A few days after OpenAI announced a set of privacy controls for its generative AI chatbot, ChatGPT, the service has been made available again to users in Italy — resolving (for now) an early regulatory suspension in one of the European Union’s 27 Member States, even as a local probe of its compliance with the region’s data protection rules continues.
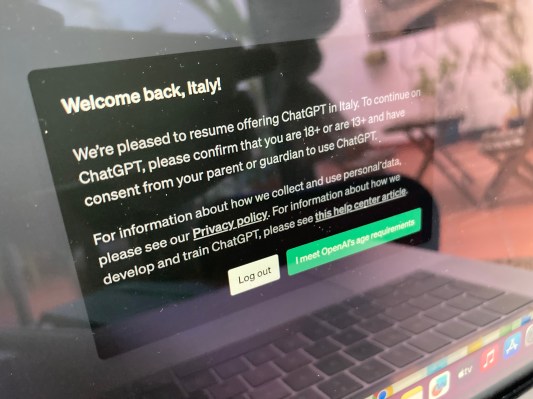
At the time of writing, web users browsing to ChatGPT from an Italian IP address are no longer greeted by a notification instructing them the service is “disabled for users in Italy”. Instead they are met by a note saying OpenAI is “pleased to resume offering ChatGPT in Italy”.
The pop-up goes on to stipulate that users must confirm they are 18+ or 13+ with consent from a parent or guardian to use the service — by clicking on a button stating “I meet OpenAI’s age requirements”.
The text of the notification also draws attention to OpenAI’s Privacy Policy and links to a help center article where the company says it provides information about “how we develop and train ChatGPT”.
The changes in how OpenAI presents ChatGPT to users in Italy are intended to satisfy an initial set of conditions set by the local data protection authority (DPA) in order for it to resume service with managed regulatory risk.
Quick recap of the backstory here: Late last month, Italy’s Garante ordered a temporary stop-processing order on ChatGPT, saying it was concerned the services breaches EU data protection laws. It also opened an investigation into the suspected breaches of the General Data Protection Regulation (GDPR).
OpenAI quickly responded to the intervention by geoblocking users with Italian IP addresses at the start of this month.
The move was followed, a couple of weeks later, by the Garante issuing a list of measures it said OpenAI must implement in order to have the suspension order lifted by the end of April — including adding age-gating to prevent minors from accessing the service and amending the legal basis claimed for processing local users’ data.
The regulator faced some political flak in Italy and elsewhere in Europe for the intervention. Although it’s not the only data protection authority raising concerns — and, earlier this month, the bloc’s regulators agreed to launch a task force focused on ChatGPT with the aim of supporting investigations and cooperation on any enforcements.
In a press release issued today announcing the service resumption in Italy, the Garante said OpenAI sent it a letter detailing the measures implemented in response to the earlier order — writing: “OpenAI explained that it had expanded the information to European users and non-users, that it had amended and clarified several mechanisms and deployed amenable solutions to enable users and non-users to exercise their rights. Based on these improvements, OpenAI reinstated access to ChatGPT for Italian users.”
Expanding on the steps taken by OpenAI in more detail, the DPA says OpenAI expanded its privacy policy and provided users and non-users with more information about the personal data being processed for training its algorithms, including stipulating that everyone has the right to opt out of such processing — which suggests the company is now relying on a claim of legitimate interests as the legal basis for processing data for training its algorithms (since that basis requires it to offer an opt out).
Additionally, the Garante reveals that OpenAI has taken steps to provide a way for Europeans to ask for their data not to be used to train the AI (requests can be made to it by an online form) — and to provide them with “mechanisms” to have their data deleted.
It also told the regulator it is not able to fix the flaw of chatbots making up false information about named individuals at this point. Hence introducing “mechanisms to enable data subjects to obtain erasure of information that is considered inaccurate”.
European users wanting to opt-out from the processing of their personal data for training its AI can also do so by a form OpenAI has made available which the DPA says will “thus to filter out their chats and chat history from the data used for training algorithms”.
So the Italian DPA’s intervention has resulted in some notable changes to the level of control ChatGPT offers Europeans.
That said, it’s not yet clear whether the tweaks OpenAI has rushed to implement will (or can) go far enough to resolve all the GDPR concerns being raised.
For example, it is not clear whether Italians’ personal data that was used to train its GPT model historically, i.e. when it scraped public data off the Internet, was processed with a valid lawful basis — or, indeed, whether data used to train models previously will or can be deleted if users request their data deleted now.
The big question remains what legal basis OpenAI had to process people’s information in the first place, back when the company was not being so open about what data it was using.
The US company appears to be hoping to bound the objections being raised about what it’s been doing with Europeans’ information by providing some limited controls now, applied to new incoming personal data, in the hopes this fuzzes the wider issue of all the regional personal data processing it’s done historically.
Asked about the changes it’s implemented, an OpenAI spokesperson emailed TechCrunch this summary statement:
ChatGPT is available again to our users in Italy. We are excited to welcome them back, and we remain dedicated to protecting their privacy. We have addressed or clarified the issues raised by the Garante, including:
A new help center article on how we collect and use training data.
Greater visibility of our Privacy Policy on the OpenAI homepage and ChatGPT login page.
Greater visibility of our user content opt-out form in help center articles and Privacy Policy.
Continuing to offer our existing process for responding to privacy requests via email, as well as a new form for EU users to exercise their right to object to our use of personal data to train our models.
A tool to verify users’ ages in Italy upon sign-up.
We appreciate the Garante for being collaborative, and we look forward to ongoing constructive discussions.
In the help center article OpenAI admits it processed personal data to train ChatGPT, while trying to claim that it didn’t really intent to do it but the stuff was just lying around out there on the Internet — or as it puts it: “A large amount of data on the internet relates to people, so our training information does incidentally include personal information. We don’t actively seek out personal information to train our models.”
Which reads like a nice try to dodge GDPR’s requirement that it has a valid legal basis to process this personal data it happened to find.
OpenAI expands further on its defence in a section (affirmatively) entitled “how does the development of ChatGPT comply with privacy laws?” — in which it suggests it has used people’s data lawfully because A) it intended its chatbot to be beneficial; B) it had no choice as lots of data was required to build the AI tech; and C) it claims it did not mean to negatively impact individuals.
“For these reasons, we base our collection and use of personal information that is included in training information on legitimate interests according to privacy laws like the GDPR,” it also writes, adding: “To fulfill our compliance obligations, we have also completed a data protection impact assessment to help ensure we are collecting and using this information legally and responsibly.”
So, again, OpenAI’s defence to an accusation of data protection law-breaking essentially boils down to: ‘But we didn’t mean anything bad officer!’
Its explainer also offers some bolded text to emphasize a claim that it’s not using this data to build profiles about individuals; contact them or advertise to them; or try to sell them anything. None of which is relevant to the question of whether its data processing activities have breached the GDPR or not.
The Italian DPA confirmed to us that its investigation of that salient issue continues.
In its update, the Garante also notes that it expects OpenAI to comply with additional requests laid down in its April 11 order — flagging the requirement for it to implement an age verification system (to more robustly prevent minors accessing the service); and to conduct a local information campaign to inform Italians of how it’s been processing their data and their right to opt-out from the processing of their personal data for training its algorithms.
“The Italian SA [supervisory authority] acknowledges the steps forward made by OpenAI to reconcile technological advancements with respect for the rights of individuals and it hopes that the company will continue in its efforts to comply with European data protection legislation,” it adds, before underlining that this is just the first pass in this regulatory dance.
Ergo, all OpenAI’s various claims to be 100% bona fide remain to be robustly tested.