
Tooling in the data science community evolves quickly, and picking the right tool for a job — not to mention a career — can often be divisive. Which tools should you try to master? What is the proper balance between difficulty, relevance and potential?
If it’s not already, Scala deserves a place at or near the top of your to-learn list — something I saw definitive evidence of last fall when I was coming off a post-doc position and considering leaving academia for the tech industry.
At the beginning of my job search, I decided to cast my net wide and speak with a large number of companies before making any kind of career decision. My original idea was to work my way through the MIT Technology Review’s list of the 50 most innovative companies of 2015 and apply for data scientist positions at each one. I ended up speaking with 54 companies and doing technical interviews with 24 of them.
The tech screenings I did generally lasted an hour and involved two to four coding problems, which I implemented in a REPL while the interviewer watched. Probability and statistics problems were either reserved for the on-site interview or dispensed with entirely (though I may have gotten a pass on this because I have a PhD).
With a few exceptions, Python was clearly frowned upon. Of course, no one ever explicitly told me I couldn’t use Python to solve a problem. The coding environments always had a Python interpreter, but the interviewers would usually suggest that I use “a compiled language” (read: Java) and they would pose data structure problems that are hard to solve in Python. For example, one problem I saw a lot was:
Keep track of the k-th largest element in a stream of integers.
This is a classic heap problem. However, Python doesn’t have a proper collections library, so to solve it I would try to import a specialized module like heapq, which usually wasn’t included in the interview environments. This made for an awkward situation. Even when I definitively solved a problem, the feedback was lukewarm.
You can use a wrench to hammer nails if that’s all you’ve got. But you’d be better off spending some time learning how to use a hammer.
The effect was notable enough that after my first week, I decided to try doing my tech screens in Scala. I did this contrary to the advice of several friends, who suggested that I suck it up and use Java. I’d been playing around with a Scala side project (PageRanking Soundcloud) and I strongly prefer Scala to Java, especially in a live coding context. I figured that since I wasn’t trying to get a job immediately, I could afford to disqualify myself a few times.
What I found surprised me. First, the interviewers actually encouraged me to use Scala even when they weren’t familiar with the language. They would trust the REPL to audit my code and use the time to address more general points. Second, the tenor of the screenings changed entirely — they became distinctly more upbeat and discursive.
The screeners would get chatty about programming languages and later follow me on Twitter. I began to enjoy the process. I added Scala and Spark to my LinkedIn and AngelList profiles. This resulted in a distinct uptick in the number of inbound interest I was receiving, especially from recruiters. The technical screens became more Scala-centric.
At first, I thought the effect was an example of Paul Graham’s famous point about programming languages (which, interestingly, was referring to Python back in 2004 when he wrote this):
The language to learn, if you want to get a good job, is a language that people don’t learn merely to get a job.
There is plenty of evidence that developer interest in Scala is on the rise. Stack Overflow’s recent developer survey listed Scala as one of the most loved languages:
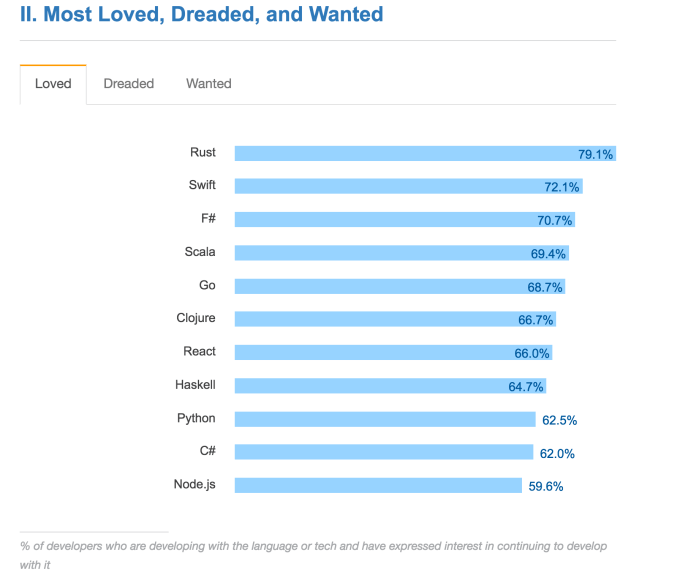
However, in many cases, the more proximal reason for their interest turned out to be Spark, which has recently surpassed Hadoop to claim the title of most active open-source data processing project. Spark is essentially distributed Scala; it uses Scala-esque ideas (closures, immutability, lazy evaluation, etc.) throughout. The Java and Python APIs are semantically quite far removed from the core design innovations of the system.
Moreover, unlike Java, Scala makes it painless to experiment with Spark. Vladimir Rokhlin once said that your comfort level with your toolchain is the major determining factor in your ability to debug code. The harder it is to check something, the less likely you are to check it. The same goes for exploratory data analysis and modeling: It is very difficult to take a rapid, iterative approach to analyzing and modeling terabyte- and petabyte-scale datasets using Hadoop.
On the other hand, the productivity boost you get from working in Spark using the native implementation language is difficult to overstate. You can use the same API — and often the same code — for small tests and large jobs, for batched data or streaming data, for ad hoc analyses or production machine learning models.
Tools [for data scientists] come and go relatively quickly in our field; ideas less so.
Scala and Spark will also teach you useful abstractions — particularly in regards to modern functional programming, the most powerful programming paradigm in general-purpose distributed data analysis. And in an era of increasing parallelism and abstraction, failing to understand these will put you at a competitive disadvantage. Conversely, if you can wrap your head around relatively deep ideas like monads, you will be well-situated to be solving hard problems in distributed data science for many years to come.
You could, in theory, learn these abstractions in Python or R — they are by no means Scala-specific. For example, Hadley Wickham (chief scientist at RStudio and nerve center of the R data science community) has lately taken to experimenting with monads in R.
But in practice you probably wouldn’t, because monads and other modern functional abstractions are practically non-existent in Python or R — two languages that were not designed for scalability either in regards to SLOC or bytes processed.
By contrast, in order to get anything significant done in Scala, you will be forced to absorb a whole host of ideas that are going to help you professionally for years to come, even if you move on to other languages. This helps you avoid getting stuck in local optima — you can use a wrench to hammer nails if that’s all you’ve got. But you’d be better off spending some time learning how to use a hammer.
This is a good educational strategy — it’s essentially the same one that MIT used when teaching their introductory computer science class in Scheme. Educational strategies like this are important for data scientists because tools come and go relatively quickly in our field; ideas less so. Therefore, the tools you want to learn are the ones that are rich vessels for forward-thinking ideas.
Scala and Spark are precisely that; furthermore, they are in a sweet spot now where they have been thoroughly de-risked as best-in-class industrial tools, but are not yet dominant. This actually does create an applicant’s market — Scala and Spark are in high demand in the U.S., both generally and in data science roles specifically.
In the end, my Scala knowledge landed me at a startup in Los Angeles where I use it, in addition to Spark, on a daily basis. And I’m not alone: Scala is already in heavy industrial use by the likes of Netflix, LinkedIn and Twitter, and it’s being embraced by more businesses every day. So if you’re looking to grow your knowledge and job prospects, now is a good time to pick up some new tools — ones designed for scalability.