
Segment, the startup Twilio bought last fall for $3.2 billion, was just beginning to take off in 2015 when it ran into a scaling problem: It was growing so quickly, the tools it had built to process marketing data on its platform were starting to outgrow the original system design.
Inaction would cause the company to hit a technology wall, managers feared. Every early-stage startup craves growth and Segment was no exception, but it also needed to begin thinking about how to make its data platform more resilient or reach a point where it could no longer handle the data it was moving through the system. It was — in a real sense — an existential crisis for the young business.
The project that came out of their efforts was called Centrifuge, and its purpose was to move data through Segment’s data pipes to wherever customers needed it quickly and efficiently at the lowest operating cost.
Segment’s engineering team began thinking hard about what a more robust and scalable system would look like. As it turned out, their vision would evolve in a number of ways between the end of 2015 and today, and with each iteration, they would take a leap in terms of how efficiently they allocated resources and processed data moving through its systems.
The project that came out of their efforts was called Centrifuge, and its purpose was to move data through Segment’s data pipes to wherever customers needed it quickly and efficiently at the lowest operating cost. This is the story of how that system came together.
Growing pains
The systemic issues became apparent the way they often do — when customers began complaining. When Tido Carriero, Segment’s chief product development officer, came on board at the end of 2015, he was charged with finding a solution. The issue involved the original system design, which like many early iterations from startups was designed to get the product to market with little thought given to future growth and the technical debt payment was coming due.
“We had [designed] our initial integrations architecture in a way that just wasn’t scalable in a number of different ways. We had been experiencing massive growth, and our CEO [Peter Reinhardt] came to me maybe three times within a month and reported various scaling challenges that either customers or partners of ours had alerted him to,” said Carriero.
The good news was that it was attracting customers and partners to the platform at a rapid clip, but it could all have come crashing down if the company didn’t improve the underlying system architecture to support the robust growth. As Carriero reports, that made it a stressful time, but having come from Dropbox, he was actually in a position to understand that it’s possible to completely rearchitect the business’s technology platform and live to tell about it.
“One of the things I learned from my past life [at Dropbox] is when you have a problem that’s just so core to your business, at a certain point you start to realize that you are the only company in the world kind of experiencing this problem at this kind of scale,” he said. For Dropbox that was related to storage, and for Segment it was processing large amounts of data concurrently.
In the build-versus-buy equation, Carriero knew that he had to build his way out of the problem. There was nothing out there that could solve Segment’s unique scaling issues. “Obviously that led us to believe that we really need to think about this a little bit differently, and that was when our Centrifuge V2 architecture was born,” he said.
Building the imperfect beast
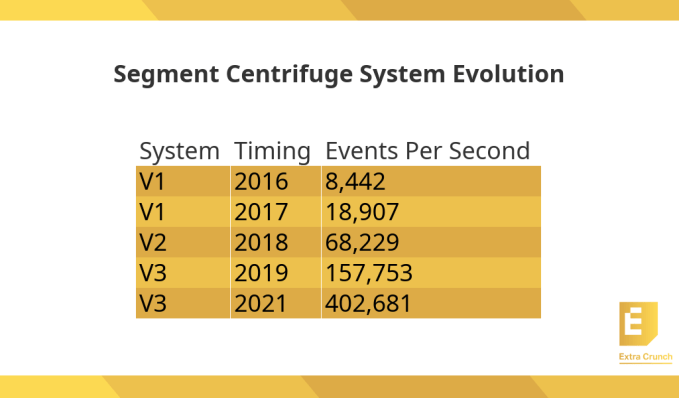
The company began measuring system performance, at the time processing 8,442 events per second. When it began building V2 of its architecture, that number had grown to an average of 18,907 events per second.
While the system performance issues started to pop up in 2016, it would take a year of research and design before building the next version of the platform, one that would rely on scaling architecture on AWS with pools of databases. It was a clever design that would solve the scaling problems, but the company would soon learn that the design came with a high cost.
Achille Roussel, principal site reliability engineer who led the Centrifuge project, knew that the company had a big problem, but it was the kind of system design challenge that engineers relish. The first step was understanding the existing system and how it was limiting Segment’s ability to keep growing.
“Once we had a really great understanding of the problem space, we were able to enter design mode and come up with a solution that retained all of the [positive] qualities that the existing system had, but addressed all of its flaws, so that it would enable the next years of growth,” Roussel explained.
At its core, the new system relied on containerization using Amazon ECS, AWS’s container management service and pools of Amazon Aurora databases. “So specifically we started with Aurora, as the first underlying technology, and we were managing these pools of MySQL databases running on Aurora, and eventually on the standard Amazon RDS [cloud relational databases]. That was the core database technology that was powering the system, and ECS was our container scheduler of choice at the time, so it was basically built on those two building blocks,” he said.
When V2 was fully deployed at the beginning of 2018, it was processing more than 68,000 events per second. The new system solved some of the major scaling issues the company had been experiencing with the previous version, but it came with a set of problems of its own, chiefly that this kind of cloud-based scaling was expensive. What’s more, there were hard limits in terms of the numbers of pooled databases Segment could spin up. Finally, it was so complex to run, it was hard to bring new people into the mix to help maintain the system.
This led to the idea of building V3, a project that started at the beginning of 2019.
Getting it just right
The cost-efficiency problem actually surprised the engineering team, and it was something that forced them to add some features to reduce their growing cloud bills with Amazon. “When we put the system in production we started to realize how much it was actually costing, and a lot of effort had to be put into managing this to make it profitable for us to run it in production,” Roussel said.
They also started to see that the new system had its own limitations and a scaling problem similar to the one that they had run into with its predecessor.
Once again, they were faced with having to find a way to overcome that before they hit the design limitations of V2. “After a year is when we started seeing the limits of the design that we had put in place, especially the technological choices we had made where auto-scaling these pools of hundreds of MySQL databases just had a physical limit on how many we could start at once.” He said that they recognized that limited how fast they could scale and it was imperative that they think about how to fix that.
At this point, they turned to Kafka, the open-source streaming events platform, something they had been using in-house for pieces of the system. Now, they would rely on Kafka as the meat of the solution to eliminate their reliance on the pools of MySQL databases running on AWS.
“Once we decided to get rid of databases, we had to look at our options, including what the industry was doing and what kind of expertise we had in-house. Kafka came up as a really powerful building block, and since we had invested a lot in it already we had great automation and had achieved a very high cost efficiency, it seemed like investing in that again would allow us to leverage a lot of these benefits that we had acquired already,” he said.
They also moved from ECS to EKS, Amazon’s managed Kubernetes service. The new system was a lot cheaper, providing a 10x reduction in infrastructure costs. Most importantly the company had created an infinitely scalable system, so it shouldn’t run into the kinds of scalability walls it faced with V1 and V2.
In fact, when the system was deployed September 2019, it processed more than 157,000 events per second. In the most recent measurement, that figure had grown to more than 400,000 events per second, proving the scalability of the new system.
Now that the company is part of Twilio, its future architecture plans will be intertwined more closely with theirs, but that process is only just getting started. Carriero says as a scrappy startup, they looked as far ahead as the current project, while a public company like Twilio thinks in five-year chunks.
Whatever happens with their new parent company, Segment has built a system to take them into the future with resilience and scalability however much they may grow, and that’s a good place to be.