
IT systems are becoming increasingly complex, what with the mass move to the cloud during the pandemic. The modern data stack consists of hundreds of tools for app development, data capture and integration, orchestration, analysis and storage. And it’s getting bigger and more convoluted by the day. According to Productiv, a software-as-a-service app management startup, the average company had 254 internal tools as of last September, with most departments wrangling 40 to 60 each.
Angling to address the growing challenges, Kunal Agarwal and Shivnath Babu co-founded Unravel Data, a platform designed to give developer teams visibility across data stacks, troubleshoot and optimize data workloads and define guardrails to govern costs. In a sign business is going strong, Unravel today closed a $50 million Series D funding round led by Third Point Ventures with participation from Bridge Bank, Menlo Ventures, Point 72, GGV Capital and Harmony Capital, bringing its total raised to $107 million.
“Regardless of what industry an enterprise competes in, the one thing that each has in common with each other is the understanding that being able to transform raw data into actionable insights is directly proportional to their ability to deliver new innovations to market,” Agarwal told TechCrunch in an email interview. “For that reason, despite the economic uncertainty brought about by the pandemic, we’ve seen strong and sustained interest in both the [observability] methodology in general and the Unravel platform in particular.”
Agarwal and Babu met at Duke University, where Babu was a tenured professor researching how to make data-intensive compute systems easier to manage. Agarwal previously was at Sun Microsystems, where he was a grid computing specialist and a member of the sales team. The two say that they saw an opportunity to create a platform that takes all the different big data workload granularities across an organization and presents them in a single pane of glass.
Unravel attempts to correlate details from a data stack, then applies AI and machine learning to give recommendations and insights on how to — in Agarwal’s words — “make things better.” For instance, the platform automatically implements guardrails for things like cost overruns and errors, sending alerts when something goes wrong.
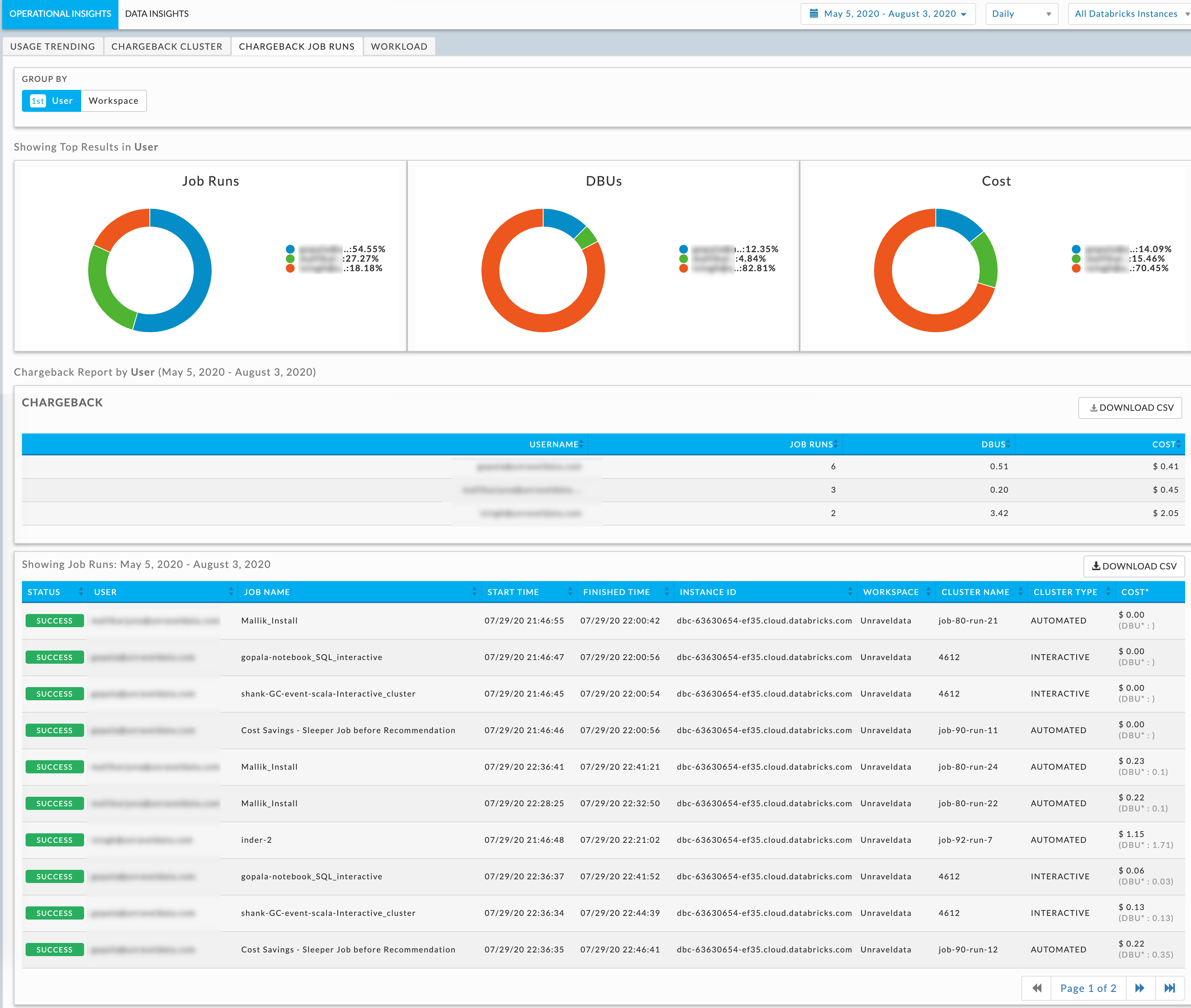
Unravel Data’s web-based data monitoring dashboard in action. Image Credits: Unravel Data
“Because we capture and correlate details at a highly granular level — configuration, resources, containers, code, datasets, lineage and dependencies — down to the individual user or job or sub-parts of jobs processing in parallel, Unravel’s AI engines establish dynamic baselines across multiple dimensions, detect anomalies with contextual awareness and provide actionable intelligence via recommendations and insights,” Agarwal said. “For example, if a job that usually takes three minutes to run suddenly is taking 10 minutes, was it because the size of data being processed doubled and now we’re hitting out-of-memory problems? If so, why is there so much more data now? Where did that dataset come from? Who doubled its size? Is that intentional? What and how does that impact other, dependent jobs downstream?”
Unravel is fundamentally a data observability platform, a technology for which investors appear to have an insatiable appetite. In the span of one week last June, three data observability startups — Cribl, Monte Carlo and Coralogix — raised more than $400 million in venture capital. Other big players in the space include performance management tools developer Observe, stream processing platform Edge Delta, data lineage platform Manta and open observability platform Grafana Labs.
Agarwal doesn’t see much overlap between Unravel and app monitoring solutions like Datadog, Dynatrace and New Relic, which he perceives as tackling a very different data orchestration problem. As for observability vendors such as the aforementioned Monte Carlo, he asserts that they only solve pieces of the data stack puzzle and lack the modeling capabilities of Unravel’s product.
“Newer cloud technologies provide greater agility and innovation but come at the cost of increased complexity. It’s getting harder and harder for leaders to ensure that they’re actually getting value and return on their investment,” Agarwal said. “Many organizations are seeing their data migrations stall out because of budget overruns and spiraling costs. And as the data stack gets more complex, it becomes harder to untangle the wires to figure out what went wrong and how to fix it. Unravel makes it easier for different members of data teams, with varying skill sets and levels of expertise, to do more self-service troubleshooting and optimization.”
Agarwal declined to reveal Unravel’s revenue or the size of the company’s customer base. But he did say that Adobe and Deutsche Bank are among its clients, as well as grocery chain Kroger’s 84.51° data analytics subsidiary.
With an eye toward the horizon, Agarwal said that the proceeds from the Series D will be put toward scaling Unravel’s operations, building APIs to ingest data from an expanded number of apps and “doubling” the size of Unravel’s engineering team. He didn’t commit to near-term hiring plans, but noted that Unravel, which currently has more than 100 employees across the U.S., Europe and India, is hiring for technical and operation roles.