
With Strata + Hadoop World kicking off, it’s always fascinating to step back and look at the contents of the sessions as a way of understanding what’s happening in the world of big data.
For those of you who have attended this conference for the more than five years that the event’s been kicking, you’ve likely seen it transform from an arena for software developers experimenting with open-source technologies to one of the more important enterprise software conferences — where a mix of developers, executives, vendors and professional services providers come together to share and learn about the most recent developments in the space.
As a quick way of trying to figure out “What’s Hot” at this year’s conference in San Jose, I did a quick (and extremely unscientific) analysis of the top terms that showed up in the list of training classes, keynotes and presentation sessions throughout the week. After filtering out the obvious terms (Hadoop, data, analytics, Apache), there were some clear topics that rose to the top, as shown below:
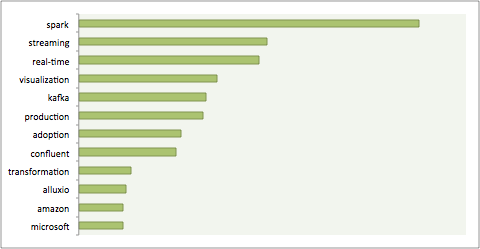
There are a few key things that jump out after looking at this particular view of the data that I suspect indicate key trends that are happening in the industry overall.
Spark Adoption and Interest Continues to Grow: While Hadoop adoption is still several years ahead, Spark’s growth in the big data ecosystem has been significant. Both technologies are here to stay, with Spark being adopted for a broad set of use cases, including pipelined data processing and parallelizable data-science workloads.
Streaming and Real-Time Are “The Next Big Thing”: In the chart above you will see terms like “streaming” and “real-time” along with “kafka” and “confluent” (a commercial distribution of Kafka). Now that enterprises have had success with batch loading and processing of data in their production Hadoop clusters, there is increasing focus on real-time data ingestion, processing and analysis.
Visualization Is Still Important: As AtScale’s Hadoop Maturity Survey revealed, enterprises are more focused on rolling out Business Intelligence use cases on Hadoop, ahead of investing in data science (despite the continued media assertion of how sexy data science is). Data visualization and self-service remain a key investment area, even in the world of Hadoop.
SQL-on-Hadoop Has Entered the Mainstream: Notably missing from the top terms and topics at Hadoop World is SQL-on-Hadoop. In previous years, starting with Hive and moving on to projects like Impala and SparkSQL (along with a number of other commercial SQL-on-Hadoop products), there was intense focus on these technologies. But SQL-on-Hadoop has become a “must have” in the Hadoop toolkit and has entered the mainstream. As our recent BI-on-Hadoop Benchmark revealed, these engines are now ready to support large-scale analytical SQL workloads.
In Memory Substrates… The Next Optimization?: An interesting item that made the top terms list is “alluxio,” which is the recently renamed Tachyon project. Alluxio is a virtual distributed storage system, and it has a memory-centric architecture that enables data sharing across clusters at memory speed. For SQL-on-Hadoop engines, this can mean faster query times and increased performance, as experienced by Baidu as they adopted Alluxio to speed up their analytical data processing.
Hadoop Adoption Remains Top of Mind: “adoption” and “production” make the list: Many IT organizations have made big bets on Hadoop as their next-generation data platform, and are migrating workloads from legacy systems like Teradata to lower-cost and more scalable environments. For these organizations it is critical to show their Hadoop investments paying off in the form of production clusters being adopted by core business functions, such as Business Intelligence.
Don’t Ignore Big Data in the Cloud: Amazon and Microsoft both show up on the list. Despite a slow start in the Hadoop space, Microsoft is making significant inroads in the big data space, offering services like HDInsight (which is available to run on Linux!). Amazon continues to make great strides with their big data offerings, with the ever-increasing adoption of Redshift complementing already popular services like S3 and EMR (Elastic MapReduce).