
The web, it turns out, is a fragile place. Companies, governments, educational institutions, individuals and organizations put up and take down sites all the time. The problem is that the web has become a system of record, and when links don’t work because pages no longer exist, the record is incomplete. With the help of volunteers from Internet Archive, Wikipedia has been able to recover 9 million broken links and help solve that problem for at least one knowledge base.
The Internet Archive captures a copy of as many websites as it can to build an archive of the web. If you know what you’re looking for, you can search their Wayback Machine archive of more than 338 billion web pages, dating back to the earliest days of the World Wide Web. The problem is you have to know what you’re searching for, and that can be problematic.
A Wikipedia contributor named Maximilian Doerr put the power of software to bear on the problem. He built a program called IAbot, short for Internet Archive bot. Internet Archive also credits Stephen Balbach, who worked with Doerr and the Internet Archive, tracking down and verifying Wikipedia archives and writing programs to fix data errors.
First IAbot identified broken links, those pages that returned a 404 or “page not found” errors. Once the bot identified a broken link, it searched the Internet Archive for the matching page, and when it found a copy, it linked to that, thereby preserving the link to the content, even though the original page or website was no longer available.
Over a three-year period, that software helped fix 6 million links across 22 Wikipedia sites. Wikipedia volunteers fixed an additional 3 million links by manually linking to the correct Internet Archive page, an astonishing amount of preservation work, and one that helps maintain the integrity of the web and provides an audit trail where one was missing.
In a blog post announcing the results of the project, Internet Archive reported that after studying the link-clicking behavior of Wikipedia users over a recent 10-day period, they found that the vast majority of links were going to Internet Archive pages, showing the power of this project to fix broken links in Wikipedia.
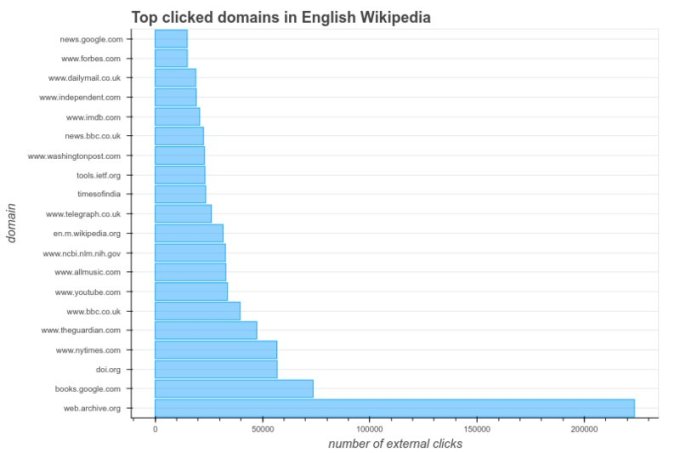
Graph: Internet Archive
A few years ago, I wrote a piece in which I lamented that the internet was failing the website preservation test. I concluded, “If we can send bots out to index the internet, it seems we should be able to find an automated technological solution to preserve content for future generations. At the very least, we are duty bound to try.”
If this is truly our system of record for government and society, then we need more projects like this to preserve the integrity of the system for future generations. The Internet Archive/Wikipedia project is certainly a positive step in that direction. What’s more, the organization plans to build on this work across Wikipedia and other sites, while also working with editors or writers who wish to link to archived pages when live pages no longer exist.
Note: This article originally incorrectly referred to Internet Archive as Internet.org.