We have been shaping the organisms that live around us for a long time. Take as an example the changes we forced on wolves to become our best friends. Traditionally, we accomplished it by selecting organisms with special traits (“Let’s keep that wolf, it doesn’t bite as much”).
In the last 20 years we have gone further by modifying the genetic programming of organisms directly. Access to the genetic program gives scientists higher control to hopefully produce intended results faster and create behaviors not easily accessible through evolution.
We have modified the genetic programs of organisms to solve hard problems. For instance, we have created micro-organisms to produce highly valued chemical compounds like insulin, butanol, etc. We have designed rice that produces its own beta carotene to solve malnourishment in third-world nations. We have even modified higher-level organisms to fight diseases, such as Zika-fighting mosquitoes. And viruses modified to deliver genetic therapeutics are currently yielding increasing cure rates in previously deadly cancers.
Yet, the designs to create those organisms and particles usually involve relatively simple changes to natural systems, or copying genetic material from one species and pasting it into another. How do we enable much more powerful biological designs?
Challenges in biology design
The main challenge in this type of design is that we do not understand all the rules governing biological systems, which makes it impossible to simulate or predict the outcome of a particular design. No computational tool will determine whether a genetic modification of an organism will make it consume less sugar, produce more of a particular compound and survive. This forces us to do at least some part of the design evaluations in the lab.
Independent scientists and small startups don’t need to incur the high cost of setting up a lab anymore.
If we want to create a bacteria strain that produces insulin, for instance, we have to actually produce the organisms to determine if a particular set of genetic changes will yield the insulin we need. This is done by synthesizing (printing) DNA, which is then transformed (injected) into organisms. Although synthesizing DNA has traditionally been prohibitively expensive, it has been dramatically dropping in price in the last decade, from $4 per base pair to just $0.03 in 13 years.
The testing phase is also expensive and unreliable. Small changes in process or environment, quality of the materials, scale of manufacturing and manual errors all have significant impact on results. Large companies struggle with these challenges, but are able to afford to spend tens of millions of dollars on automation and software to build and test genetic systems in high throughput and with high levels of reproducibility.
Cloud lab services like Transcriptic and Emerald Cloud, as well as DNA foundries like Edinburgh Genome Foundry and The Foundry at Imperial College, are starting to emerge. These services offer to create large sequences of DNA and perform experiments in robotic labs, for a fee. Not only do they increase reliability, but they democratize experiments, as well: Independent scientists and small startups don’t need to incur the high cost of setting up a lab anymore.
Another challenge in biology is the lack of reliable information to enable machine learning algorithms. Many learning techniques require a large amount of trustworthy data. Some biotech companies have datasets that could be used, but they are behind firewalls and not accessible to academia or small startups. The advent of less expensive and more streamlined manufacturing and testing academic foundries will hopefully provide the necessary information to evaluate and advance these techniques.
Generative design
In manufacturing, designers have been exploring generative design as a new way of creating everyday things. With generative design, we set up high-level objectives and constraints and let the computer (or infinitely scalable cloud computation) create design options that best fit their criteria. At a minimum, these options spark creative ideas, and, in the best case, they provide the first draft of the final design.
Applying generative design to biology
The advances in synthesizing, assembling and testing genetic constructs, together with the advent of cloud computing, make generative design a good option for biologists.
To create our bacteria that produces insulin, then, we could modify a well-known organism, such as E. coli. These modifications include new genes that alter the internal cell metabolism to enable the production of insulin. Multiple genes may be needed, and combining them may yield better results. We could create algorithms that produce different combinations of these modifications.
How do we enable much more powerful biological designs?
In traditional manufacturing, we would run analysis simulations during the build and test phases. For biology, however, there are fewer of these analysis tools available. To test the designs, we need to build them in a lab. Depending on the type of design, this may include synthesizing DNA, introducing the DNA into cells, growing the organisms and testing for some properties.
For our insulin-producing bacteria, we would test whether the bacteria grows and the amount of insulin it produces. Because of the necessary roundtrip from the computer to the lab to test the designs, the testing phase for biology will tend to be much longer than for traditional manufacturing.
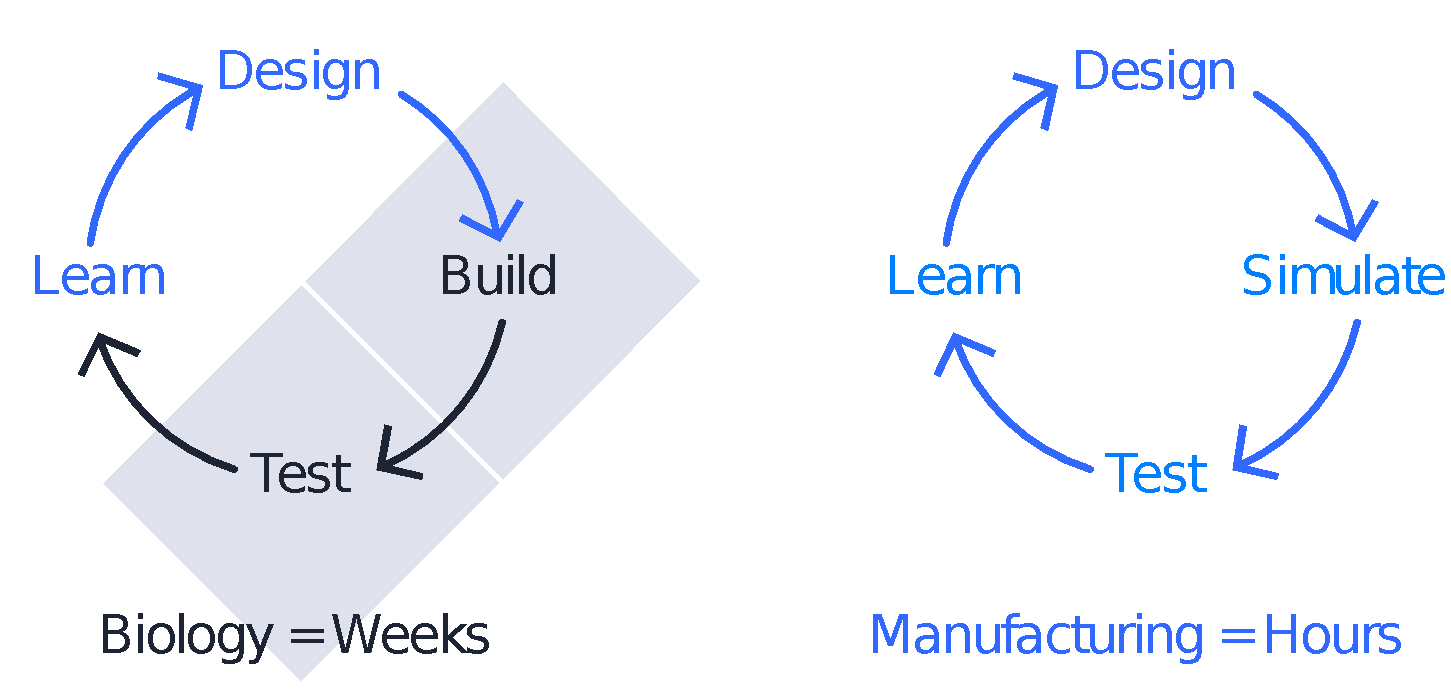
In biology we need to build and test designs in the lab.
The learning step is accomplished by entering the test results in a computer and running the learning algorithm. The data are then used to create a new set of designs that will aim to rate better against the set of user objectives. Going back to our bacteria, then, each iteration of designs both explores drastically different genetic programming and enhances previous successful bacteria strains.
Industrial biotech is already using a process similar to the one described. We are hoping that advances in design software, genetic synthesis and assembly facilities, cloud laboratories and machine learning techniques not only make this process more powerful, but make it feasible for academic labs and small startups, as well.
Without the ability to rationally design due to unknowns in biological systems, generative design is a powerful tool for biologists. It allows them to determine which designs to build and test through the lab, minimizing lab experiments. As our understanding of biology grows, we will be able to move more of these processes in silicon and design in a similar fashion as in “traditional” generative design.