
Nick Halstead’s new startup, InfoSum, is launching its first product today — moving one step closer to his founding vision of a data platform that can help businesses and organizations unlock insights from big data silos without compromising user privacy, data security or data protection law. So a pretty high bar then.
If the underlying tech lives up to the promises being made for it, the timing for this business looks very good indeed, with the European Union’s new General Data Protection Regulation (GDPR) mere months away from applying across the region — ushering in a new regime of eye-wateringly large penalties to incentivize data handling best practice.
InfoSum bills its approach to collaboration around personal data as fully GDPR compliant — because it says it doesn’t rely on sharing the actual raw data with any third parties.
Rather a mathematical model is used to make a statistical comparison, and the platform delivers aggregated — but still, says Halstead — useful insights. Though he says the regulatory angle is fortuitous, rather than the full inspiration for the product.
“Two years ago, I saw that the world definitely needed a different way to think about working on knowledge about people,” he tells TechCrunch. “Both for privacy [reasons] — there isn’t a week where we don’t see some kind of data breach… they happen all the time — but also privacy isn’t enough by itself. There has to be a commercial reason to change things.”
The commercial imperative he reckons he’s spied is around how “unmanageable” big data can become when it’s pooled for collaborative purposes.
Datasets invariably need a lot of cleaning up to make different databases align and overlap. And the process of cleaning and structuring data so it can be usefully compared can run to multiple weeks. Yet that effort has to be put in before you really know if it will be worth your while doing so.
That snag of time + effort is a major barrier preventing even large companies from doing more interesting things with their data holdings, argues Halstead.
So InfoSum’s first product — called Link — is intended to give businesses a glimpse of the “art of the possible”, as he puts it — in just a couple of hours, rather than the “nine, ten weeks” he says it might otherwise take them.
“I set myself a challenge… could I get through the barriers that companies have around privacy, security, and the commercial risks when they handle consumer data. And, more importantly, when they need to work with third parties or need to work across their corporation where they’ve got numbers of consumer data and they want to be able to look at that data and look at the combined knowledge across those.
“That’s really where I came up with this idea of non-movement of data. And that’s the core principle of what’s behind InfoSum… I can connect knowledge across two data sets, as if they’ve been pooled.”
Halstead says that the problem with the traditional data pooling route — so copying and sharing raw data with all sorts of partners (or even internally, thereby expanding the risk vector surface area) — is that it’s risky. The myriad data breaches that regularly make headlines nowadays are a testament to that.
But that’s not the only commercial consideration in play, as he points out that raw data which has been shared is immediately less valuable — because it can’t be sold again.
“If I give you a data set in its raw form, I can’t sell that to you again — you can take it away, you can slice it and dice it as many ways as you want. You won’t need to come back to me for another three or four years for that same data,” he argues. “From a commercial point of view [what we’re doing] makes the data more valuable. In that data is never actually having to be handed over to the other party.”
Not blockchain for privacy
Decentralization, as a technology approach, is also of course having a major moment right now — thanks to blockchain hype. But InfoSum is definitely not blockchain. Which is a good thing. No sensible person should be trying to put personal data on a blockchain.
“The reality is that all the companies that say they’re doing blockchain for privacy aren’t using blockchain for the privacy part, they’re just using it for a trust model, or recording the transactions that occur,” says Halstead, discussing why blockchain is terrible for privacy.
“Because you can’t use the blockchain and say it’s GDPR compliant or privacy safe. Because the whole transparency part of it and the fact that it’s immutable. You can’t have an immutable database where you can’t then delete users from it. It just doesn’t work.”
Instead he describes InfoSum’s technology as “blockchain-esque” — because “everyone stays holding their data”. “The trust is then that because everyone holds their data, no one needs to give their data to everyone else. But you can still crucially, through our technology, combine the knowledge across those different data sets.”
So what exactly is InfoSum doing to the raw personal data to make it “privacy safe”? Halstead claims it goes “beyond hashing” or encrypting it. “Our solution goes beyond that — there is no way to re-identify any of our data because it’s not ever represented in that way,” he says, further claiming: “It is absolutely 100 per cent data isolation, and we are the only company doing this in this way.
“There are solutions out there where traditional models are pooling it but with encryption on top of it. But again if the encryption gets broken the data is still ending up being in a single silo.”
InfoSum’s approach is based on mathematically modeling users, using a “one way model”, and using that to make statistical comparisons and serve up aggregated insights.
“You can’t read things out of it, you can only test things against it,” he says of how it’s transforming the data. “So it’s only useful if you actually knew who those users were beforehand — which obviously you’re not going to. And you wouldn’t be able to do that unless you had access to our underlying code-base. Everyone else either users encryption or hashing or a combination of both of those.”
This one-way modeling technique is in the process of being patented — so Halstead says he can’t discuss the “fine details” — but he does mention a long standing technique for optimizing database communications, called bloom filters, saying those sorts of “principles” underpin InfoSum’s approach.
Although he also says it’s using those kind of techniques differently. Here’s how InfoSum’s website describes this process (which it calls Quantum):
InfoSum Quantum irreversibly anonymises data and creates a mathematical model that enables isolated datasets to be statistically compared. Identities are matched at an individual level and results are collated at an aggregate level – without bringing the datasets together.
On the surface, the approach shares a similar structure to Facebook’s Custom Audiences Product, where advertisers’ customer lists are locally hashed and then uploaded to Facebook for matching against its own list of hashed customer IDs — with any matches used to create a custom audience for ad targeting purposes.
Though Halstead argues InfoSum’s platform offers more for even this kind of audience building marketing scenario, because its users can use “much more valuable knowledge” to model on — knowledge they would not comfortably share with Facebook “because of the commercial risks of handing over that first person valuable data”.
“For instance if you had an attribute that defined which were your most valuable customers, you would be very unlikely to share that valuable knowledge — yet if you could safely then it would be one of the most potent indicators to model upon,” he suggests.
He also argues that InfoSum users will be able to achieve greater marketing insights via collaborations with other users of the platform vs being a customer of Facebook Custom Audiences — because Facebook simply “does not open up its knowledge”.
“You send them your customer lists, but they don’t then let you have the data they have,” he adds. “InfoSum for many DMPs [data management platforms] will allow them to collaborate with customers so the whole purchasing of marketing can be much more transparent.”
He also emphasizes that marketing is just one of the use-cases InfoSum’s platform can address.
Decentralized bunkers of data
One important clarification: InfoSum customers’ data does get moved — but it’s moved into a “private isolated bunker” of their choosing, rather than being uploaded to a third party.
“The easiest one to use is where we basically create you a 100 per cent isolated instance in Amazon [Web Services],” says Halstead. “We’ve worked with Amazon on this so that we’ve used a whole number of techniques so that once we create this for you, you put your data into it — we don’t have access to it. And when you connect it to the other part we use this data modeling so that no data then moves between them.”
“The ‘bunker’ is… an isolated instance,” he adds, elaborating on how communications with these bunkers are secured. “It has its own firewall, a private VPN, and of course uses standard SSL security. And once you have finished normalising the data it is turned into a form in which all PII [personally identifiable information] is deleted.
“And of course like any other security related company we have had independent security companies penetration test our solution and look at our architecture design.”
Other key pieces of InfoSum’s technology are around data integration and identity mapping — aimed at tackling the (inevitable) problem of data in different databases/datasets being stored in different formats. Which again is one of the commercial reasons why big data silos often stay just that: Silos.
Halstead gave TechCrunch a demo showing how the platform ingests and connects data, with users able to use “simple steps” to teach the system what is meant by data types stored in different formats — such as that ‘f’ means the same as ‘female’ for gender category purposes — to smooth the data mapping and “try to get it as clean as possible”.
Once that step has been completed, the user (or collaborating users) are able to get a view on how well linked their data sets are — and thus to glimpse “the start of the art of the possible”.
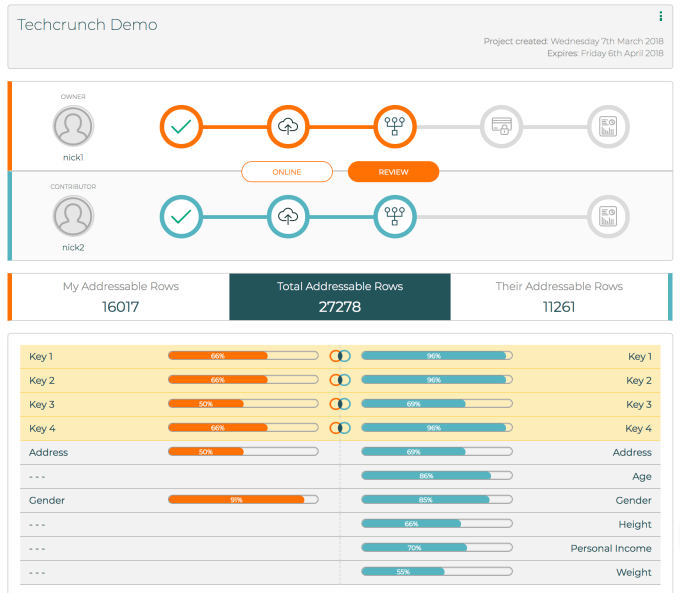
In practice this means they can choose to run different reports atop their linked datasets — such as if they want to enrich their data holdings by linking their own users across different products to gain new insights, such as for internal research purposes.
Or, where there’s two InfoSum users linking different data sets, they could use it for propensity modeling or lookalike modeling of customers, says Halstead. So, for example, a company could link models of their users with models of the users of a third party that holds richer data on its users to identify potential new customer types to target marketing at.
“Because I’ve asked to look at the overlap I can literally say I only know the gender of these people but I would also like to know what their income is,” he says, fleshing out another possible usage scenario. “You can’t drill into this, you can’t do really deep analytics — that’s what we’ll be launching later. But Link allows you to get this idea of what would it look like if I combine our datasets.
“The key here is it’s opening up a whole load of industries where sensitivity around doing this — and where, even in industries that share a lot of data already but where GDPR is going to be a massive barrier to it in the future.”
Halstead says he expects big demand from the marketing industry which is of course having to scramble to rework its processes to ensure they don’t fall foul of GDPR.
“Within marketing there is going to be a whole load of new challenges for companies where they were currently enhancing their databases, buying up large raw datasets and bringing their data into their own CRM. That world’s gone once we’ve got GDPR.
“Our model is safer, faster, and actually still really lets people do all the things they did before but while protecting the customers.”
But it’s not just marketing exciting him. Halstead believes InfoSum’s approach to lifting insights from personal data could be very widely applicable — arguing, for example, that it’s only a minority of use-cases, such as credit risk and fraud within banking, where companies actually need to look at data at an individual level.
One area he says he’s “very passionate” about InfoSum’s potential is in the healthcare space.
“We believe that this model isn’t just about helping marketing and helping a whole load of others — healthcare especially for us I think is going to be huge. Because [this affords] the ability to do research against health data where health data is never been actually shared,” he says.
“In the UK especially we’ve had a number of massive false starts where companies have, for very good reasons, wanted to be able to look at health records and combine data — which can turn into vital research to help people. But actually their way of doing it has been about giving out large datasets. And that’s just not acceptable.”
He even suggests the platform could be used for training AIs within the isolated bunkers — flagging a developer interface that will be launching after Link which will let users query the data as a traditional SQL query.
Though he says he sees most initial healthcare-related demand coming from analytics that need “one or two additional attributes” — such as, for example, comparing health records of people with diabetes with activity tracker data to look at outcomes for different activity levels.
“You don’t need to drill down into individuals to know that the research capabilities could give you incredible results to understand behavior,” he adds. “When you do medical research you need bodies of data to be able to prove things so the fact that we can only work at an aggregate level is not, I don’t think, any barrier to being able to do the kind of health research required.”
Another area he believes could really benefit is M&A — saying InfoSum’s platform could offer companies a way to understand how their user bases overlap before they sign on the line. (It is also of course handling and thus simplifying the legal side of multiple entities collaborating over data sets.)
“There hasn’t been the technology to allow them to look at whether there’s an overlap before,” he claims. “It puts the power in the hands of the buyer to be able to say we’d like to be able to look at what your user base looks like in comparison to ours.
“The problem right now is you could do that manually but if they then backed out there’s all kinds of legal problems because I’ve had to hand the raw data over… so no one does it. So we’re going to change the M&A market for allowing people to discover whether I should acquire someone before they go through to the data room process.”
While Link is something of a taster of what InfoSum’s platform aims to ultimately offer (with this first product priced low but not freemium), the SaaS business it’s intending to get into is data matchmaking — whereby, once it has a pipeline of users, it can start to suggest links that might be interesting for its customers to explore.
“There is no point in us reinventing the wheel of being the best visualization company because there’s plenty that have done that,” he says. “So we are working on data connectors for all of the most popular BI tools that plug in to then visualize the actual data.
“The long term vision for us moves more into being more of an introductory service — i.e. one we’ve got 100 companies in this how do we help those companies work out what other companies that they should be working with.”
“We’ve got some very good systems for — in a fully anonymized way — helping you understand what the intersection is from your data to all of the other datasets, obviously with their permission if they want us to calculate that for them,” he adds.
“The way our investors looked at this, this is the big opportunity going forward. There is not limit, in a decentralized world… imagine 1,000 bunkers around the world in these different corporates who all can start to collaborate. And that’s our ultimate goal — that all of them are still holding onto their own knowledge, 100% privacy safe, but then they have that opportunity to work with each other, which they don’t right now.”
Engineering around privacy risks?
But does he not see any risks to privacy of enabling the linking of so many separate datasets — even with limits in place to avoid individuals being directly outed as connected across different services?
“However many data sets there are the only thing it can reveal extra is whether every extra data has an extra bit of knowledge,” he responds on that. “And every party has the ability to define what bit of data they would then want to be open to others to then work on.
“There are obviously sensitivities around certain combinations of attributes, around religion, gender and things like that. Where we already have a very clever permission system where the owners can define what combinations are acceptable and what aren’t.”
“My experience of working with all the social networks has meant — I hope — that we are ahead of the game of thinking about those,” he adds, saying that the matchmaking stage is also six months out at this point.
“I don’t see any down sides to it, as long as the controls are there to be able to limit it. It’s not like it’s going to be a sudden free for all. It’s an introductory service, rather than an open platform so everyone can see everything else.”
The permission system is clearly going to be important. But InfoSum does essentially appear to be heading down the platform route of offloading responsibility for ethical considerations — in its case around dataset linkages — to its customers.
Which does open the door to problematic data linkages down the line, and all sorts of unintended dots being joined.
Say, for example, a health clinic decides to match people with particular medical conditions to users of different dating apps — and the relative proportions of HIV rates across straight and gay dating apps in the local area gets published. What unintended consequences might spring from that linkage being made?
Other equally problematic linkages aren’t hard to imagine. And we’ve seen the appetite businesses have for making creepy observations about their users public.
“Combining two sets of aggregate data meaningfully is not easy,” says Eerke Boiten, professor of cyber security at De Montfort University, discussing InfoSum’s approach. “If they can make this all work out in a way that makes sense, preserves privacy, and is GDPR compliant, then they deserve a patent I suppose.”
On data linkages, Boiten points to the problems Facebook has had with racial profiling as illustrative of the potential pitfalls.
He also says there may also be GDPR-specific risks around customer profiling enabled by the platform. In an edge case scenario, for example, where two overlapped datasets are linked and found to have a 100% user match, that would mean people’s personal data had been processed by default — so that processing would have required a legal basis to be in place beforehand.
And there may be wider legal risks around profiling too. If, for example, linkages are used to deny services or vary pricing to certain types or blocks of customers, is that legal or ethical?
“From a company’s perspective, if it already has either consent or a legitimate purpose (under GDPR) to use customer data for analytical/statistical purposes then it can use our products,” says InfoSum’s COO Danvers Baillieu, on data processing consent. “Where a company has an issue using InfoSum as a sub-processor, then… we can set up the system differently so that we simply supply the software and they run it on their own machines (so we are not a data processor) –- but this is not yet available in Link.”
Baillieu also notes that the bin sizes InfoSum’s platform aggregates individuals into are configurable in its first product. “The default bin size is 10, and the absolute minimum is three,” he adds.
“The other key point around disclosure control is that our system never needs to publish the raw data table. All the famous breaches from Netflix onwards are because datasets have been pseudonymised badly and researchers have been able to run analysis across the visible fields and then figure out who the individuals are — this is simply not possible with our system as this data is never revealed.”
‘Fully GDPR compliant’ is certainly a big claim — and one that it going to have a lot of slings and arrows thrown at it as data gets ingested by InfoSum’s platform.
It’s also fair to say that a whole library of books could be written about technology’s unintended consequences.
Indeed, InfoSum’s own website credits Halstead as the inventor of the embedded retweet button, noting the technology is “something that is now ubiquitous on almost every website in the world”.
Those ubiquitous social plugins are also of course a core part of the infrastructure used to track Internet users wherever and almost everywhere they browse. So does he have any regrets about the invention, given how that bit of innovation has ended up being so devastating for digital privacy?
“When I invented it, the driving force for the retweet button was only really as a single number to count engagement. It was never to do with tracking. Our version of the retweet button never had any trackers in it,” he responds on that. “It was the number that drove our algorithms for delivering news in a very transparent way.
“I don’t need to add my voice to all the US pundits of the regrets of the beast that’s been unleashed. All of us feel that desire to unhook from some of these networks now because they aren’t being healthy for us in certain ways. And I certainly feel that what we’re not doing for improving the world of data is going to be good for everyone.”
When we first covered the UK-based startup it was going under the name CognitiveLogic — a placeholder name, as three weeks in Halstead says he was still figuring out exactly how to take his idea to market.
The founder of DataSift has not had difficulties raising funding for his new venture. There was an initial $3M from Upfront Ventures and IA Ventures, with the seed topped up by a further $5M last year, with new investors including Saul Klein (formerly Index Ventures) and Mike Chalfen of Mosaic Ventures. Halstead says he’ll be looking to raise “a very large Series A” over the summer.
In the meanwhile he says he has a “very long list” of hundreds customers wanting to get their hands on the platform to kick its tires. “The last three months has been a whirlwind of me going back to all of the major brands, all of the big data companies, there no large corporate that doesn’t have these kinds of challenges,” he adds.
“I saw a very big client this morning… they’re a large multinational, they’ve got three major brands where the three customer sets had never been joined together. So they don’t even know what the overlap of those brands are at the moment. So even giving them that insight would be massively valuable to them.”