Sound is an incredibly valuable means of communicating information. Most motorists are familiar with the alarming noise of a slipping belt drive. My grandfather could diagnose issues with the brakes on heavy rail cars with his ears. And many other experts can detect problems with common machines in their respective fields just by listening to the sounds they make.
If we can find a way to automate listening itself, we would be able to more intelligently monitor our world and its machines day and night. We could predict the failure of engines, rail infrastructure, oil drills and power plants in real time — notifying humans the moment of an acoustical anomaly.
This has the potential to save lives, but despite advances in machine learning, we struggle to make such technologies a reality. We have loads of audio data, but lack critical labels. In the case of deep learning models, “black box” problems make it hard to determine why an acoustical anomaly was flagged in the first place. We are still working the kinks out of real-time machine learning at the edge. And sounds often come packaged with more noise than signal, limiting the features that can be extracted from audio data.
The great chasm of sound
Most researchers in the field of machine learning agree that artificial intelligence will rise from the ground up, built block-by-block, with occasional breakthroughs. Following this recipe, we have slayed image captioning and conquered speech recognition, yet the broader range of sounds still fall on the deaf ears of machines.
Behind many of the greatest breakthroughs in machine learning lies a painstakingly assembled dataset. ImageNet for object recognition and things like the Linguistic Data Consortium and GOOG-411 in the case of speech recognition. But finding an adequate dataset to juxtapose the sound of a car-door shutting and a bedroom-door shutting is quite challenging.
“Deep learning can do a lot if you build the model correctly, you just need a lot of machine data,” says Scott Stephenson, CEO of Deepgram, a startup helping companies search through their audio data. “Speech recognition 15 years ago wasn’t that great without datasets.”
Crowdsourced labeling of dogs and cats on Amazon Mechanical Turk is one thing. Collecting 100,000 sounds of ball bearings and labeling the loose ones is something entirely different.
And while these problems plague even single-purpose acoustical classifiers, the holy grail of the space is a generalizable tool for identifying all sounds, not simply building a model to differentiate the sounds of those doors.
Appreciation through introspection
Our human ability to generalize makes us particularly adept at classifying sounds. Think back to the last time you heard an ambulance rushing down the street from your apartment. Even with the Doppler effect, the changing frequency of sound waves affecting the pitch of the sirens you hear, you can easily identify the vehicle as an ambulance.
Yet researchers trying to automate this process have to get creative. The features that can be extracted from a stationary sensor collecting information about a moving object are limited.
A lack of source separation can further complicate matters. This is one that even humans struggle with. If you’ve ever tried to pick out a single table conversation at a loud restaurant, you have an appreciation for how difficult it can be to make sense of overlapping sounds.
Researchers at the University of Surrey in the U.K. were able to use a deep convolutional neural network to separate vocals from backing instruments in a number of songs. Their trick was to train models on 50 songs split up into tracks of their component instruments and voices. The tracks were then cut into 20-second segments to create a spectrogram. Combined with spectrograms of fully mixed songs, the model was able to separate vocals from backing instruments in new songs.
But it’s one thing to divide up a five piece song with easily identifiable components, it’s another to record the sound of a nearly 60 foot high MAN B&W 12S90ME-C Mark 9.2 type diesel engine and ask a machine learning model to chop up its acoustic signature into component parts.
Acoustic frontiersman
Spotify is one of the more ambitious companies toying with the applications of machine learning to audio signals. Though Spotify still relies on heaps of other data, the signals held within songs themselves are a factor in what gets recommended on its popular Discover feature.
Music recommendation has traditionally relied upon the clever heuristic of collaborative filtering. These rudimentary models skirt acoustical analysis by recommending you songs played by other users with similar listening patterns.

Filters pick up harmonic context as red and blue bands at different frequencies. Slanting indicates rising and falling pitches that can detect human voices, according to Spotify
Outside of the controlled environment of music, engineers have proposed solutions that broadly fall into two categories. The first I’m going to call the “custom solutions” model, which essentially involves a company collecting data from a client with the sole purpose of identifying a pre-set range of sounds. Think of it like build-a-bear but considerably more expensive and typically for industrial applications.
The second-approach is a “catch-all” deep learning model that can flag any acoustical anomaly. These models typically require a human-in-the-loop to manually classify sounds which then further train the model on what to look for. Over time these systems require less and less human intervention.
One company, 3D Signals, is coming to market with a hybrid approach between these two. The company has patents around the detection of acoustical anomalies in rotating equipment. This includes motors, pumps, turbines, gearboxes and generators, among other things.
“We built a very scaled architecture to connect huge fleets of distributed machines to our monitoring platform where the algorithms will highlight whenever any of these machines start misbehaving,” said company CEO Amnon Shenfeld.
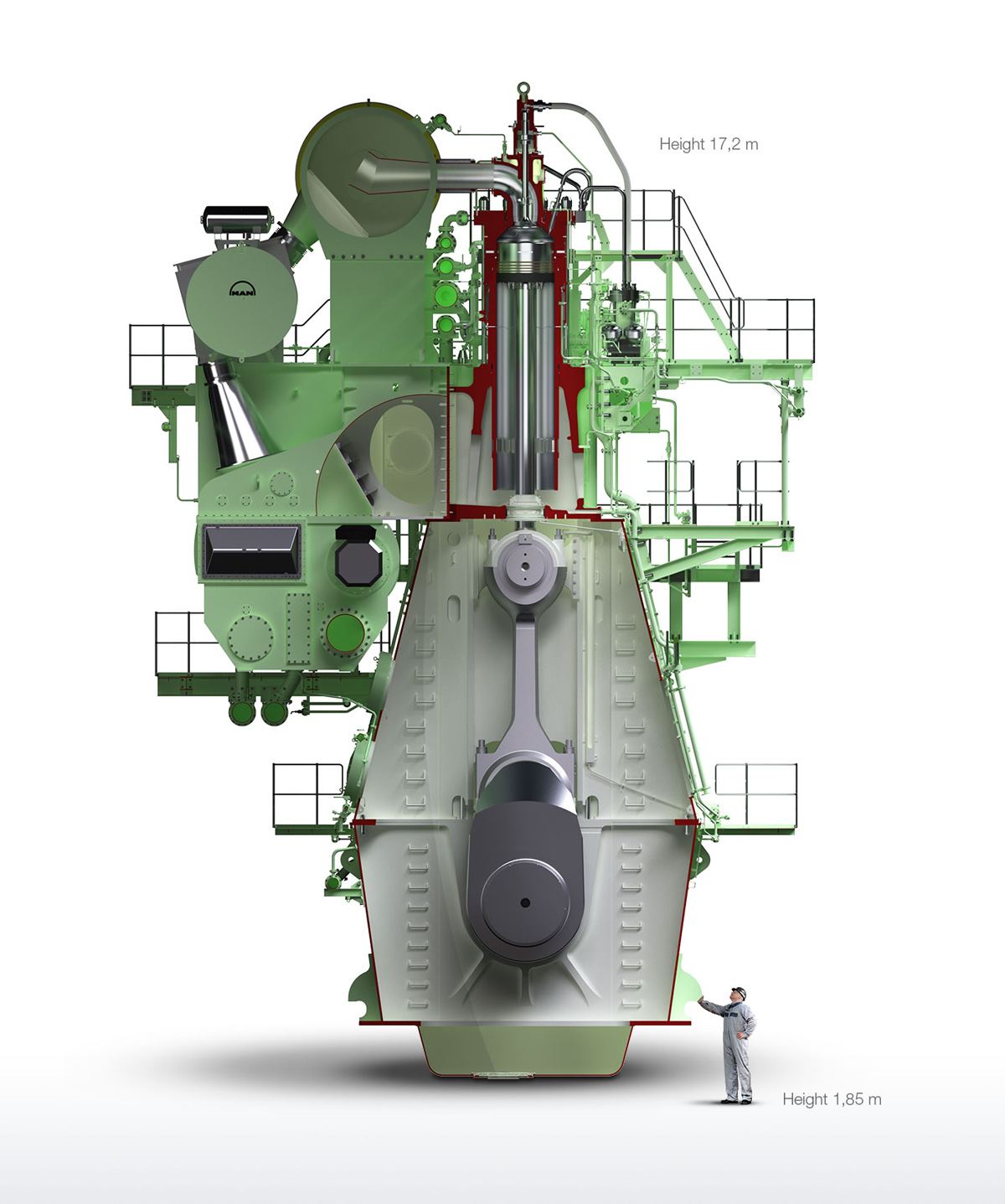
MAN B&W 12S90ME-C Mark 9.2 type diesel engine
But they also leverage existing engineers to classify problems of particular importance. If a technician recognizes a problem, they can label the acoustic anomaly which helps to train the learning algorithm to surface these types of sounds in the future.
Another company, OtoSense, actually offers a “design laboratory” on its website. Customers can note whether they have examples of specific acoustic events they want to identify and the company will help to provide a software platform that can accommodate their specific need.
Predictive maintenance is not only going to be realistic but readily available. Companies like 3DSignals and OtoSense are both targeting this space, taking advantage of commoditized IoT sensors to help users swap parts seamlessly to avoid costly downtime.
Tomorrow’s machines
Within a few years, we will have solutions for a broad range of acoustical event-detection problems. Acoustical analysis systems will be able to track lifecycle costs and help businesses budget for the future.
“There’s a strong push from the Federal Transit Administration to do condition assessments for Transit Asset Management,” said Shannon McKenna, an engineer at ATS Consulting, a firm working on noise and vibration analysis. “We see this as one way to help transit agencies come up with a condition assessment metric for their rail systems.”
Beyond short-tail indicators like wheel-squeal, in the case of rail monitoring, engineers start to run into a pretty gnarly needle in the haystack problem. McKenna explains that common acoustic signals only represent about 50 percent of the problems that a complex rail system can face. As opposed to checking boxes for compliance, true risk-management requires a generalized system — you don’t want an outlier case to result in disaster.
But we remain a long way off from a single generalized classifier that can identify any sound. Barring an algorithmic breakthrough, we will have to solve the problem in segments. We will need researchers and founders alike building classifiers for the sounds of underground subway systems, the human respiratory system, and critical energy infrastructure to help prevent tomorrow’s failures.