By: Sam Ramji (@sramji)
Cloud native Apache Cassandra
Along with tens of thousands of developers and operators, and companies ranging from startups to titans like Apple and Netflix, we want to see Apache Cassandra™ become cloud-native.
We have done the work required to have an opinion: Astra is built on Kubernetes, Prometheus, Envoy, and participates in the GKE and EKS native control and management planes. We’ve reviewed work done by others, particularly those who have shared what they have learned in the form of open source Kubernetes operators for Cassandra (C*).
The opinion expressed in Astra is based on the technical work, changes, and trade-offs we’ve needed to make in order to operate C* at scale on Kubernetes in the cloud. This opinion will continue to evolve as we continue to deliver and improve Astra.
We are sharing that opinion in contributions to the C* open source ecosystem – as OSS projects including a Kubernetes operator, a management sidecar, a metrics collector, a configuration builder, and a NoSQL testing system.
The corollary of sharing an opinion is listening to others. Through the Cassandra Enhancement Proposal process, we see a vibrant set of hard-won experiences that have led to many Kubernetes operators for Cassandra. Shared listening will lead us all to think and work together, improving our opinions with collective experience, and releasing better code for users.
What we are learning
We’ve learned about the structure and architecture of Apache Cassandra as it relates to cloud deployment. This is helping us contribute to the community’s thinking on the architectural choices we will need to make together after the release of C* 4.0.
We’ve put some of that into practice in our fork of Cassandra, and we expect to share this in the future. We’ve put as much as possible into code that complements Cassandra to solve for Kubernetes-specific and cloud-native needs.
There are four areas of work needed to run a cloud-native service with Apache Cassandra 3.11: gateway, operations, management, and deployment.
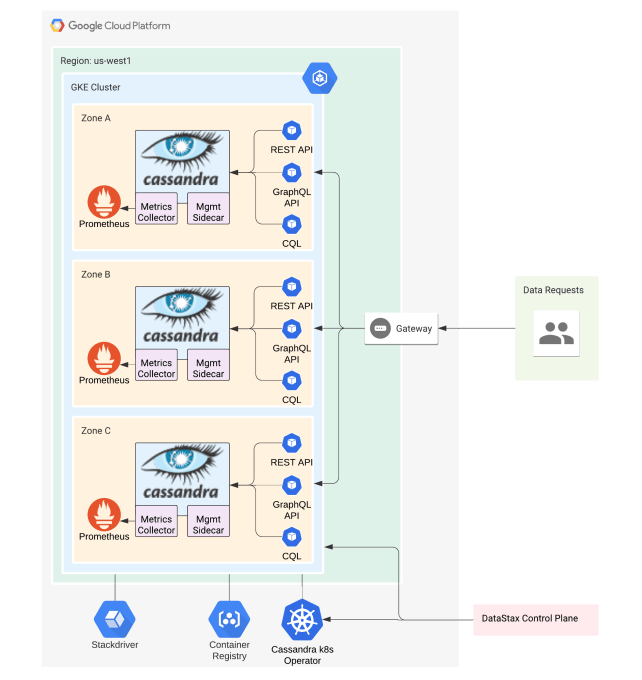
Fig 1. High-level architecture of Astra on GKE/GCP
Gateway
Astra clusters receive traffic through the gateway. Astra uses Envoy to route Cassandra binary port requests and simplify driver configuration. In cloud native configurations, having a single ingress IP is critical for managing connectivity with an elastic backend. This also reduces the number of open ports exposed. This enables Astra to support CQL in the cloud while being elastic and secure.
Astra also uses the gateway to expose REST and GraphQL APIs for easing developer burden when interacting with data assets. We believe that these better serve a new generation of developers with experience in full-stack application development.
Operations
Cluster operations need to be automated. Astra does this with a pair of components: Cass Operator and Management API for Apache Cassandra (MAAC). Cass Operator is a Kubernetes Operator for Apache Cassandra and the MAAC is a Kubernetes sidecar.
Cass Operator provides a StatefulSet of C* nodes and automates the manual tasks normally performed by C* administrators. This includes the start sequence for bringing up a cluster, draining nodes when they are deleted, and putting the right nodes in the right pods, such as preventing multiple nodes from deploying to the same host.
Participating gracefully in a Kubernetes environment requires providing insight into the cluster state. In practice, this means that some operations that were previously database internals, such as automated retries, or establishing Gossip links to track internal cluster state, are raised up to the application layer.
Kubernetes can then make decisions based on the health of the whole cluster, rather than each C* node making independent decisions based on its own view. For example, during a rolling restart, instead of internal checks to see that a node is up, those signals are raised to Cass Operator, which makes sure that every C* node in the cluster can achieve quorum.
MAAC provides a JSON interface to invoke nodetool commands and inject Vault secrets. This makes C* feel more like Kubernetes while retaining operational consistency with standard C* tooling. This component starts, stops, configures, and checks liveness and consistency levels. MAAC runs as a sidecar and communicates with C* via CQL via a local Unix socket (optionally over mTLS). Each sidecar process is responsible for the local C* instance only. This simplifies the topology and reinforces the role of Cass Operator as the orchestrator for the cluster.
Management
Metrics are essential for running C* at scale. Astra uses a Metrics Collector for Apache Cassandra (MCAC) to provide management functions that integrate with Kubernetes and cloud environments.
MCAC simplifies metrics collection for Cassandra users. The traditional mechanism for metrics in C* is JMX, which does not match the performance and scale needs for a deployment on Kubernetes. MCAC is built on collectd and is bundled into Cass Operator. It works for all open source Apache Cassandra versions from 2.2 to 4.0 beta. Using collectd means that hundreds of thousands of series per node can be exported with minimal impact on C* performance. It aligns with Prometheus, the standard in Kubernetes environments for monitoring, and MCAC metrics can be analyzed along with OS-level metrics such as context switches, disk performance, and network performance. Finally, MCAC creates a historical log of metrics and lifecycle events such as flushes, compactions, exceptions, and garbage collection.
MCAC is a critical part of Astra’s ability to give users visibility into the real-time running characteristics of their instance. Astra fully manages the operations of the underlying Cassandra nodes, but users need to understand the impacts of their data model and queries on the operational characteristics of the cluster.
Deployment
Deployment is continuous in a Kubernetes environment. By relinquishing control of configuration changes to the operator, Astra is able to provide a more dynamic and trustworthy data layer. Astra uses cass-config-builder to drive configuration and NoSQLBench for continuous testing of the environment..
Cass-config-builder parametrically generates cassandra.yaml files based on environment requirements. When a C* pod is started up, it ingests this configuration. IP addresses, network information, performance tuning, security, disk optimization, seed providers are all key components for running C* correctly. As Kubernetes controls the overall environment while scaling up and down, reacting to hardware failure, or changing fleet-wide properties, C* needs to adopt new configurations.
NoSQLBench gives users the ability to create arbitrarily sized synthetic datasets and use those datasets to execute large scale load tests based on real-world application workloads to ensure that the cluster is trustworthy. It works with any NoSQL database. As part of a continuous deployment environment, test automation for the database can drive billions of write and read operations, thrashing storage volumes and demonstrating the cloud environment’s performance characteristics empirically.
Closing thoughts
Our aim is to use our ten years of experience building and operating enterprise Cassandra deployments to build a world-class cloud-native service for Apache Cassandra.
Everything we see in feedback from Cassandra users tells us that Kubernetes needs Cassandra and Cassandra needs Kubernetes. We’re building our “Cassandra-as-a-Service” on Kubernetes so that we are in the thick of the fight to make C* the best open source, scale-out, cloud-native database in the world.
Cassandra is becoming cloud-native. We’re thrilled to be on that journey with all of you.
For more information on Asta, visit: https://astra.datastax.com/register
This article was originally posted on the DataStax blog.