This guest post is written by David Sacks, the founder and CEO of new startup Geni. Previously, he was COO of PayPal. He also produced the movie “Thank You For Smoking.”
 For the last several years, Yahoo, MSN and AOL have all suffered a declining share of pageviews, but that does not mean the portal is going out of style. Rather it has been redefined, first by Google, and now by Facebook in potentially even more profound ways.
For the last several years, Yahoo, MSN and AOL have all suffered a declining share of pageviews, but that does not mean the portal is going out of style. Rather it has been redefined, first by Google, and now by Facebook in potentially even more profound ways.
The core question a portal needs to answer for a user is “How do I find the information I need?”
In the early days of the web, the answer was browsing, which made sense when there were a limited number of useful sites. (Remember when it was a big deal for Yahoo to put the “New!” or “Recommended” icon next to a website’s name in their directory?) But as the number of websites became infinite, search replaced browsing as the dominant paradigm for finding new sites, and Yahoo’s failure to keep up in this area allowed Google to take the lead.
Google has continued to leverage its lead in search to become a full-fledged portal. Once users have found what they are looking for, Google makes it easy, through their iGoogle product, to subscribe to that content through alerts, RSS feeds, or a huge selection of widgets, all of which are compacting more useful information onto fewer start pages than ever before. As a result, iGoogle has become Google’s fastest-growing product. But iGoogle has a serious limitation: it doesn’t involve sharing; each user has to make an individual investment in set-up and can’t benefit from the work of others. It’s not really a Web 2.0 product.
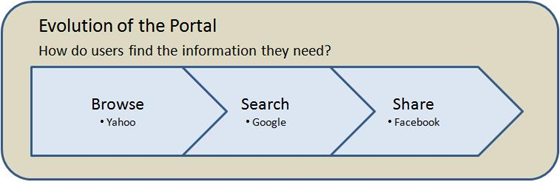
Facebook has a new answer to the portal question. The “social graph,” or your network of relationships, will push information to you. You’ll learn from your friends. Thanks to Facebook’s new developer platform, the types of information being disseminated now include not just news, photos, events, and groups but also music, videos, books, movies, causes, political campaigns — and the list is rapidly growing into almost every conceivable category.
The advantage of this approach is that it makes it relatively effortless for users to access a world of information that is both increasingly comprehensive and personal to them. Even if all this information were available through search (and it’s not), search actually requires work; the user must know what they’re looking for and type it in. Then they must parse the results to determine which are valuable, labor which is not shared and reused by others. By contrast, Facebook requires no work once your network is set up. Your friends push information to you that is likely to be useful, and if not you can tune your preferences until it is. Facebook promises a kind of Socratic knowledge: it tells users things they didn’t even think to ask.
While the process of structuring new kinds of information for the social graph to distribute is still sorting itself out, it is easy to object to the frivolity of information on Facebook. For example, Facebook is great at telling me what my friends just had for lunch, but how about hard news? Well, for starters, I’m waiting for the Digg application to not only display articles I’ve digged on my profile, but also to aggregate all the articles dugg by my friends. This could lead to the kind of social news site that MySpace promised but failed to deliver.
Not only Digg, but virtually all Web 2.0 applications which are based on the wisdom of crowds can be reconceived as Facebook apps based on the wisdom (or trust) of friends. To the extent that these services cater to publishers who seek a mass audience, such as YouTube or Flickr, the social graph will not threaten their business. But to the extent they publish content intended for friends, or if the value of their service increases with the participation of friends, these applications face only two choices: get each user to recreate his or her friendship network on their own site or migrate their service to the Facebook platform lest someone else does it first.
The potential for Facebook to layer on any feature whose value increases with the participation of friends is an incredibly broad canvas for a portal. Moreover, as each new application gains acceptance, it enriches the overall value of the network and makes it incrementally more likely that the next application will be tried. Much of what we know as “Web 2.0” will eventually be rebuilt on top of Facebook.
To be clear, the social graph will not replace search, in the same way that search did not replace browsing. And search may still be more easily monetized than the social graph. Still, as a basis for a portal, neither Google nor Yahoo has anything nearly as cohesive holding its properties together. Google can layer on any feature where search is paramount, which is hugely valuable, but as it expands beyond this core competency, it becomes increasingly hard to press its advantages into new areas. Yahoo already seems to have reached the limits of its far-flung empire, eliminating redundant operations such as Yahoo Photos.
In my view this is a misdiagnosis of what ails Yahoo. The problem is not too much peanut butter (i.e. that it’s spread too thinly). The problem is the bread at the core. Browsing plus second-tier search is not sturdy enough to hold everything together. The new portals are defined by the quality of their bread, not their peanut butter.
Yahoo was right to focus on an acquisition of Facebook but not for the reason it thinks. In its view of the world, Facebook is just another media property, a particularly fast-growing and sticky one to be sure, but ultimately just more peanut butter. In reality, Facebook’s social graph could have provided the bread to connect Yahoo’s far-flung empire.
But what would be in such a deal for Facebook? They will have their own empire soon enough.
Find out more about Geni at the Techcrunch Database.