
Piston Cloud Co-Founder Joshua McKenty says the OpenStack customer ecosystem has four emerging market segments. On one side are the customers who hire consultants to build them a cloud. On the other side are the IBM customers who will always be IBM customers.
And in the middle are two classes of customers who have one thing in common, McKenty said. They have a data problem and with that comes deeper interest in the infrastructure, be it their own or a third-party that manages it for them.
In one camp of this middle market are the customers who want a more enterprise-grade agreement, McKenty said. They want reliability and durability in the virtual machines they run. In the other camp are the companies with SaaS or cloud apps that are seeking more than what AWS offers.
Realistically, AWS is in fine shape and will continue to dominate. They were the first to step ahead and provide services that abstract the complexity of managing data. Their place in the market is solid and will remain that way for some time to come.
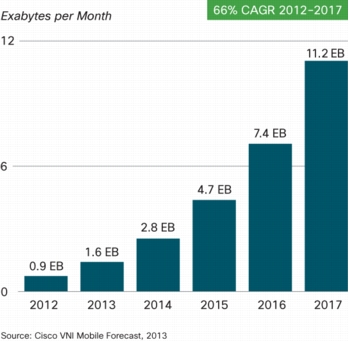
More important? As data becomes a growing problem, so will the interest in open cloud technologies. For example, Cisco projects a 66% compound annual growth rate in mobile traffic between 2012 and 2017.
Customers that grow wildly will see a better value in moving off AWS. Others will want better service level agreeements and more control over their data. Those companies will move off AWS, too.
The DevOps movement will continue to help companies like Puppet Labs and Opscode prosper as more companies look to process more data and get better productivity while keeping heasd counts low. It’s just a complete change that will shift the trillion dollar IT budget toward the open cloud.
IBM, AT&T, HP, Red Hat — all of these companies are investing in the open cloud to help companies deal with the new realities of the data world. Customers have to consider that to grow they will need to analyze data to be more predictive and more so, just develop better ways get their work done. Managing terabytes of data will be the norm. Customers will have to think about how data moves around and syncs to different devices, be it a smartphone or a tablet. It will mean adopting open-source analytics technologiies such as Hadoop and considering how to extend the infrasrtructure at minimal cost.
As a result, open cloud movements are emerging that will help create this dream of the “federated cloud,” that my colleague Krishnan Subramanian has written about:
To me, handful of cloud providers serving the world’s computing needs is a shortsighted idea. The needs of the world are diverse and even the regulations are diverse. Handful of cloud service providers cannot satisfy these needs and requirements. Also, I would consider it as a dangerous idea to begin with. We saw the impact of monopoly in traditional software days and people in US are seeing the impact of small number of telecom providers controlling the wireless market. The idea of consolidation is for people who believe in the principle of economics of scarcity and, as someone who is from open source background, I see value in the economics of abundance. I see competition through abundant participation in the market, rather than consolidation, as the correct realization of capitalistic ideals.
It’s just a matter of cost in many respects. A small provider in India will want to connect into an open cloud service. Why not? It will give their customers a more effective way to compete with the data that they have and can access.
Just looke at the Open Compute Project . Facebook started it when they were looking at building out its data center in Prineville, Or. The hardware they wanted had to be invented themselves. So they helped get Open Compute up established. Developers and engineers have been showing up in droves, hacking new ways to create servers and now network switches that are cheap and can run on processors that you’d find on a smartphone.
There’s also the Apache Foundation’s Cloudstack, Open Nebula and other communities which are all fostering community development. Data analysis by Eucalyptus Director of Customer Service Qingye Jiang shows how the open cloud movement is growing as the market adapts to a data intensive world.
The open cloud market is far larger than any of these groups. And it’s the shift in thinking about data that will increase its size. These open organizations will play a vital role as they represent affordable and production-ready systems for building up clouds.
The discussion about open cloud ecosystems reminds me of a conversation I had earlier in the week with Brinqa CEO Amad Fida. Brinqa uses a NoSQL graph database to do risk analysis for customers. Fida said Splunk indexes machine data for search. Brinqa offers context to machine data so customers can build models that help them make decisions that don’t rely on guessing.
I asked Fida how data is changing customers’ perspectives about their businesses. He said it’s evident that data is causing customers to think more about the infrastructure they run. They are doing more analysis to determine where they keep their data and the data center operations required to process it.
As customers use more data, they will seek ways to make the process more efficient, which in turn will further force a cultural change that marries developers and operations, McKenty said. That’s Pistion’s big push as evident in its latest 2.0 release.
Apps will scale out, the storage needs will magnify and networking will become more defined by software that is virtualized and optimized to run across not just data centers but endless sensor networks embedded into our homes and everything we know of.
A proprietary cloud stack like AWS can only have so much appeal in such a scale-out world. McKenty argues that they are seeing customers like Hubspot move off AWS to create their own virtual infrastructure. These are companies that want more fine-grained control than they can get with AWS. They want better support contracts, as AWS is primarily a self-service vendor. If they think they need SSDs they want to add what they think is best instead of leaving it to AWS to deploy.
Data is changing the world. That’s what is fueling the open cloud movement and will guarantee its success. We are starting to push and pull data from everything we know of. And now we are learning how to process it and turn it into digital goods. How we do that is one of the biggest questions of all.