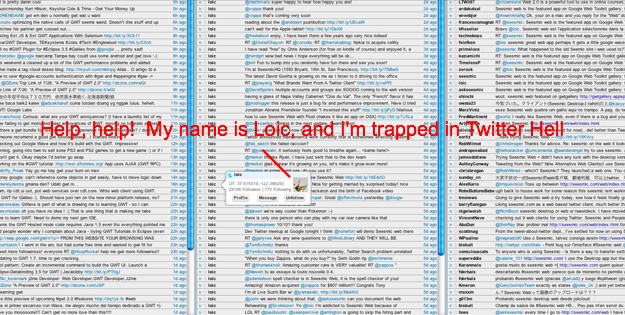
A few days ago, Seesmic CEO Loic Le Meur (@Loic) sent out a retweet with a link to a screenshot of his CTO’s Seesmic Web client showing 1,200 Tweets across nearly 20 columns. The joke was that his CTO was trying to achieve a “world record” for how many Tweets could be loaded up into a Twitter client at one time. (It’s not a world record. Competitor TweetDeck can display an unlimited number of Tweets and columns as well). If you click on the screenshot and pan across the enlarged version of it, there you’ll find a dialog box with Loic’s old avatar doing a hang-10 while kite surfing. The juxtaposition is comical, if a little sad—poor @Loic lost in the overflowing stream of Tweets his company is trying to tame.
{kind=link}
The image reminded me of another screenshot (see below, click to enlarge) that I once took of an earlier Twitter client called Twhirl, which Seesmic bought before developing its current product. About a year and a half ago, I complained that Twhirl took over my desktop when I first installed it with a constant stream of pop-up messages. I wrote in that post:
This highlights a bigger problem with the Web today. There is too much to pay attention to and not enough ways to reduce the noise.
It’s 18 months later and the problem hasn’t been solved. The screenshot I took back then still resonates because the noise is worse than ever. Indeed, it is being magnified every day as more people pile onto Twitter and Facebook and new apps yet to crest like Google Wave. The data stream is growing stronger, but so too is the danger of drowning in all that information.

This is not to say that there hasn’t been considerable progress in stream readers since that time. Containing 1,200 Tweets within neatly defined columns is definitely better than 1,200 separate dialog boxes taking over my screen, and these apps today are much more able to handle massive amount of messages. But the fact that Seesmic or TweetDeck or any of these apps can display 1,200 Tweets at once is not a feature, it’s a bug. Again, what I said 18 months ago is just as true today:
I need less data, not more data. I need to know what is important, and I don’t have time to sift through thousands of Tweets and Friendfeed messages and blog posts and emails and IMs a day to find the five things that I really need to know.
One the main methods emerging to cut down noise in your personal stream is to set up different groups of people or keywords (via search) to follow. Twitter is going to tackle this problem with its new “lists” feature. Seesmic and TweetDeck already address this problem by creating a new column for every group or category you want to follow.
But as the image above makes clear, that strategy breaks down fairly quickly. I have ten columns in my TweetDeck, for instance—one for my personal Twitter account, one for the TechCrunch account, one for my Facebook stream, one for mentions of “techcrunch”, another for mentions of my name (so I can respond to people trying to talk to me whom I don’t follow), another two columns for direct messages, and so on. I rarely look at more than two columns. It’s just not an efficient way keep track of all my different interests in the stream.
And if you think Twitter is noisy, wait until you see Google Wave, which doesn’t hide anything at all. Imagine that Twhirl image below with a million dialog boxes on your screen, except you see as other people type in their messages and add new files and images to the conversation, all at once as it is happening. It’s enough to make your brain explode.
What these services should strive to do instead is hide the noise, keep it simple. Letting me sort through the stream by creating different groups and lists and columns of things and people I want to pay attention to is great, but it hardly solves the problem. Finding that one great Tweet from @Loic or anyone else I follow shouldn’t be a game of Where’s Waldo?
Really, all I need is two columns: the most recent Tweets from everyone I follow (the standard) and the the most interesting tweets I need to pay attention to. Recent and Interesting. This second column is the tricky one. It needs to be automatically generated and personalized to my interests at that moment.
It would definitely include the most retweeted messages from people I follow over the past 24 to 48 hours because I miss these things during those hours when I am not staring at the stream. (And I stare at my stream more than most people). It would also prioritize tweets from people I follow based on who I pay attention to the most, based on my past history of retweeting, replying to people, or simply lingering over a Tweet while I’m reading. Look at my behavior, and then create a favorites list of sorts out of that.
And if those two columns aren’t enough, then there’s always search. Except search is broken on Twitter. Unless you know the exact word you are looking for, Tweets with related terms won’t show up. And there is no way to sort searches by relevance, it is just sorted by chronology. Maybe Twitter can use some of its $100 million in new funding to fix that, and solve the noise problem while it’s at it.