By Tom Drabas, Senior Data Scientist, Microsoft
Tom Drabas is a Senior Data Scientist at Microsoft in the Azure Machine Learning group. His research interests include parallel computing, deep learning, and ML algorithms.
Small and large companies generate massive amounts of data. Logs coming from their services are used to find and debug issues. Free-flow text left as feedback on their websites is used to gauge customer sentiment. Interactions derived from social channels are used to find new markets and expand the demand for their products. Sales data is used to plan their supply channels to minimize out-of-stock occurrences and maximize revenue. There are many more examples.
These days, the sources of data can be found anywhere and the amount and velocity of the data is mind-boggling: a self-driving car generates around 3.5TB data an hour. And every hour Instagram users post ~3M photos — at 10MB per photo, that’s around 29TB an hour of content.
Companies rely on internal and external data to make informed decisions about their clients, as well as the opportunities and threats to their business. Making sense of this sea of data is not an easy feat. It requires cooperation between a large group of data-, machine-, and deep learning scientists and engineers, working together to deliver timely and accurate insights and predictions. It also requires new and novel hardware and algorithmic advances capable of processing this ever-growing stream of big data.
Why does this matter?
For many industries, predicting the correct demand for their products or services is paramount to their survival. The airline business depends on accurate estimations of true demand for each price point, on each flight, for every route to make informed decisions about how many seats to offer at prices that maximize revenues. Large retailers make decisions about how many goods to order so they minimize the cost of storage, while keeping the risk of out-of-stock occurrences at bay. And large tech companies serving ads (like Bing or Google) build large models to better fit the composition of their ads so that it increases click-through rates.
Even if the data is not fast moving, the amount of it produced can strain the capabilities of current systems and methods. What would have sufficed 10 years ago would fall far short of meeting current requirements. Taking shortcuts like data sampling or sub-optimal machine learning models carries a very real possibility of making, at best, a suboptimal or, at worst, an ill-advised decision that might put the prosperity, or even the survival, of a company at risk.
More importantly, though, in the case of self-driving cars, human lives are at stake. Self-driving cars require processing data to come from all the sensors and cameras in a fast and highly accurate manner. If they don’t, driving even 25mph could quickly have catastrophic consequences.
Accelerating the enterprise
Historically speaking, enterprise machine learning or any data analytics has been done on mainframe computers or large farms of specialized machines. With the advent of general-purpose computing on graphics processing units (GPUs) via the NVIDIA CUDA programming model, many compute-intense task have been off-loaded to highly parallel hardware on a GPU.
Many algorithms nowadays rely heavily on GPUs for their efficiency and compute power. GPUs are especially popular in deep-learning applications that require enormous amounts of operations on tensors. For example, a single NVIDIA V100 GPU can process 1,525 images/sec training ResNet-50, compared with 48 images/sec when training the same network on an Intel Xeon Gold 6240 (source: volta-v100-datasheet-update-us-1165301-r5.pdf).
These speed-ups allow for faster iterations over models, better search through the hyper-parameter space, and usage of all the data, not just a sample. Armed with NVIDIA GPUs, deep learning researchers and practitioners are now equipped with a workhorse that can significantly speed up knowledge discovery and deliver more accurate insights faster.
Accelerating data science
Until recently, the speed-ups that GPUs enabled were mostly limited to deep learning applications. However, this landscape changed significantly in October 2018, when NVIDIA released the first version of RAPIDS, which enables GPU acceleration for popular PyData APIs like Pandas, Scikit-learn, NetworkX, and more.
The framework equips data scientists and engineers with tools that speed up extract, transform, and load (ETL) tasks using cudf, and significantly accelerates popular machine learning algorithms like XGBoost, Random Forests, and KNN in cuml. But the framework does not stop there. RAPIDS has native support for graphs in cugraph, can speed up geospatial applications in cuspatial, perform complex signal analyses using cusignal and help enterprises fight bad guys using clx.
If this was not enough, RAPIDS can scale up (to multiple GPUs within the same machine) and out (to multiple nodes with multiple GPUs) using Dask. Dask is a framework initially developed to scale pandas that has been adopted to scale the RAPIDS suite of open source software.
With RAPIDS and Dask, enterprises can now compute tasks that used to take hours or days and finish them in minutes (or seconds as some of the speed-ups available in cugraph and cuml frameworks have been reported to be in the 1,000x-10,000x range). What this means for companies is faster, more accurate data science, delivered at scale, and likely cheaper than with CPU-only based frameworks.
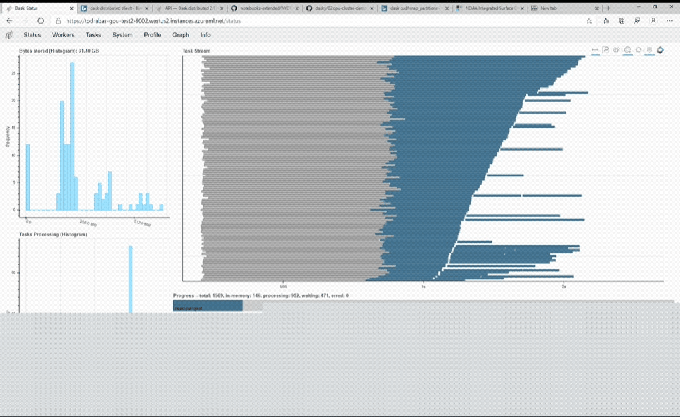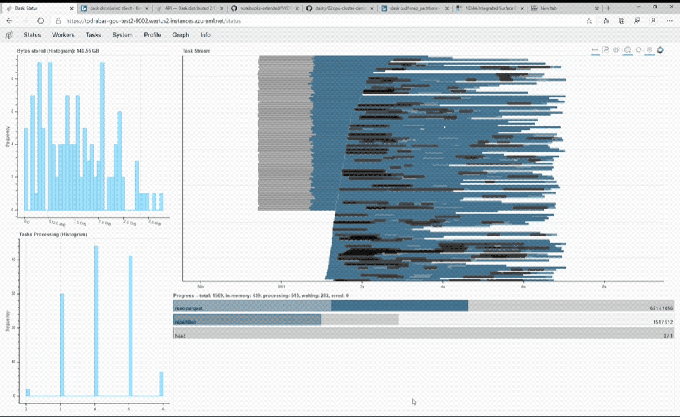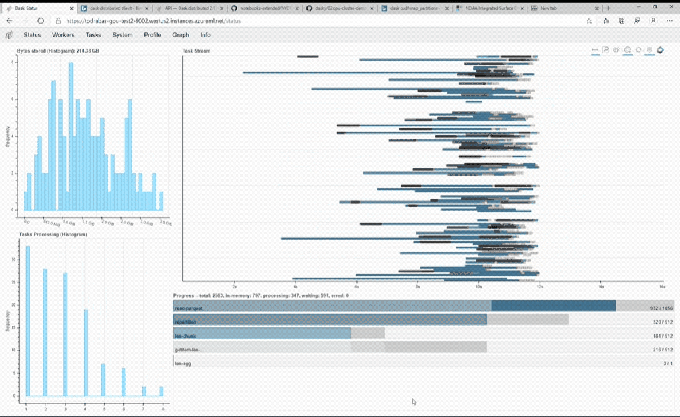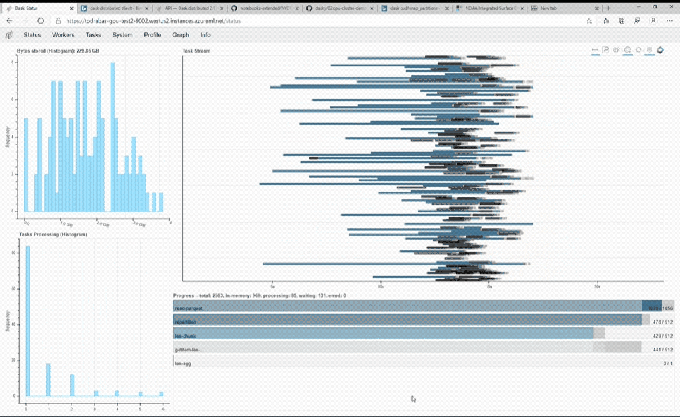
Image Credits: NVIDIA
If you or your company are interested in learning more about NVIDIA RAPIDS, and how it can help deliver data science at the speed of thought, NVIDIA’s GTC Digital online conference will publish many great talks and workshops led by the RAPIDS team and industry experts. You can also learn how to easily deploy and train your models during a “Speed Up Your Data Science Tasks By a Factor of 100+ Using AzureML and NVIDIA RAPIDS” session that will work through the process of setting up Dask in the cloud and running data science workloads with RAPIDS. It will be posted the week of March 30 and you can register for free here.
Expanding markets, researching new products and services, and responding to customer needs are fundamental for any successful company. Achieving these goals in today’s enterprise environment requires cost-effectively processing enormous amounts of data. This is why data science matters in the enterprise and why RAPIDS is a game-changer in this space. It enables fast and accurate data processing and analytics.