As TC readers know, the tricky trade-off of the modern web is privacy for convenience. Online tracking is how this ‘great intimacy robbery’ is pulled off. Mass surveillance of what Internet users are looking at underpins Google’s dominant search engine and Facebook’s social empire, to name two of the highest profile ad-funded business models.
TechCrunch’s own corporate overlord, Verizon, also gathers data from a variety of end points — mobile devices, media properties like this one — to power its own ad targeting business.
Countless others rely on obtaining user data to extract some perceived value. Few if any of these businesses are wholly transparent about how much and what sort of private intelligence they’re amassing — or, indeed, exactly what they’re doing with it. But what if the web didn’t have to be like that?
Berlin-based Xayn wants to change this dynamic — starting with personalized but privacy-safe web search on smartphones.
Today it’s launching a search engine app (on Android and iOS) that offers the convenience of personalized results but without the ‘usual’ shoulder surfing. This is possible because the app runs on-device AI models that learn locally. The promise is no data is ever uploaded (though trained AI models themselves can be).
The team behind the app, which is comprised of 30% PhDs, has been working on the core privacy vs convenience problem for some six years (though the company was only founded in 2017); initially as an academic research project — going on to offer an open source framework for masked federated learning, called XayNet. The Xayn app is based on that framework.
They’ve raised some €9.5 million in early stage funding to date — with investment coming from European VC firm Earlybird; Dominik Schiener (Iota co-founder); and the Swedish authentication and payment services company, Thales AB.
Now they’re moving to commercialize their XayNet technology by applying it within a user-facing search app — aiming for what CEO and co-founder, Dr Leif-Nissen Lundbæk bills as a “Zoom”-style business model, in reference to the ubiquitous videoconferencing tool which has both free and paid users.
This means Xayn’s search is not ad-supported. That’s right; you get zero ads in search results.
Instead, the idea is for the consumer app to act as a showcase for a b2b product powered by the same core AI tech. The pitch to business/public sector customers is speedier corporate/internal search without compromising commercial data privacy.
Lundbæk argues businesses are sorely in need of better search tools to (safely) apply to their own data, saying studies have shown that search in general costs around 18% of working time globally. He also cites a study by one city authority that found staff spent 37% of their time at work searching for documents or other digital content.
“It’s a business model that Google has tried but failed to succeed,” he argues, adding: “We are solving not only a problem that normal people have but also that companies have… For them privacy is not a nice to have; it needs to be there otherwise there is no chance of using anything.”
On the consumer side there will also be some premium add-ons headed for the app — so the plan is for it to be a freemium download.
Swipe to nudge the algorithm
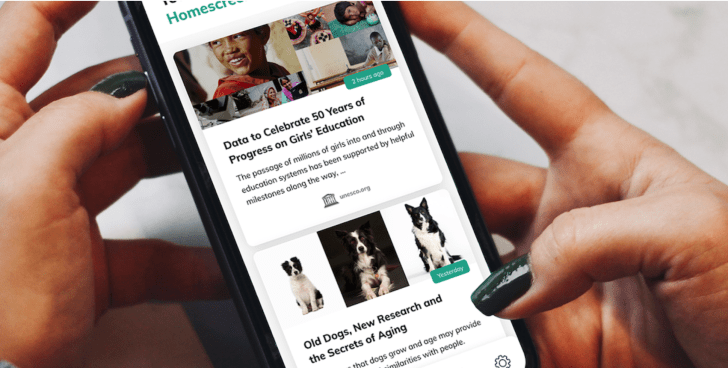
One key thing to note is Xayn’s newly launched web search app gives users a say in whether the content they’re seeing is useful to them (or not).
It does this via a Tinder-style swipe right (or left) mechanic that lets users nudge its personalization algorithm in the right direction — starting with a home screen populated with news content (localized by country) but also extending to the search result pages.
The news-focused homescreen is another notable feature. And it sounds like different types of homescreen feeds may be on the premium cards in future.
Another key feature of the app is the ability to toggle personalized search results on or off entirely — just tap the brain icon at the top right to switch the AI off (or back on). Results without the AI running can’t be swiped, except for bookmarking/sharing.
Elsewhere, the app includes a history page which lists searches from the past seven days (by default). The other options offered are: Today, 30 days, or all history (and a bin button to purge searches).
There’s also a ‘Collections’ feature that lets you create and access folders for bookmarks.
As you scroll through search results you can add an item to a Collection by swiping right and selecting the bookmark icon — which then opens a prompt to choose which one to add it to.
The swipe-y interface feels familiar and intuitive, if slightly laggy to load content in the TestFlight beta version TechCrunch checked out ahead of launch.
Swiping left on a piece of content opens a bright pink color-block stamped with a warning ‘x’. Keep going and you’ll send the item vanishing into the ether, presumably seeing fewer like it in future.
Whereas a swipe right affirms a piece of content is useful. This means it stays in the feed, outlined in Xayn green. (Swiping right also reveals the bookmark option and a share button.)
While there are pro-privacy/non-tracking search engines on the market already — such as US-based DuckDuckGo or France’s Qwant — Xayn argues the user experience of such rivals tends to fall short of what you get with a tracking search engine like Google, i.e. in terms of the relevance of search results and thus time spent searching.
Simply put: You probably have to spend more time ‘DDGing’ or ‘Qwanting’ to get the specific answers you need vs Googling — hence the ‘convenience cost’ associated with safeguarding your privacy when web searching.
Xayn’s contention is there’s a third, smarter way of getting to keep your ‘virtual clothes’ on when searching online. This involves implementing AI models that learn on-device and can be combined in a privacy-safe way so that results can be personalized without putting people’s data at risk.
“Privacy is the very fundament… It means that quite like other privacy solutions we track nothing. Nothing is sent to our servers; we don’t store anything of course; we don’t track anything at all. And of course we make sure that any connection that is there is basically secured and doesn’t allow for any tracking at all,” says Lundbæk, explaining the team’s AI-fuelled, decentralized/edge-computing approach.
On-device reranking
Xayn is drawing on a number of search index sources, including (but not solely) Microsoft’s Bing, per Lundbæk, who described this bit of what it’s doing as “relatively similar” to DuckDuckGo (which has its own web crawling bots).
The big difference is that it’s also applying its own reranking algorithms in order generate privacy-safe personalized search results (whereas DDG uses a contextual ads-based business model — looking at simple signals like location and keyword search to target ads without needing to profile users).
The downside to this sort of approach, according to Lundbæk, is users can get flooded with ads — as a consequence of the simpler targeting meaning the business serves more ads to try to increase chances of a click. And loads of ads in search results obviously doesn’t make for a great search experience.
“We get a lot of results on device level and we do some ad hoc indexing — so we build on the device level and on index — and with this ad hoc index we apply our search algorithms in order to filter them, and only present you what is more relevant and filter out everything else,” says Lundbæk, sketching how Xayn works. “Or basically downgrade it a bit… but we also try to keep it fresh and explore and also bump up things where they might not be super relevant for you but it gives you some guarantees that you won’t end up in some kind of bubble.”
Some of what Xayn’s doing is in the arena of federated learning (FL) — a technology Google has been dabbling in in recent years, including pushing a ‘privacy-safe’ proposal for replacing third party tracking cookies. But Xayn argues the tech giant’s interests, as a data business, simply aren’t aligned with cutting off its own access to the user data pipe (even if it were to switch to applying FL to search).
Whereas its interests — as a small, pro-privacy German startup — are markedly different. Ergo, the privacy-preserving technology it’s spent years building has a credible interest in safeguarding people’s data, is the claim.
“At Google there’s actually [fewer] people working on federate learning than in our team,” notes Lundbæk, adding: “We’ve been criticizing TFF [Google-designed TensorFlow Federated] at lot. It is federated learning but it’s not actually doing any encryption at all — and Google has a lot of backdoors in there.
“You have to understand what does Google actually want to do with that? Google wants to replace [tracking] cookies — but especially they want to replace this kind of bumpy thing of asking for user consent. But of course they still want your data. They don’t want to give you any more privacy here; they want to actually — at the end — get your data even easier. And with purely federated learning you actually don’t have a privacy solution.
“You have to do a lot in order to make it privacy preserving. And pure TFF is certainly not that privacy-preserving. So therefore they will use this kind of tech for all the things that are basically in the way of user experience — which is, for example, cookies but I would be extremely surprised if they used it for search directly. And even if they would do that there is a lot of backdoors in their system so it’s pretty easy to actually acquire the data using TFF. So I would say it’s just a nice workaround for them.”
“Data is basically the fundamental business model of Google,” he adds. “So I’m sure that whatever they do is of course a nice step in the right direction… but I think Google is playing a clever role here of kind of moving a bit but not too much.”
So how, then, does Xayn’s reranking algorithm work?
The app runs four AI models per device, combining encrypted AI models of respective devices asynchronously — with homomorphic encryption — into a collective model. A second step entails this collective model being fed back to individual devices to personalize served content, it says.
The four AI models running on the device are one for natural language processing; one for grouping interests; one for analyzing domain preferences; and one for computing context.
“The knowledge is kept but the data is basically always staying on your device level,” is how Lundbæk puts it.
“We can simply train a lot of different AI models on your phone and decide whether we, for example, combine some of this knowledge or whether it also stays on your device.”
“We have developed a quite complex solution of four different AI models that work in composition with each other,” he goes on, noting that they work to build up “centers of interest and centers of dislikes” per user — again, based on those swipes — which he says “have to be extremely efficient — they have to be moving, basically, also over time and with your interests”.
The more the user interacts with Xayn, the more precise its personalization engine gets as a result of on-device learning — plus the added layer of users being able to get actively involved by swiping to give like/dislike feedback.
The level of personalization is very individually focused — Lundbæk calls it “hyper personalization” — more so than a tracking search engine like Google, which he notes also compares cross-user patterns to determine which results to serve — something he says Xayn absolutely does not do.
Small data, not big data
“We have to focus entirely on one user so we have a ‘small data’ problem, rather than a big data problem,” says Lundbæk. “So we have to learn extremely fast — only from eight to 20 interactions we have to already understand a lot from you. And the crucial thing is of course if you do such a rapid learning then you have to take even more care about filter bubbles — or what is called filter bubbles. We have to prevent the engine going into some kind of biased direction.”
To avoid this echo chamber/filter bubble type effect, the Xayn team has designed the engine to function in two distinct phases which it switches between: Called ‘exploration’ and (more unfortunately) ‘exploitation’ (i.e. just in the sense that it already knows something about the user so can be pretty certain what it serves will be relevant).
“We have to keep fresh and we have to keep exploring things,” he notes — saying that’s why it developed one of the four AIs (a dynamic contextual multi-armed bandit reinforcement learning algorithm for computing context).
Aside from this app infrastructure being designed natively to protect user privacy, Xayn argues there are a bunch of other advantages — such as being able to derive potentially very clear interests signs from individuals; and avoiding the chilling effect that can result from tracking services creeping users out (to the point people they avoid making certain searches in order to prevent them from influencing future results).
“You as the user can decide whether you want the algorithm to learn — whether you want it to show more of this or less of this — by just simply swiping. So it’s extremely easy, so you can train your system very easily,” he argues.
There is potentially a slight downside to this approach, too, though — assuming the algorithm (when on) does some learning by default (i.e in the absence of any life/dislike signals from the user).
This is because it puts the burden on the user to interact (by swiping their feedback) in order to get the best search results out of Xayn. So that’s an active requirement on users, rather than the typical passive background data mining and profiling web users are used to from tech giants like Google (which is, however, horrible for their privacy).
It means there’s an ‘ongoing’ interaction cost to using the app — or at least getting the most relevant results out of it. You might not, for instance, be advised to let a bunch of organic results just scroll past if they’re really not useful but rather actively signal disinterest on each.
For the app to be the most useful it may ultimately pay to carefully weight each item and provide the AI with a utility verdict. (And in a competitive battle for online convenience every little bit of digital friction isn’t going to help.)
Asked about this specifically, Lundbæk told us: “Without swiping the AI only learns from very weak likes but not from dislikes. So the learning takes place (if you turn the AI on) but it’s very slight and does not have a big effect. These conditions are quite dynamic, so from the experience of liking something after having visited a website, patterns are learned. Also, only 1 of the 4 AI models (the domain learning one) learns from pure clicks; the others don’t.”
Xayn does seem alive to the risk of the swiping mechanic resulting in the app feeling arduous. Lundbæk says the team is looking to add “some kind of gamification aspect” in the future — to flip the mechanism from pure friction to “something fun to do”. Though it remains to be seen what they come up with on that front.
There is also inevitably a bit of lag involved in using Xayn vs Google — by merit of the former having to run on-device AI training (whereas Google merely hoovers your data into its cloud where it’s able to process it at super-speeds using dedicated compute hardware, including bespoke chipsets).
“We have been working for over a year on this and the core focus point was bringing it on the street, showing that it works — and of course it is slower than Google,” Lundbæk concedes.
“Google doesn’t need to do any of these [on-device] processes and Google has developed even its own hardware; they developed TPUs exactly for processing this kind of model,” he goes on. “If you compare this kind of hardware it’s pretty impressive that we were even able to bring [Xayn’s on-device AI processing] even on the phone. However of course it’s slower than Google.”
Lundbæk says the team is working on increasing the speed of Xayn. And anticipates further gains as it focuses more on that type of optimization — trailing a version that’s 40x faster than the current iteration.
“It won’t at the end be 40x faster because we will use this also to analyze even more content — to give you can even broader view — but it will be faster over time,” he adds.
On the accuracy of search results vs Google, he argues the latter’s ‘network effect’ competitive advantage — whereby its search reranking benefits from Google having more users — is not unassailable because of what edge AI can achieve working smartly atop ‘small data’.
Though, again, for now Google remains the search standard to beat.
“Right now we compare ourselves, mostly against Bing and DuckDuckGo and so on. Obviously there we get much better results [than compared to Google] but of course Google is the market leader and is using quite some heavy personalization,” he says, when we ask about benchmarking results vs other search engines.
“But the interesting thing is so far Google is not only using personalization but they also use kind of a network effect. PageRank is very much a network effect where the most users they have the better the results get, because they track how often people click on something and bump this also up.
“The interesting effect there is that right now, through AI technology — like for example what we use — the network effect becomes less and less important. So actually I would say that there isn’t really any network effect anymore if you really want to compete with pure AI technology. So therefore we can get almost as relevant results as Google right now and we surely can also, over time, get even better results or competing results. But we are different.”
In our (brief) tests of the beta app Xayn’s search results didn’t obviously disappoint for simple searches (and would presumably improve with use). Though, again, the slight load lag adds a modicum of friction which was instantly obvious compared to the usual search competition.
Not a deal breaker — just a reminder that performance expectations in search are no cake walk (even if you can promise a cookie-free experience).
An opportunity for competition?
“So far Google has so far had the advantage of a network effect — but this network effect gets less and less dominant and you see already more and more alternatives to Google popping up,” Lundbæk argues, suggesting privacy concerns are creating an opportunity for increased competition in the search space.
“It’s not anymore like Facebook or so where there’s one network where everyone has to be. And I think this is actually a nice situation because competition is always good for technical innovations and for also satisfying different customer needs.”
Of course the biggest challenge for any would-be competitor to Google search — which carves itself a marketshare in Europe in excess of 90% — is how to poach (some of) its users.
Lundbæk says the startup has no plans to splash millions on marketing at this point. Indeed, he says they want to grow usage sustainably, with the aim of evolving the product “step by step” with a “tight community” of early adopters — relying on cross-promotion from others in the pro-privacy tech space, as well as reaching out to relevant influencers.
He also reckons there’s enough mainstream media interest in the privacy topic to generate some uplift.
“I think we have such a relevant topic — especially now,” he says. “Because we want to show also not only for ourselves that you can do this for search but we think we show a real nice example that you can do this for any kind of case.
“You don’t always need the so-called ‘best’ big players from the US which are of course getting all of your data, building up profiles. And then you have these small, cute privacy-preserving solutions which don’t use any of this but then offer a bad user experience. So we want to show that this shouldn’t be the status quo anymore — and you should start to build alternatives that are really build on European values.”
And it’s certainly true EU lawmakers are big on tech sovereignty talk these days, even though European consumers mostly continue to embrace big (US) tech.
Perhaps more pertinently, regional data protection requirements are making it increasing challenging to rely on US-based services for processing data. Compliance with the GDPR data protection framework is another factor businesses need to consider. All of which is driving attention onto ‘privacy-preserving’ technologies.
Xayn’s team is hoping to be able spread its privacy-preserving gospel to general users by growing the b2b side of the business, according to Lundbæk — so it’s hoping some home use will follow once employees get used to convenient private search via their workplaces, in a small-scale reverse of the business consumerization trend that was powered by modern smartphones (and people bringing their own device to work).
“We these kind of strategies I think we can step by step build up in our communities and spread the word — so we think we don’t even need to really spend millions of euros in marketing campaigns to get more and more users,” he adds.
While Xayn’s initial go-to-market push has been focused on getting the mobile apps out, a desktop version is also planned for Q1 next year.
The challenge there is getting the app to work as a browser extension as the team obviously doesn’t want to build its own browser to house Xayn. tl;dr: Competing with Google search is mountain enough to climb, without trying to go after Chrome (and Firefox, and so on).
“We developed our entire AI in Rust which is a safe language. We are very much driven by security here and safety. The nice thing is it can work everywhere — from embedded systems towards mobile systems, and we can compile into web assembly so it runs also as a browser extension in any kind of browser,” he adds. “Except for Internet Explorer of course.”