
Remember the cable, phone and internet combo offers that used to land in our mailboxes? These offers were highly optimized for conversion, and the type of offer and the monthly price could vary significantly between two neighboring houses or even between condos in the same building.
I know this because I used to be a data engineer and built extract-transform-load (ETL) data pipelines for this type of offer optimization. Part of my job involved unpacking encrypted data feeds, removing rows or columns that had missing data, and mapping the fields to our internal data models. Our statistics team then used the clean, updated data to model the best offer for each household.
That was almost a decade ago. If you take that process and run it on steroids for 100x larger datasets today, you’ll get to the scale that midsized and large organizations are dealing with today.
Each step of the data analysis process is ripe for disruption.
For example, a single video conferencing call can generate logs that require hundreds of storage tables. Cloud has fundamentally changed the way business is done because of the unlimited storage and scalable compute resources you can get at an affordable price.
To put it simply, this is the difference between old and modern stacks:
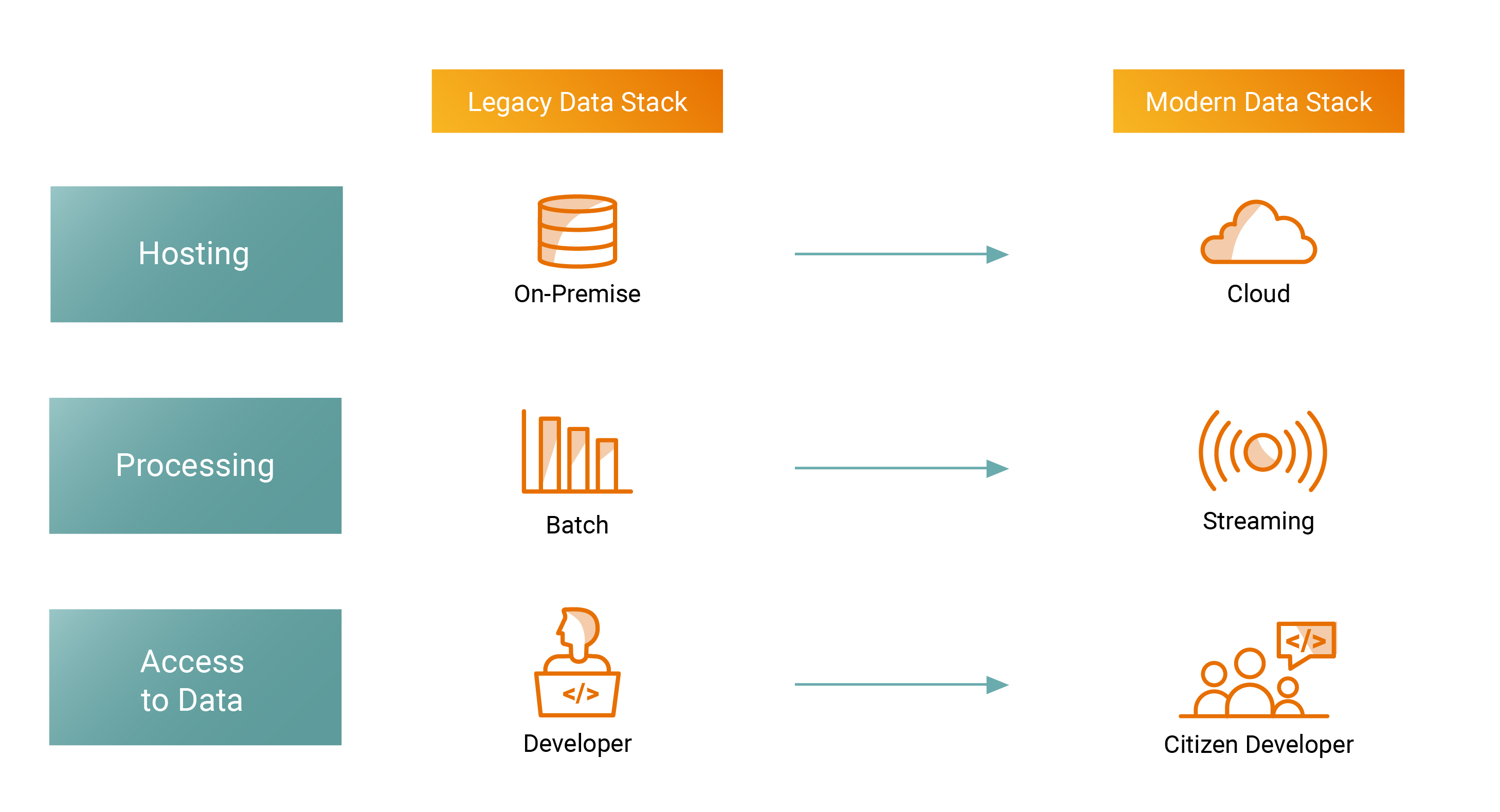
Image Credits: Ashish Kakran, Thomvest Ventures
Why do data leaders today care about the modern data stack?
Self-service analytics
Citizen-developers want access to critical business dashboards in real time. They want automatically updating dashboards built on top of their operational and customer data.
For example, the product team can use real-time product usage and customer renewal data for decision-making. Cloud makes data truly accessible to everyone, but there is a need for self-service analytics compared to legacy, static, on-demand reports and dashboards.
Serving predictions
Once machine learning models are trained and ready to be used, there needs to be an easy way for different teams within an organization to benefit from them. This is typically achieved via a simple URL that accepts requests and returns predictions. Building these microservices and maintaining them is a core challenge when you are serving thousands of HTTP requests per second.
Data transformation
Data scientists want to be able to track older versions of data so that they can run experiments and know what version of data was used to complete training. This need is creating popular products that are optimized for in-place transformation of data.
Data quality
Some cutting-edge data organizations now prefer a data-centric approach to a model-centric approach. The belief that more data means better results is being replaced by the belief that the quality of data matters more. Typically, trained models are observed using two parameters, precision and recall. Precision tells you the proportion of positive identification that was actually correct, and recall tells you the proportion of actual positives that were correctly identified. Now imagine ensuring data quality for real-time data streams coming at you in a variety of different formats.
How do the legacy and modern data stacks compare?
Generally speaking, the modern data stack is about leveraging cloud resources to more effectively analyze complex streaming data.
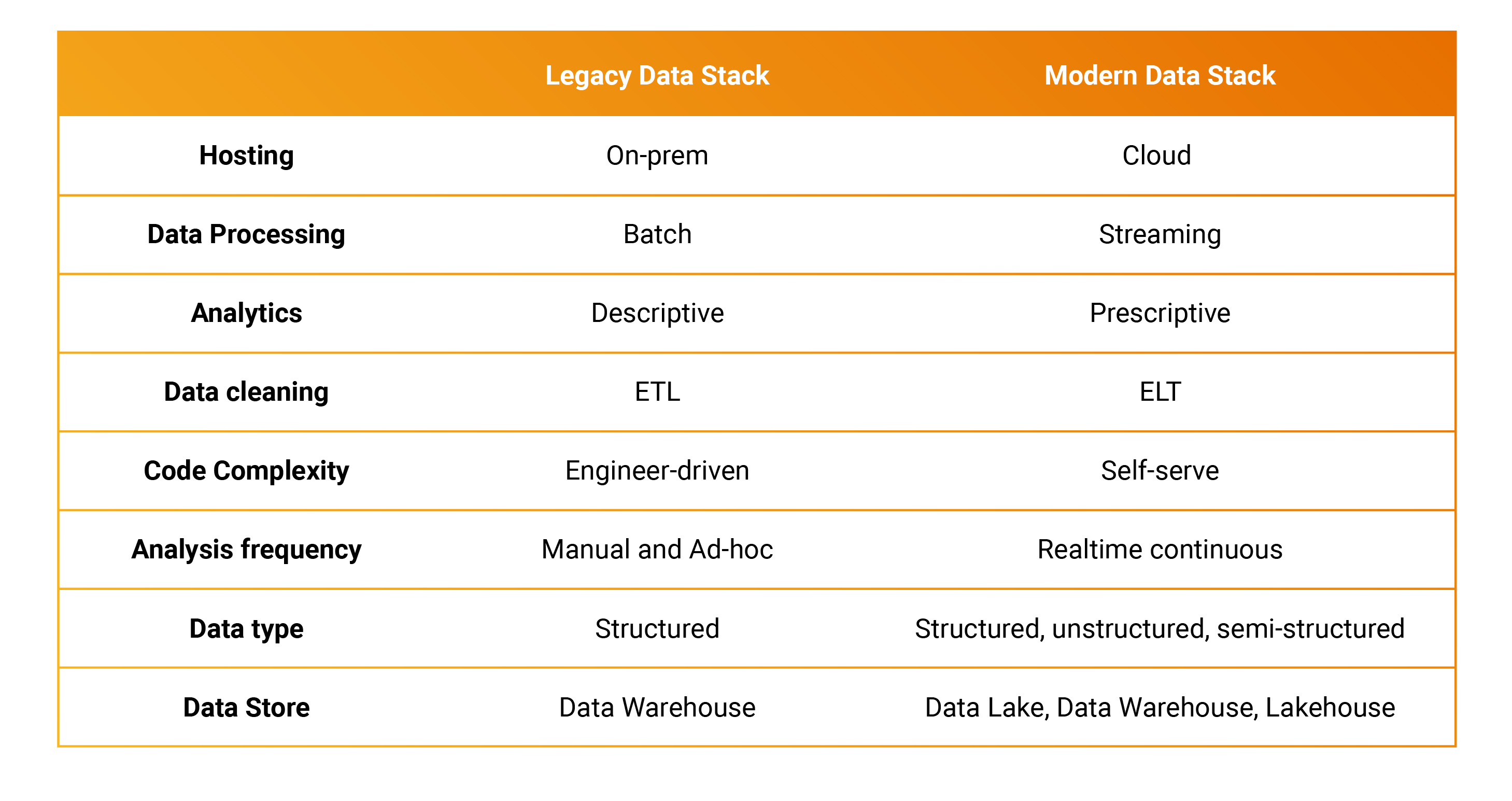
Image Credits: Ashish Kakran, Thomvest Ventures
Here are a few key trends that enterprises should note:
- The ETL process is becoming EL (T), which means the data is first dumped as it is received in certain locations like a data lake. This way, the storage systems don’t complain about the format of data as it is stored. Once the data is stored, then it can be processed in-place for analytics. By doing this, the firehose of continuous data can be more effectively managed, processed and analyzed.
- Data observability has become critical. Data fails silently, and with rapidly evolving data stacks, it is necessary to be able to monitor data and set alerts to fix issues. You don’t want your trained models that teach Spanish to accidently train on English words or on missing data. One just can’t visually analyze and fix millions of rows of data.
- The emergence of the chief data/AI/data and analytics officer. Data is such a complex problem that CIOs now have CDOs/CAOs/CDAOs reporting to them. While we started the 21st Century talking about data as competitive advantage, we are now in a time when unmanaged data becomes toxic. There are regulatory laws about how data can be used, shared or handled. How do you comply with a customer’s request to delete all their data if you don’t even know where and in what form it is stored in?
Opportunities
Each step of the data analysis process is ripe for disruption. While visionary founders are building cloud-native tools to win emerging data categories, the incumbents have been slower to react. Whether building data pipelines or ML pipelines, organizations today have a variety of open and closed source technologies to choose from.
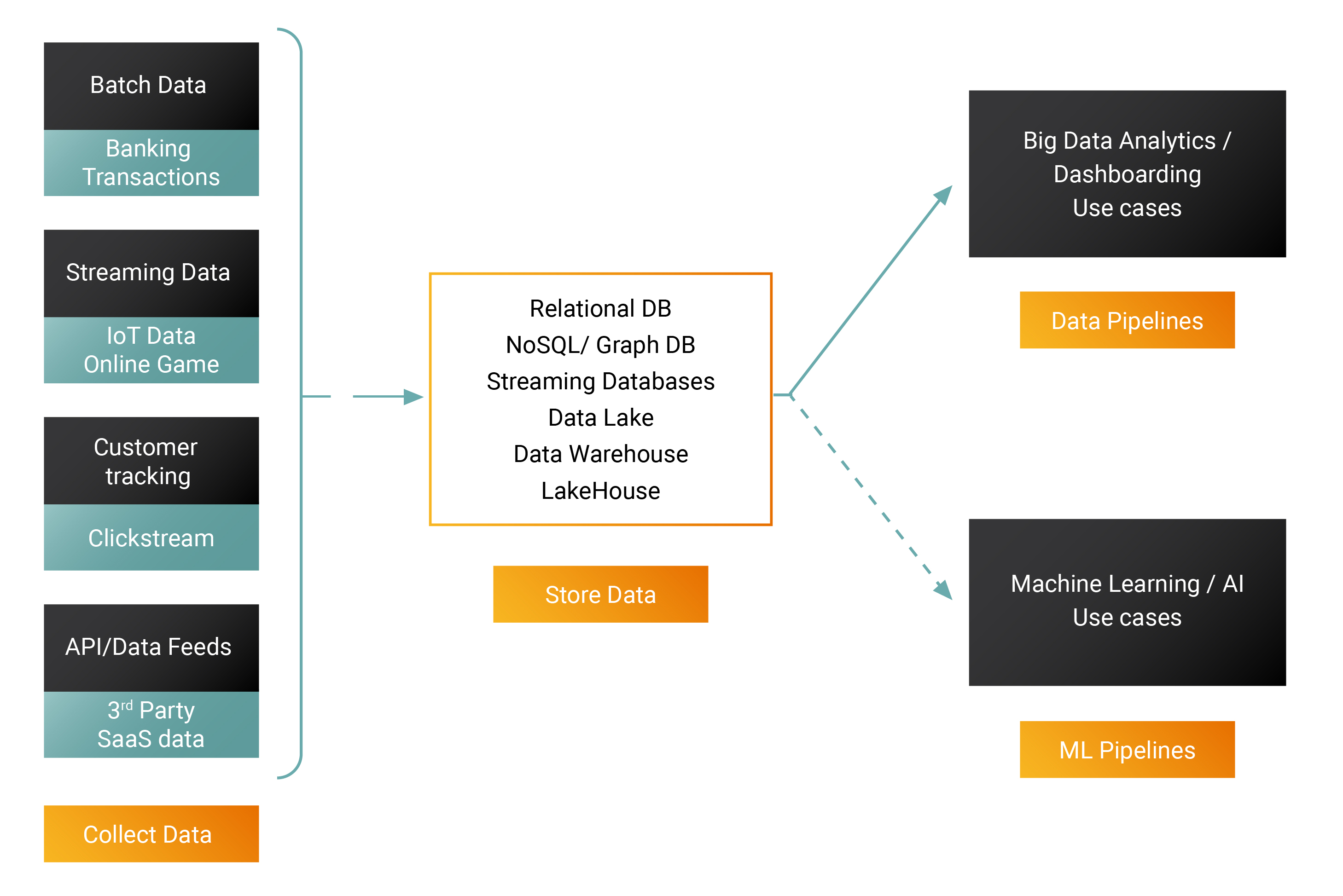
Image Credits: Ashish Kakran, Thomvest Ventures
Practitioners are spoilt for choices when building enterprise data pipelines.
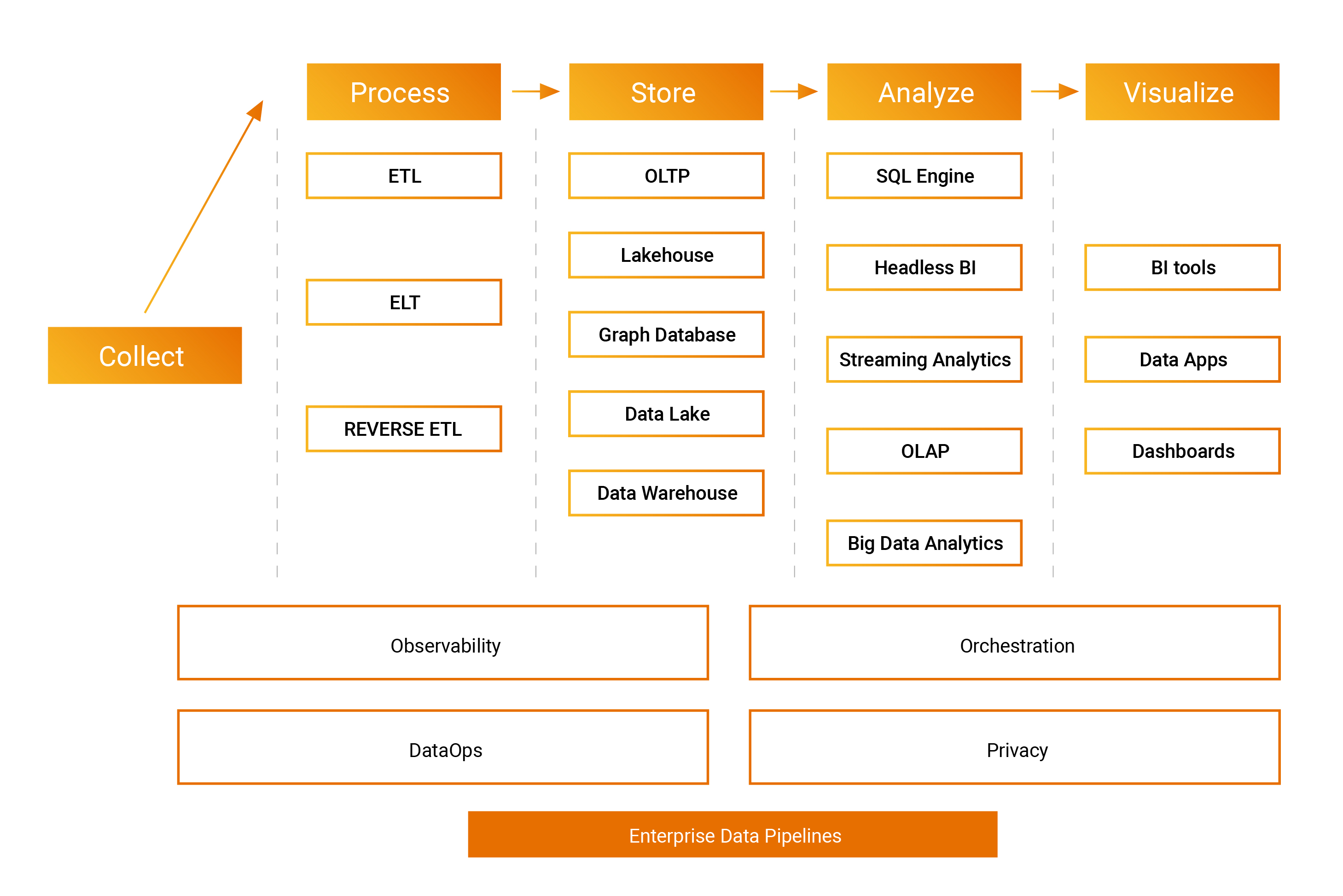
Image Credits: Ashish Kakran, Thomvest Ventures
The efficient data stack for data engineers, database developers and data scientists changes every four to five years. Companies moved to big data analytics to analyze large datasets in private data centers, and though it promised many benefits, big data remains technically complex to implement. The modern data stack makes this easy by leveraging the scale, reliability and resilience of the cloud.
The rules are being rewritten on how data will be used for competitive advantage, and it won’t be long before the winners emerge. Incumbents are redesigning their legacy software to run on the cloud, but our bet is on nimble teams run by visionary founders.