
Lumos was built on top of FBLearner Flow. It has already been used for over 200 visual models. Aside from image content search, engineers have used the tool for fighting spam.