
About a week ago we soft-launched a new search engine for TechCrunch, the first to be built and deployed using Yahoo’s new BOSS Custom technology (otherwise known as “BOSS vertical lens”, as Yahoo called it in its announcement today).
The new TechCrunch Search is considerably more powerful than WordPress’s default search capabilities. For one, you can now search across our entire network of English-speaking blogs (which includes CrunchGear, MobileCrunch, TechCrunch UK, TechCrunchIT, Gillmor Gang and others in addition to TechCrunch) with just one query. Results also include pages from CrunchBase about notable companies, people, and financial organizations in the technology sector. And perhaps most crucially, results are no longer listed in dumb reverse chronological order but actually rise to the top based on their relevance to your query (Yahoo’s relevance model, however, has indeed been tuned to highlight our freshest content about particular subjects, such as the iPhone or Facebook).
The improvements don’t stop at better breadth and relevancy. The new user interface features an image for each result (when available), making it easier to identify posts visually. If you search for the name of a company, person or financial organization (such as Sequoia Capital or Jerry Yang), a specially formatted result at the top of the page will guide you to information about them in CrunchBase. And if you conduct a search that yields a lot of results, we have advanced search options that will help you narrow in on just what you’re looking for.
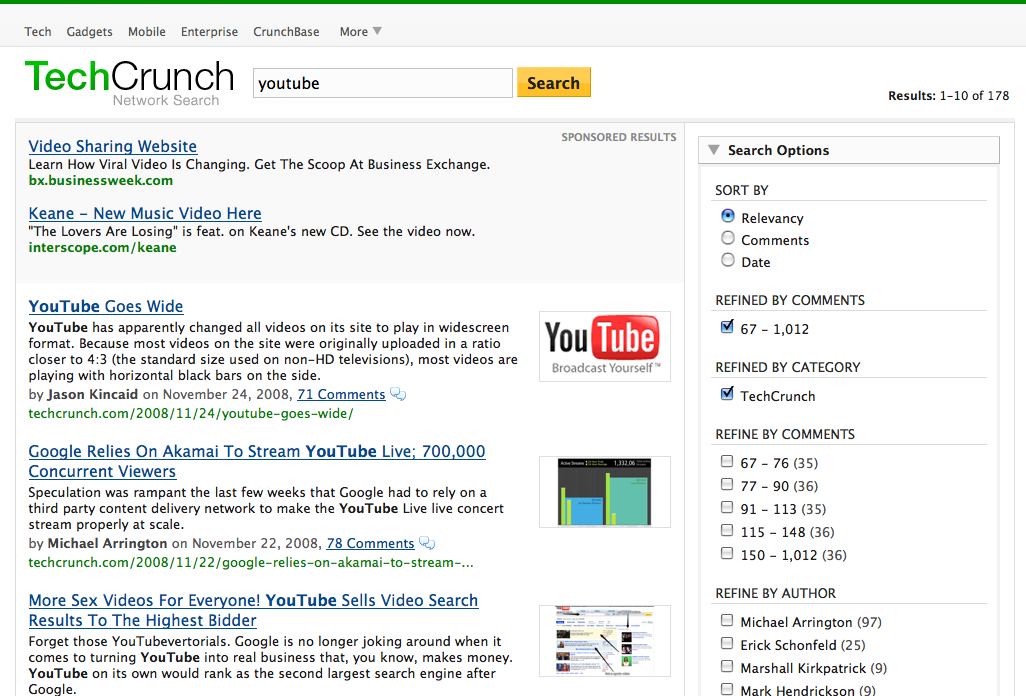
These new search options reflect some of Yahoo BOSS Custom’s strongest suits. Because we manually feed our blog and CrunchBase data to Yahoo using an XML-based API, we have the ability to associate any type of information (such as author name and number of comments) with each result. The search options leverage this meta data by allowing users to filter the results by certain criteria. For example, you can choose to view only results about “microsoft” by Michael Arrington that have at least 94 comments. Or you can decide to see what John Biggs has to say about the hottest new watches on CrunchGear.
BOSS can also be used to incorporate results from elsewhere on the web. When you conduct a search that doesn’t turn up many results from within the TechCrunch network, Yahoo backfills the pages with results from elsewhere on the web. These are essentially the same results you’d find by searching with Yahoo’s main search engine, except they are provided conveniently at the end of our own. Sponsored results from across the web are also displayed, allowing marketers to reach out to our visitors with products and services that are relevant to their search queries.
Setting up this new search engine was a much more hands on experience than, say, installing something like Google Site Search. For one, the Yahoo BOSS Custom technology is intended for developers, not those looking for an out-of-the-box solution. BOSS Custom consists primarily of two XML-based APIs: one that we use to supply data from our sites to Yahoo in real-time, and one that we used to construct our search’s user interface.
Since we publish using WordPress, supplying our data using the first API essentially required that we design and deploy a plugin that would send information to Yahoo’s servers every time there was a new post or comment on any of our blogs. We also needed to create a similar data indexing system for CrunchBase so that contributions there would show up in the results as well. To ensure that all of our archived content was incorporated in the search index, we supplied Yahoo with historical data dumps from all 10 sites. Perhaps needless to say, this took a considerable amount of time just to ensure that the data we indexed at Yahoo was accurate and complete.
Once the data from our sites was synchronized with Yahoo’s servers, we built out the search interface from scratch using the XML returned by Yahoo’s other API. This API takes the user’s search term and returns data about the corresponding results, such as titles, URLs and descriptions. It also returns meta data about the results such as their ordering and refinement options. Our search front-end parses and processes the XML to display the user interface seen by the end user. The creation of this front-end, too, took a significant amount of time since all of the pieces needed to work together in all query scenarios.
Development proceeded over the course of several months after the initial idea was floated last Spring. Granted, it didn’t take several straight months of development time since there were gaps in between when attention was paid to other projects. However, in aggregate, it consumed about 4-8 weeks of focused attention by two developers, suggesting that Yahoo BOSS Custom projects require a considerable amount of technical resources.
Given how much time and effort it took, why didn’t we just roll out Google Site Search in the matter of a few days? Simply put, Yahoo BOSS is a more flexible and professional solution. Data gets indexed in near real-time, so there’s no waiting for search engine bots to re-crawl your site. We have the ability to associate non-standard data, like images and number of comments, with the results and then display that data in any way we desire. Users can filter the results by criteria instead of simply accepting the default search scope. We can assign arbitrary boosts to results, ensuring that they show up on top whenever certain search terms are used (see “layoffs” for our Layoff Tracker, as an example). And we can blend a variety of result types, such as blog posts and CrunchBase pages, serving them up in ways that make the most sense for our readers.
We are continually working to improve TechCrunch Search, so please drop us a note with suggestions and bug reports.