Big Data is on every CIO’s mind this quarter, and for good reason. Companies will have spent $4.3 billion on Big Data technologies by the end of 2012.
But here’s where it gets interesting. Those initial investments will in turn trigger a domino effect of upgrades and new initiatives that are valued at $34 billion for 2013, per Gartner. Over a 5 year period, spend is estimated at $232 billion.
What you’re seeing right now is only the tip of a gigantic iceberg.
Big Data is presently synonymous with technologies like Hadoop, and the “NoSQL” class of databases including Mongo (document stores) and Cassandra (key-values). Today it’s possible to stream real-time analytics with ease. Spinning clusters up and down is a (relative) cinch, accomplished in 20 minutes or less. We have table stakes.
But there are new, untapped advantages and non-trivially large opportunities beyond these usual suspects.
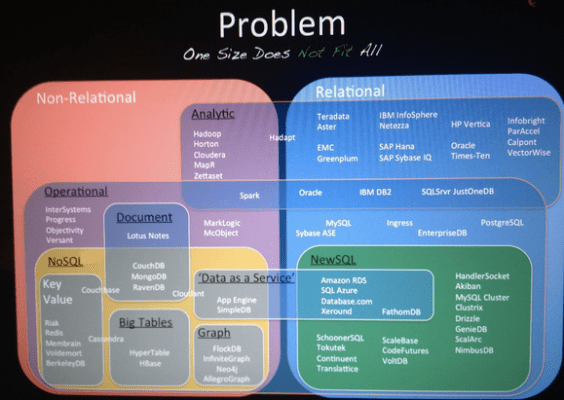
Did you know that there are over 250K viable open source technologies on the market today? Innovation is all around us. The increasing complexity of systems, in fact, looks something like this:

We have a lot of…choices, to say the least.
What’s on our own radar, and what’s coming down the pipe for Fortune 2000 companies? What new projects are the most viable candidates for production-grade usage? Which deserve your undivided attention?
We did all the research and testing so you don’t have to. Let’s look at five new technologies that are shaking things up in Big Data. Here is the newest class of tools that you can’t afford to overlook, coming soon to an enterprise near you.
Storm and Kafka
Storm and Kafka are the future of stream processing, and they are already in use at a number of high-profile companies including Groupon, Alibaba, and The Weather Channel.
Born inside of Twitter, Storm is a “distributed real-time computation system”. Storm does for real-time processing what Hadoop did for batch processing. Kafka for its part is a messaging system developed at LinkedIn to serve as the foundation for their activity stream and the data processing pipeline behind it.
When paired together, you get the stream, you get it in-real time, and you get it at linear scale.
Why should you care?
With Storm and Kafka, you can conduct stream processing at linear scale, assured that every message gets processed in real-time, reliably. In tandem, Storm and Kafka can handle data velocities of tens of thousands of messages every second.
Stream processing solutions like Storm and Kafka have caught the attention of many enterprises due to their superior approach to ETL (extract, transform, load) and data integration.
Storm and Kafka are also great at in-memory analytics, and real-time decision support. Companies are quickly realizing that batch processing in Hadoop does not support real-time business needs. Real-time streaming analytics is a must-have component in any enterprise Big Data solution or stack, because of how elegantly they handle the “three V’s” — volume, velocity and variety.
Storm and Kafka are the two technologies on the list that we’re most committed to at Infochimps, and it is reasonable to expect that they’ll be a formal part of our platform soon.
Drill and Dremel
Drill and Dremel make large-scale, ad-hoc querying of data possible, with radically lower latencies that are especially apt for data exploration. They make it possible to scan over petabytes of data in seconds, to answer ad hoc queries and presumably, power compelling visualizations.
Drill and Dremel put power in the hands of business analysts, and not just data engineers. The business side of the house will love Drill and Dremel.
Drill is the open source version of what Google is doing with Dremel (Google also offers Dremel-as-a-Service with its BigQuery offering). Companies are going to want to make the tool their own, which why Drill is the thing to watch mostly closely. Although it’s not quite there yet, strong interest by the development community is helping the tool mature rapidly.
Why should you care?
Drill and Dremel compare favorably to Hadoop for anything ad-hoc. Hadoop is all about batch processing workflows, which creates certain disadvantages.
The Hadoop ecosystem worked very hard to make MapReduce an approachable tool for ad hoc analyses. From Sawzall to Pig and Hive, many interface layers have been built on top of Hadoop to make it more friendly, and business-accessible. Yet, for all of the SQL-like familiarity, these abstraction layers ignore one fundamental reality – MapReduce (and thereby Hadoop) is purpose-built for organized data processing (read: running jobs, or “workflows”).
What if you’re not worried about running jobs? What if you’re more concerned with asking questions and getting answers — slicing and dicing, looking for insights?
That’s “ad hoc exploration” in a nutshell — if you assume data that’s been processed already, how can you optimize for speed? You shouldn’t have to run a new job and wait, sometimes for considerable lengths of time, every time you want to ask a new question.
In stark contrast to workflow-based methodology, most business-driven BI and analytics queries are fundamentally ad hoc, interactive, low-latency analyses. Writing Map Reduce workflows is prohibitive for many business analysts. Waiting minutes for jobs to start and hours for workflows to complete is not conducive to an interactive experience of data, the comparing and contrasting, and the zooming in and out that ultimately creates fundamentally new insights.
Some data scientists even speculate that Drill and Dremel may actually be better than Hadoop in the wider sense, and a potential replacement, even. That’s a little too edgy a stance to embrace right now, but there is merit in an approach to analytics that is more query-oriented and low latency.
At Infochimps we like the Elasticsearch full-text search engine and database for doing high-level data exploration, but for truly capable Big Data querying at the (relative) seat level, we think that Drill will become the de facto solution.
R
R is an open source statistical programming language. It is incredibly powerful. Over two million (and counting) analysts use R. It’s been around since 1997 if you can believe it. It is a modern version of the S language for statistical computing that originally came out of the Bell Labs. Today, R is quickly becoming the new standard for statistics.
R performs complex data science at a much smaller price (both literally and figuratively). R is making serious headway in ousting SAS and SPSS from their thrones, and has become the tool of choice for the world’s best statisticians (and data scientists, and analysts too).
Why should you care?
Because it has an unusually strong community around it, you can find R libraries for almost anything under the sun — making virtually any kind of data science capability accessible without new code. R is exciting because of who is working on it, and how much net-new innovation is happening on a daily basis. the R community is one of the most thrilling places to be in Big Data right now.
R is a also wonderful way to future-proof your Big Data program. In the last few months, literally thousands of new features have been introduced, replete with publicly available knowledge bases for every analysis type you’d want to do as an organization.
Also, R works very well with Hadoop, making it an ideal part of an integrated Big Data approach.
To keep an eye on: Julia is an interesting and growing alternative to R, because it combats R’s notoriously slow language interpreter problem. The community around Julia isn’t nearly as strong right now, but if you have a need for speed…
Gremlin and Giraph
Gremlin and Giraph help empower graph analysis, and are often used coupled with graph databases like Neo4j or InfiniteGraph, or in the case of Giraph, working with Hadoop. Golden Orb is another high-profile example of a graph-based project picking up steam.
Graph databases are pretty cutting edge. They have interesting differences with relational databases, which mean that sometimes you might want to take a graph approach rather than a relational approach from the very beginning.
The common analogue for graph-based approaches is Google’s Pregel, of which Gremlin and Giraph are open source alternatives. In fact, here’s a great read on how mimicry of Google technologies is a cottage industry unto itself.
Why should you care?
Graphs do a great job of modeling computer networks, and social networks, too — anything that links data together. Another common use is mapping, and geographic pathways — calculating shortest routes for example, from place A to place B (or to return to the social case, tracing the proximity of stated relationships from person A to person B).
Graphs are also popular for bioscience and physics use cases for this reason — they can chart molecular structures unusually well, for example.
Big picture, graph databases and analysis languages and frameworks are a great illustration of how the world is starting to realize that Big Data is not about having one database or one programming framework that accomplishes everything. Graph-based approaches are a killer app, so to speak, for anything that involves large networks with many nodes, and many linked pathways between those nodes.
The most innovative scientists and engineers know to apply the right tool for each job, making sure everything plays nice and can talk to each other (the glue in this sense becomes the core competence).
SAP Hana
SAP Hana is an in-memory analytics platform that includes an in-memory database and a suite of tools and software for creating analytical processes and moving data in and out, in the right formats.
Why should you care?
SAP is going against the grain of most entrenched enterprise mega-players by providing a very powerful product, free for development use. And it’s not only that — SAP is also creating meaningful incentives for startups to embrace Hana as well. They are authentically fostering community involvement and there is uniformly positive sentiment around Hana as a result.
Hana highly benefits any applications with unusually fast processing needs, such as financial modeling and decision support, website personalization, and fraud detection, among many other use cases.
The biggest drawback of Hana is that “in-memory” means that it by definition leverages access to solid state memory, which has clear advantages, but is much more expensive than conventional disk storage.
For organizations that don’t mind the added operational cost, Hana means incredible speed for very-low latency big data processing.
Honorable mention: D3
D3 doesn’t make the list quite yet, but it’s close, and worth mentioning for that reason.
D3 is a javascript document visualization library that revolutionizes how powerfully and creatively we can visualize information, and make data truly interactive. It was created by Michael Bostock and came out of his work at the New York Times, where he is the Graphics Editor.
For example, you can use D3 to generate an HTML table from an array of numbers. Or, you can use the same data to create an interactive bar chart with smooth transitions and interaction.
Here’s an example of D3 in action, making President Obama’s 2013 budget proposal understandable, and navigable.
With D3, programmers can create dashboards galore. Organizations of all sizes are quickly embracing D3 as a superior visualization platform to the heads-up displays of yesteryear.
Editor’s note: Tim Gasper is the Product Manager at Infochimps, the #1 Big Data platform in the cloud. He leads product marketing, product development, and customer discovery. Previously, he was co-founder and CMO at Keepstream, a social media curation and analytics company that Infochimps acquired in August of 2010. You should follow him on Twitter here.