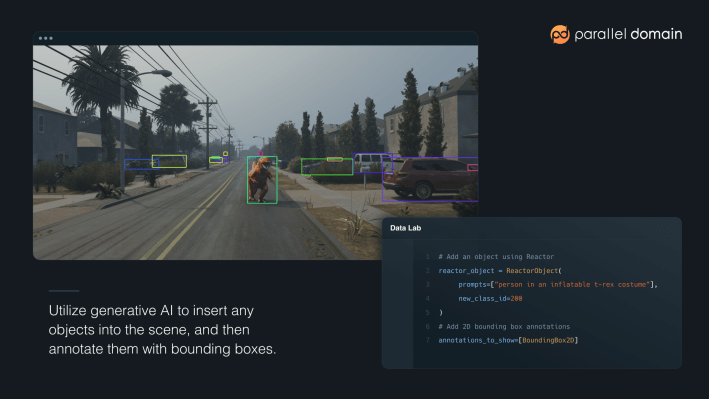
Parallel Domain is putting the ability to generate synthetic datasets into the hands of its customers. The San Francisco-based startup has launched a new API called Data Lab that stands on the shoulders of generative AI giants, giving machine-learning engineers control over dynamic virtual worlds to simulate any scenario imaginable.
“All you have to do is you go to GitHub, you install the API, and then you can start writing Python code that generates datasets,” Kevin McNamara, founder and CEO of Parallel Domain, told TechCrunch.
Data Lab allows engineers to generate objects that weren’t previously available in the startup’s asset library. The API uses 3D simulation to provide a foundation upon which an engineer, through a series of simple prompts, can layer the real world in all its randomness on top. Want to train your model to drive on a highway with a cab flipped over across two lanes? Easy. Think your robotaxi should know how to identify a human dressed in an inflatable dinosaur outfit? Done.
The goal is to give autonomy, drone and robotics companies more control over and more efficiency in building large datasets so they can train their models quicker and at a deeper level.
“Iteration time now goes to essentially how fast can you, as an ML engineer, think of what you want and translate that into an API call, a set of code?” said McNamara. “There is a near infinite, unbounded level of stuff a customer could type in for a prompt, and the system just works.”
Parallel Domain counts major OEMs building advanced driver assistance systems (ADAS) and autonomous driving companies as customers. Historically, it might have taken weeks or months for the startup to create datasets based on a customer’s specific parameters. With the self-serve API, customers can form new datasets in “near real time,” according to McNamara.
On a larger scale, Data Lab could help scale autonomous driving systems even faster. McNamara said the startup tested certain AV models on synthetic datasets of strollers against real-world datasets of strollers, and found that the model performed better when trained on synthetic data.
While Parallel Domain isn’t using any of the OpenAI APIs that have gained popularity in recent months like ChatGPT, the startup is building components of its technology on top of the large foundation models that have been open sourced within the past couple of years.
“Things like Stable Diffusion enable us to fine tune our own versions of these foundation models and then use text input to drive the image and content generation,” said McNamara, noting that his team developed custom tech stacks to label objects as they generate.
Parallel Domain initially launched its synthetic data generation engine, called Reactor, in May for internal use and beta testing with trusted customers. Now that Reactor is being offered to customers through the Data Lab API, Parallel Domain’s business model will likely shift as customers prefer easy access to generative AI.
The startup’s commercial strategy today involves customers buying allotments of data and then using those credits throughout the year. Data Lab can help Parallel Domain move into a software-as-a-service (SaaS) model, where customers can subscribe to access to the platform and pay based on how much they use it, said McNamara.
The API also has the potential to help Parallel Domain scale into any space where computer vision-enabled technology is making industries more efficient, like agriculture, retail or manufacturing.
“AI enablement of agriculture is seen as one of the biggest things that will improve efficiency, and we want to go chase those use cases and eventually have a platform where no matter what domain you’re operating in, if you need to train an AI to see the world with some kind of sensor, the place you would start is Parallel Domain,” said McNamara.