
Simon Lee, founder and CEO of Flitto
Artificial intelligence-powered translation is becoming an increasingly crowded category, with Google, Microsoft, Amazon and Facebook all working on their own services. But tech still isn’t a match for professional human translations and machine-generated results are often hit-and-miss. One online translation service, Flitto, is now focused on providing other companies with the language data they need to train their machine translation programs.
Headquartered in Seoul, Flitto launched in 2012 as a translation crowdsourcing platform. It still provides translation services, ranging from a mobile app to professional translators, for about 7.5 million users. About 80% of its revenue, however, now comes from the sale of language data, called “corpus,” to customers such as Baidu, Microsoft, Tencent, NTT DoCoMo and the South Korean government’s Electronics and Telecommunications Research Institute.
When Flitto launched five years ago, its main competition was Google Translate, says founder and chief executive officer Simon Lee. Google Translate delivered mixed results, but professional translation services were inaccessible for most people. Flitto, whose backers include Japanese game developer Colopl, was created to combine the two. It works with 1.2 million human translators who are paid if their translation is picked by the requestor.
Then in 2016, Google introduced its neural machine translation system, which improved the accuracy of Google Translate. Now many big tech companies, including Microsoft, Amazon, Facebook and Apple, are focused on developing their own artificial intelligence translation tools.
Even though results are getting better, they are still imperfect. AI-based translation systems need a ton of data to train, which is where Flitto comes in.
“There are different ways to translate something that gives different meanings in different situations, so there needs to be a huge set of data and a human checking all of that data to see if it is right or wrong,” says Lee.
He adds “it’s difficult to build up a corpus and IT companies don’t like building corpus because they focus on technology.”
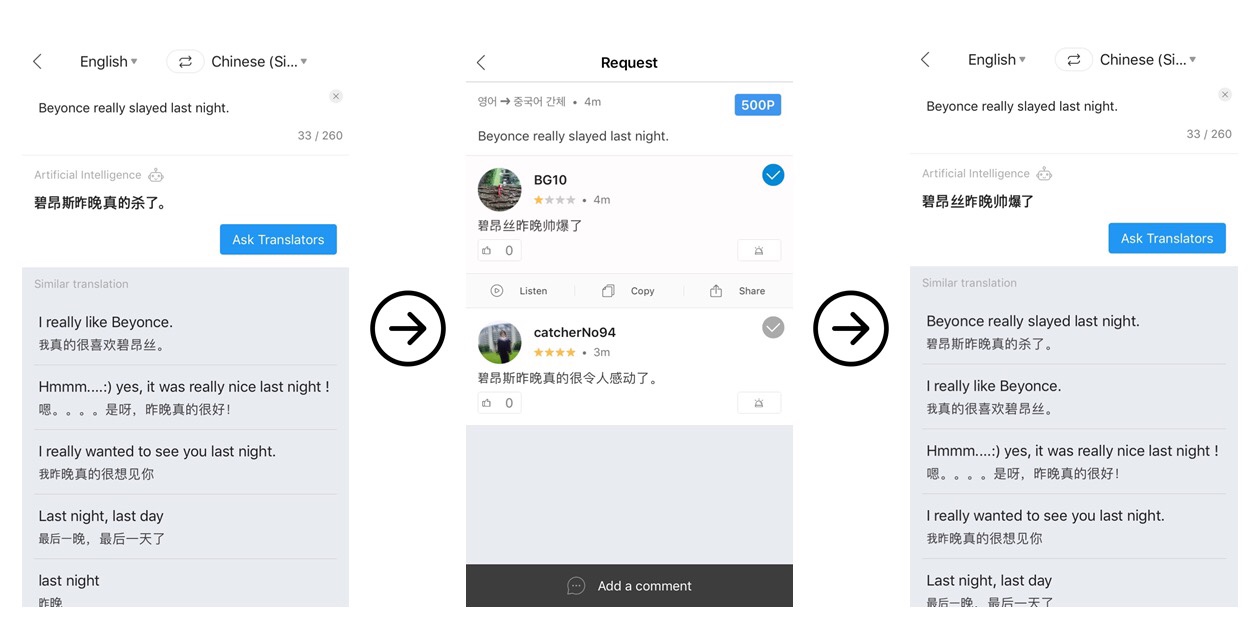
Flitto’s app provides a machine translation first, then crowdsourced translations if requested.
Flitto’s corpus includes sets of human-translated sentences from its crowdsourcing service, which is used for things like slang, pop culture references or dialects that might stymie a machine translation service. Over the last five years, Lee says Flitto has accumulated more than 100 million sets of translated language data.
Corpus providers include the Oxford University Press, which gives researchers access to the Oxford English Corpus, and companies like Microsoft and Google that built corpus to train their systems. But there is still constant demand for new corpus because they take a lot of resources to create. While programs like Deepmind’s AlphaGo were able to train themselves with almost no human help, machine translation still needs a human touch.
“In other fields, machines can create their own data, but in language and translation it’s impossible for machines to create translation data by themselves,” says Lee. “So there always have to be human translators who go through all that data.”