By Clement Delangue, CEO of Hugging Face
Clement Delangue is the co-founder and CEO of Hugging Face, a startup focused on natural language processing that has raised more than $20M. The company created Transformers, the fastest growing open-source library enabling thousands of companies to leverage natural language processing.
Satya Nadella, the CEO of Microsoft, shocked the machine learning world when he tweeted about Microsoft’s newly released 17-billion parameter language model, pre-trained on NVIDIA GPUs:
The significance of the CEO of one of the largest companies in the world publicly talking about natural language processing (NLP), the field of artificial intelligence which applies to text, didn’t go unnoticed. For many, it came as proof that the field many considered obscure just a few years ago was finally in the spotlight as a critical technology for a juggernaut like Microsoft and many other tech companies. Let’s explore how this happened.
Text is central both in individual lives and in every single company.
Take some time to think about what you did today and you will realize that most of your time was spent in natural language, which means in unstructured text, either written or spoken. Whether you communicated with your friends, family, or colleagues, through emails, sms, calls, or in-person, it was in natural language. Whether you looked for information, read about the news, checked product reviews, finished a book, or listened to a podcast, it was in natural language. Even for visual activities, natural language is still relevant. Think of TV shows that wouldn’t make sense without the dialogue or Instagram pictures that get their context from captions. Natural language, or text, as the interface of humans, is everywhere.
Image Credits: NVIDIA
Now think about any company in the world and you will realize that they are built around text. From sales, customer support, customer reviews, comments, internal collaboration, spam detection, auto-complete, product descriptions — the use of text is never ending. Every aspect of a business is centered around language and text.
Image Credits: NVIDIA
If text is so important, the follow-up question is: why has technology failed to keep up with the scope at which natural language is used? If you take a look at a customer support or sales department, these are not considered technology-intensive departments. Instead, for most companies’ customer support or sales departments to grow, they hire more people. This eventually leads to a large amount of resources being used to staff call centers, both in-house and offshore.
The reason is because, for the longest time, natural language processing just didn’t work well enough. From keyword-based to linguistic approaches, NLP proved too limiting to bring significant value. It was impossible for technology to understand the nuances of language. Because human beings are extremely good at understanding natural language, we tend to under-estimate how difficult it is for machines to do the same. Babies pick up language naturally without anyone teaching them any explicit rules or syntax, but translating the innate nature of understanding a language to machines has been an unsolvable challenge for decades. The best we could do was to store <text> in a database, as a complete blackbox to technology. Human beings were the only ones able to understand it.
At least, until something happened in the science world of NLP.
NLP has made more progress in the past three years than any other field in machine learning.
In 2017, few people noticed the release of the paper ‘Attention is all you need’ (Vaswani et al, 2017), coming out of Google Brain. It proposed a new network architecture, called the Transformer, based solely on attention mechanisms. It would change the field of NLP forever.
Directly inspired from the paper, BERT, or Bidirectional Encoder Representations from Transformers, was released a year later. It was added to the Hugging Face transformer library and proved to become the most popular of the modern NLP models. BERT was made possible by two major trends. Firstly, hardware has gotten exponentially better, especially GPUs. Leading companies like NVIDIA have made compute not only cheaper, but also more powerful and more accessible.
Previously, only large companies with special hardware were able to process the high levels of computing power needed to train such language models. Second, the web, mostly composed of text, provided a large, open and diverse dataset. Sites like Wikipedia and reddit provided gigabits of text written in natural language, which allowed these gigantic models to be properly trained.
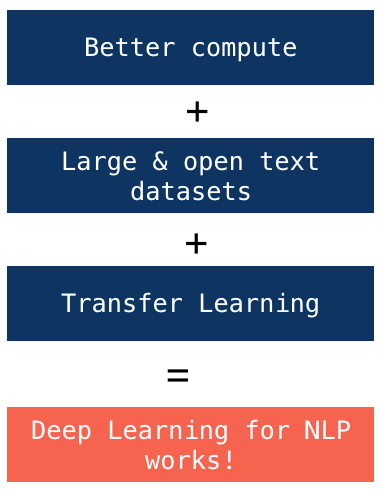
Image Credits: NVIDIA
These trends led to the emergence not only of BERT but of tons of similarly architected transformer models like GPT-2, RoBERTa, XLNet, DistilBERT and others. These models consistently elevated the state of the art, one release at a time. For example, on SQuAD, the Stanford Question Answering Dataset, which evaluates a model’s ability to answer questions from Wikipedia articles, the state-of-the-art EM(Exact Match) score went from 70 to almost 90 in just six months.
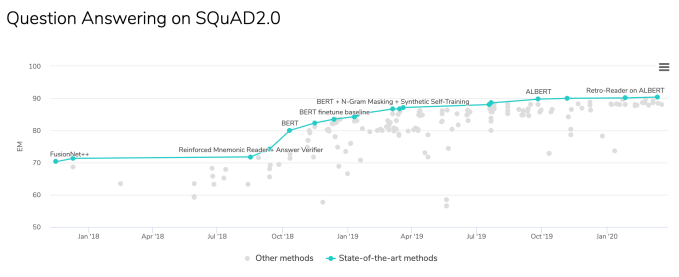
Image Credits: NVIDIA (opens in a new window)
Interestingly, this progress didn’t apply to just one type of task like question answering, but across the board to almost every single NLP task. These models learned sufficient general knowledge of language to perform well on a huge range of NLP benchmarks. For example, the GLUE (General Language Understanding Evaluation) benchmark, which evaluates models on a collection of tasks, was topped right away by BERT. In just a year, models were surpassing human baselines.
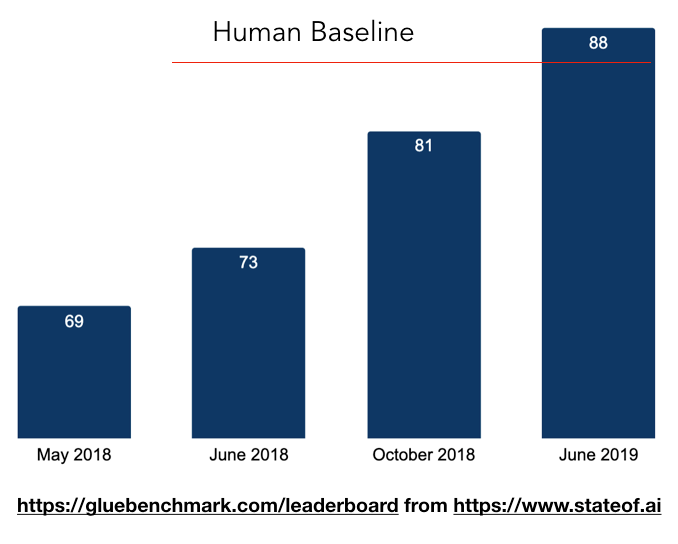
Image Credits: NVIDIA
That’s when companies started to notice!
“This is the single biggest … most positive change we’ve had in the last five years and perhaps one of the biggest since the beginning.” Pandu Nayak, Google fellow and VP of search, about adding transformer models in production at Google.
Scientific breakthroughs are known to be difficult and to take time to bring value to companies. However, something different happened with NLP. By hiding the scientific complexity of these models behind easy-to-use abstractions, the emergence of libraries like Transformers and Tokenizers by Hugging Face has empowered companies to adopt these new models faster than anything we have seen before. The libraries have been some of the fastest-growing open-source products ever seen.
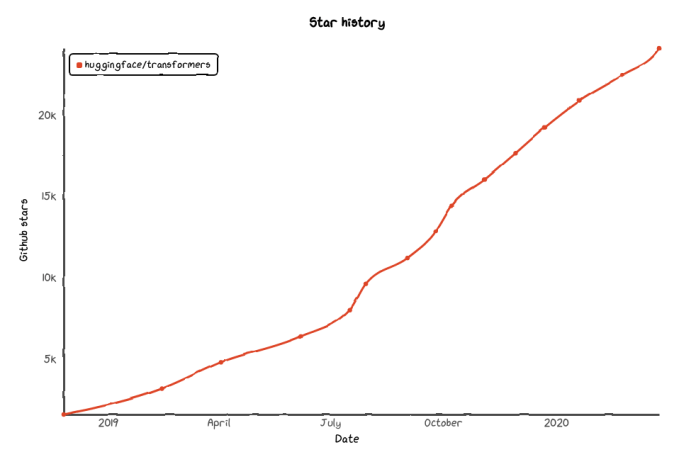
Image Credits: NVIDIA (opens in a new window)
In addition, the democratization of GPUs by companies like NVIDIA enabled companies to train models such as NVIDIA’s BERT (an optimized version of the Hugging Face implementation), BERT-Large, Transformer, and Bio-BERT at larger scales on custom data and on whatever tasks needed to generate a higher return on investment. Finally the rapidly evolving ecosystem of production-ready technologies with tools like TensorRT has made it easier than ever to run at scale.
Let’s take a look at some real-time NLP use cases.
The earliest use has been on the NLP task of predicting next words or sentences. Many people use it every day on Gmail: it’s the ability to suggest different autocompletions of your sentences or your email subjects. More creative tools like Write with Transformer or Talk to transformers have similar capabilities:
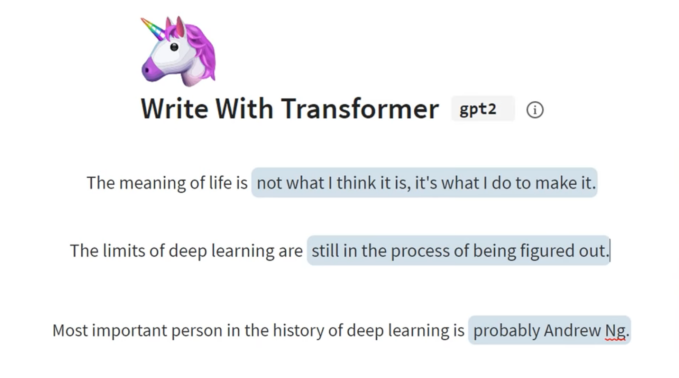
Image Credits: NVIDIA
For search giants like Bing or Google, transformer models are now being used both to rank results but also to provide rapid answers to questions by scanning the first page of results and finding where the answer is most likely to be:
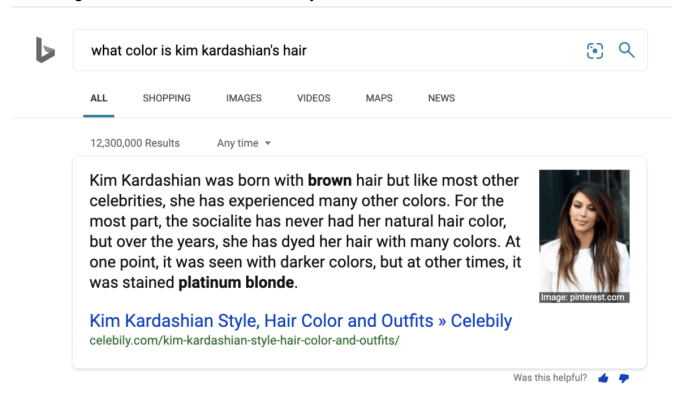
Image Credits: NVIDIA
Another popular application that proved useful has been text classification. For example, Monzo, the UK neobank, is using transformers to classify customer support emails based on their priority or the topics they refer to. Coinbase, a cryptocurrency exchange is using transformers to detect fake news. Other companies are using NLP to extract information, generate summaries, respond to customers, and much more — some on more than 10,000 text documents a second.
In just two years since the release of BERT in 2018, it has become one of the fastest adopted corporate technologies, ranging from startups to the Fortune 500. And the possibilities of using it in production are endless. Companies that are able to utilize NLP technology will find themselves able to grow and scale much more efficiently than before because they will be able to reduce their reliance on humans to understand text.
Over the next few months and years, we’re excited to see how NLP continues to influence companies, both in the technology space and outside of it. With machines now able to understand language better than ever before, Satya Nadella’s words become relevant once again: NLP will continue to “transform how technology understands and assists us.”
If you or your company are interested in learning more about implementing and adopting AI for your business, NVIDIA’s GTC Digital online conference will publish many talks and workshops by NVIDIA experts and others throughout the industry. You can also learn how to leverage conversational AI by watching our session Building a Smart Language-Understanding System for Conversational AI with HuggingFace Transformers. You can register for free here.