
Developing a fast-scaling business with a supply side in the early stages requires growing with high dynamics and little resources. Operational mistakes while scaling might have an exorbitant price.
We faced it when we decided to break into edtech and launch an education app that aims to provide experts the ability to answer millions of students’ requests in an online chat, almost instantly.
We started with a team of 20 people, which was enough to cover the demand in the early stages. To make the business profitable, the real race started: The marketing team had to scale the number of users, while operations had to follow their pace and grow the supply side.
We scaled demand without considering team resources.
We got up to speed quickly: 120+ experts were solving 3,000+ math tasks daily. We staked on the high pace to survive on the market, so the operations team was scaling the supply side by leaps and bounds.
We concentrated on scaling and didn’t have time to think if the resources of our team were enough to keep going with such speed.
Our marketing scaled rapidly, which was a good thing. Following the need to cover the increased demand from the users’ side in time, my team scaled the supply side 3x in one and a half months and 2x again two months later. Finally, we got 300+ math experts who were able to solve 10,000+ tasks daily. I was proud, thrilled, and freaking out at the same time.
I realized that in the last five months, our supply had worked on demand covering, time of service delivery, and quality of solutions. We concentrated on scaling and didn’t have time to think if the resources of our team were enough to keep going with such speed.
As a leader, I had to stop and look at the bigger picture.
The five-step plan I crafted to prevent the approaching “catastrophe”
1. Noted all the key processes “as they were”
This is a first step that shouldn’t be missed.
It is a common problem when there are no process notations. The work pace might be high, and people must implement tasks and solve issues immediately rather than describe the current process.
I described all the processes for that moment just as they were. It helped me understand the real point where we were at that moment. I figured out which things went out of control and might result in a big issue soon.
Afterward, all the processes were updated according to the following framework:

Image Credits: Julia Ivzhenko
2. Identified all the bottlenecks
I noted two types of bottlenecks:
First: Subprocesses, which were spontaneously added to key processes while scaling.
I discovered that due to the number of updates, my team members had to do too many additional actions, which were not noted before. Thus, I reviewed everything we did and simplified the general process. We focused only on “must-do” things, which influenced the result the most and put other “nice-to-do” tasks on hold.
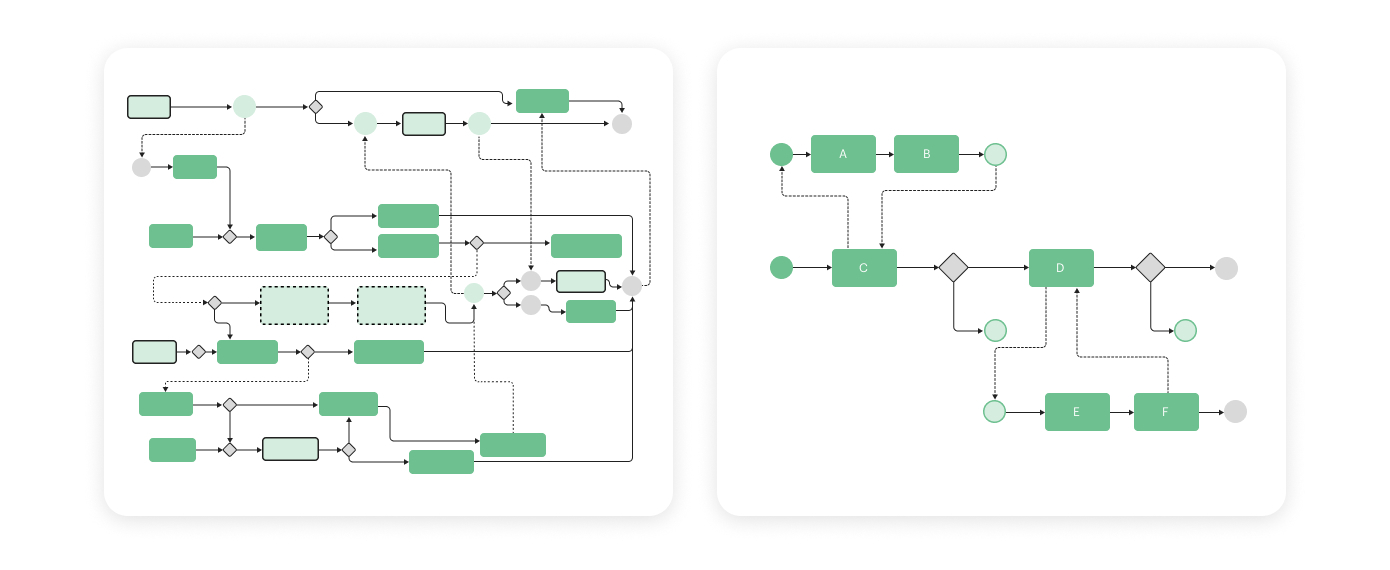
Image Credits: Julia Ivzhenko
Second: Managers, who didn’t delegate tasks in time and stuck with an enormous number of tasks.
Unfortunately, I was one of them. I was doing too many things at the same time, and they never came to an end. In my case, it happened primarily because of hiring mistakes, which appeared to be the most expensive ones.
After realizing that, I decided to fire people who didn’t stand up to performance expectations and stopped wasting time on explanations, additional instructions, and second chances. I focused on hiring the right people with proven experience who would strengthen the team.
3. Compiled the list of “Critical 1” and “Critical 2” issues
I decided to move according to the priority: from the most significant issues to the smallest ones.
Our key processes are built around three areas at supply: mass hiring of math experts, onboarding, and performance tracking. There was a time when onboarding for experts was stuck, thus making the hiring process stuck and bringing a mess into performance tracking. After fixing a critical issue with onboarding and making sure new experts joined the supply, we could figure out a new number of experts to hire and the total number of experts, whose performance should be tracked.
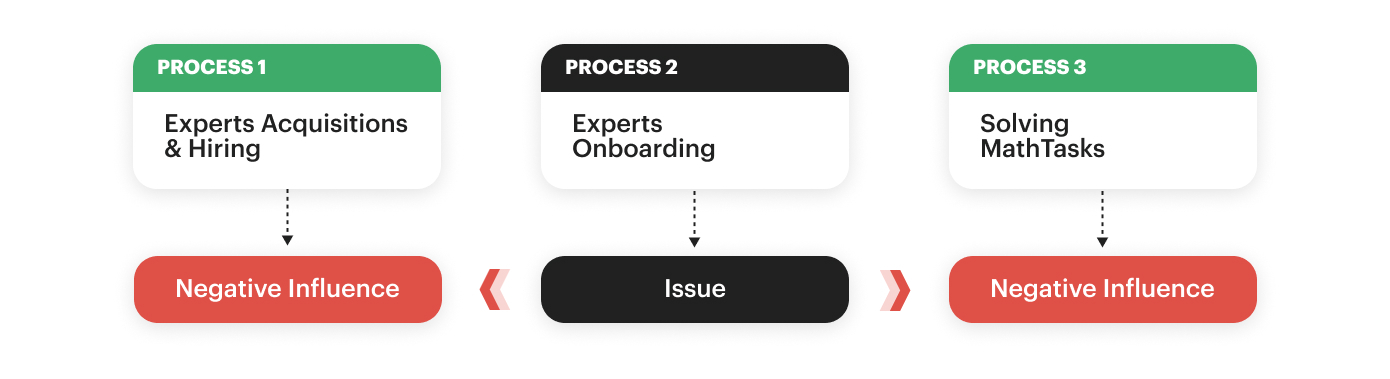
Image Credits: Julia Ivzhenko
4. Reviewed all the ops processes and made an optimization plan
I divided all the processes into two optimization types:
First: I redesigned the team structure, roles, functions, and workflow.
Most of my team members were doing multiple tasks, which referred to different processes.
It was okay when we had just launched the supply side. As the number of suppliers grew, we needed to set each team member’s work around one big process and take responsibility for a final result.
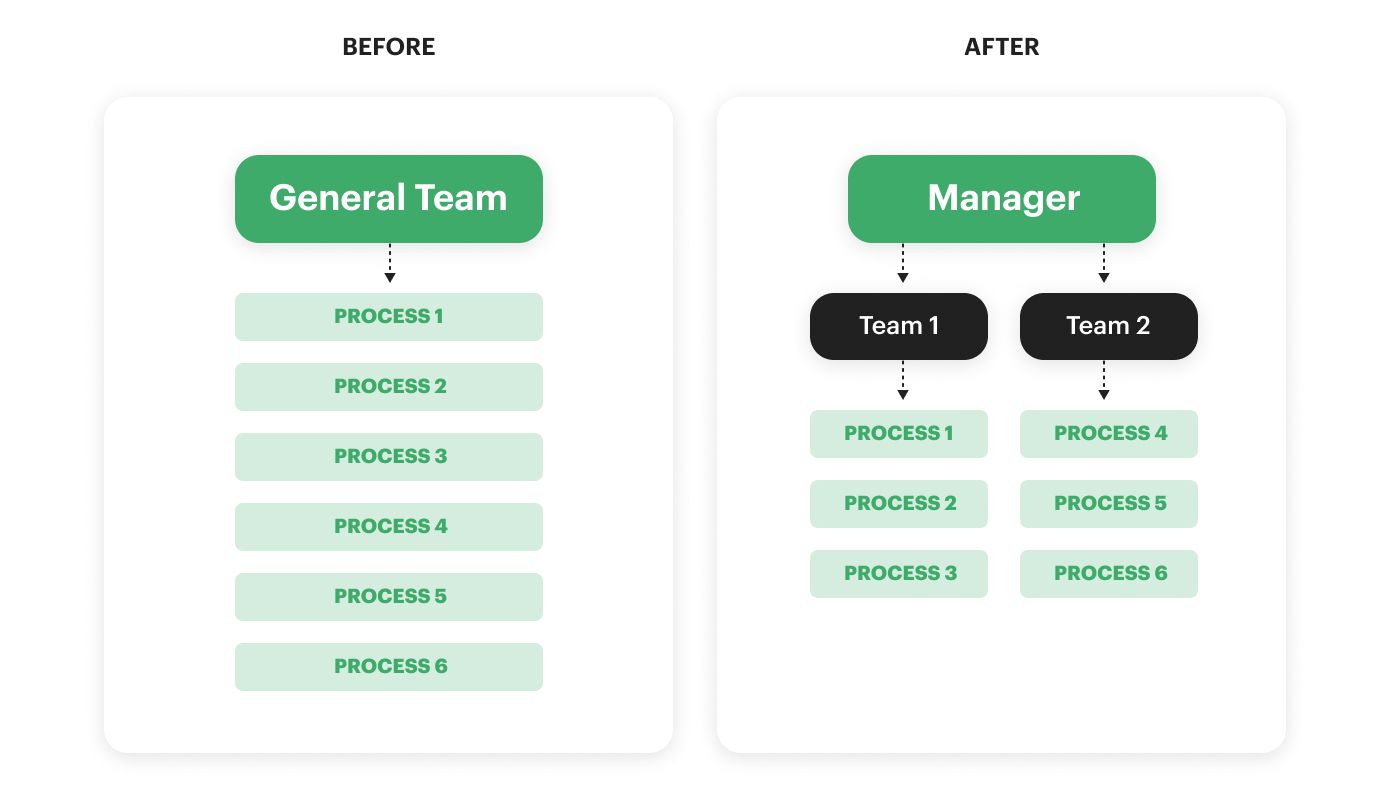
Onboarding and engagement leads workflow. Image Credits: Julia Ivzhenko
Second: When no place for optimization was left, automation began.
Process automation requires a certain understanding of “what,” “how,” and “why” the action is done. We launched automation because the cost of human mistakes becomes higher than the cost of developers’ time. After it was finished, we saved hours of the ops team’s work time, started to achieve results fast, and had time to focus on important things to do next.
5. Created a timeline for optimization
It helped me track several teams at once and keep an eye on updates to restart the process immediately. We also increased communication and the number of short check status meetings to follow each other and become more close-knit as a team.
Disaster averted!
All the steps proved to be effective — our service continued operating, the product continued testing, and marketing was keeping up with scaling the demand. After a couple months of crazy work, we sighed with relief. I turned back and saw the operations team with eight new team members and optimized and automated processes.
I realized that enthusiasm is not a metric to scale. Each leader should think of their team resources while eagerly pushing new goals.
“Are we ready for a new level?” and “What did I do to make our team ready for new results and prevent all of us from failing right after new achievements?” These are the questions I always ask myself today while planning the work of the operations team.