
Research in the field of machine learning and AI, now a key technology in practically every industry and company, is far too voluminous for anyone to read it all. This column, Perceptron, aims to collect some of the most relevant recent discoveries and papers — particularly in, but not limited to, artificial intelligence — and explain why they matter.
In this batch of recent research, Meta open-sourced a language system that it claims is the first capable of translating 200 different languages with “state-of-the-art” results. Not to be outdone, Google detailed a machine learning model, Minerva, that can solve quantitative reasoning problems including mathematical and scientific questions. And Microsoft released a language model, Godel, for generating “realistic” conversations that’s along the lines of Google’s widely publicized Lamda. And then we have some new text-to-image generators with a twist.
Meta’s new model, NLLB-200, is a part of the company’s No Language Left Behind initiative to develop machine-powered translation capabilities for most of the world’s languages. Trained to understand languages such as Kamba (spoken by the Bantu ethnic group) and Lao (the official language of Laos), as well as over 540 African languages not supported well or at all by previous translation systems, NLLB-200 will be used to translate languages on the Facebook News Feed and Instagram in addition to the Wikimedia Foundation’s Content Translation Tool, Meta recently announced.
AI translation has the potential to greatly scale — and already has scaled — the number of languages that can be translated without human expertise. But as some researchers have noted, errors spanning incorrect terminology, omissions and mistranslations can crop up in AI-generated translations because the systems are trained largely on data from the internet — not all of which is high-quality. For example, Google Translate once presupposed that doctors were male, while nurses were female, while Bing’s translator translated phrases like “the table is soft” as the feminine “die Tabelle” in German (which refers to a table of figures).
For NLLB-200, Meta said it “completely overhauled” its data cleaning pipeline with “major filtering steps” and toxicity-filtering lists for the full set of 200 languages. It remains to be seen how well it works in practice, but — as the Meta researchers behind NLLB-200 acknowledge in an academic paper describing their methods — no system is completely free of biases.
Godel, similarly, is a language model trained on a vast amount of text from the web. However, unlike NLLB-200, Godel was designed to handle “open” dialogue — conversations about a range of different topics.
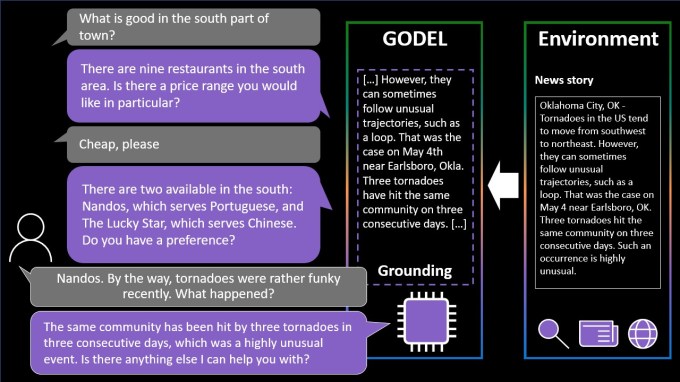
Image Credits: Microsoft
Godel can answer a question about a restaurant or have a back-and-forth dialogue about a particular subject, such as a neighborhood’s history or a recent sports game. Usefully, and like Google’s Lamda, the system can draw on content from around the web that wasn’t a part of the training dataset, including restaurant reviews, Wikipedia articles and other content on public websites.
But Godel encounters the same pitfalls as NLLB-200. In a paper, the team responsible for creating it notes that it “may generate harmful responses” owing to the “forms of social bias and other toxicity” in the data used to train it. Eliminating, or even mitigating, these biases remains an unsolved challenge in the field of AI — a challenge that might never be completely solved.
Google’s Minerva model is less potentially problematic. As the team behind it describes in a blog post, the system learned from a dataset of 118GB scientific papers and web pages containing mathematical expressions to solve quantitative reasoning problems without using external tools like a calculator. Minerva can generate solutions that include numerical calculations and “symbolic manipulation,” achieving leading performance on popular STEM benchmarks.
Minerva isn’t the first model developed to solve these types of problems. To name a few, Alphabet’s DeepMind demonstrated multiple algorithms that can aid mathematicians in complex and abstract tasks, and OpenAI has experimented with a system trained to solve grade school-level math problems. But Minerva incorporates recent techniques to better solve mathematical questions, the team says, including an approach that involves “prompting” the model with several step-by-step solutions to existing questions before presenting it with a new question.

Image Credits: Google
Minerva still makes its fair share of mistakes, and sometimes it arrives at a correct final answer but with faulty reasoning. Still, the team hopes that it’ll serve as a foundation for models that “help push the frontiers of science and education.”
The question of what AI systems actually “know” is more philosophical than technical, but how they organize that knowledge is a fair and relevant question. For example, an object recognition system may show that it “understands” that housecats and tigers are similar in some ways by allowing the concepts to overlap purposefully in how it identifies them — or maybe it doesn’t really get it and the two types of creatures are totally unrelated to it.
Researchers at UCLA wanted to see if language models “understood” words in that sense, and developed a method called “semantic projection” that suggests that yes, they do. While you can’t simply ask the model to explain how and why a whale is different from a fish, you can see how closely it associates those words with other words, like mammal, large, scales and so on. If whale associates highly with mammal and large but not with scales, you know it’s got a decent idea of what it’s talking about.
An example of where animals fall on the small to large spectrum as conceptualized by the model. Image Credits: Idan Blank/UCLA
As a simple example, they found animal coincided with the concepts of size, gender, danger and wetness (the selection was a bit weird) while states coincided with weather, wealth and partisanship. Animals are nonpartisan and states are genderless, so that all tracks.
There’s no surer test right now as to whether a model understands some words than asking it to draw them — and text-to-image models keep getting better. Google’s “Pathways Autoregressive Text-to-Image” or Parti model looks to be one of the best yet, but it’s difficult to compare it to the competition (DALL-E et al.) without access, which is something few of the models offer. You can read about the Parti approach here, at any rate.
One interesting aspect of the Google write-up is showing how the model works with increasing numbers of parameters. See how the image improves gradually as the numbers increase:

The prompt was “A portrait photo of a kangaroo wearing an orange hoodie and blue sunglasses standing on the grass in front of the Sydney Opera House holding a sign on the chest that says Welcome Friends!” Image Credits: Google
Does this mean the best models will all have tens of billions of parameters, meaning they’ll take ages to train and run only on supercomputers? For now, sure — it’s sort of a brute force approach to improving things, but the “tick-tock” of AI means that the next step isn’t to just make it bigger and better, but to make it smaller and equivalent. We’ll see who manages to pull that off.
Not one to be left out of the fun, Meta also showed off a generative AI model this week, though one that it claims gives more agency to artists using it. Having played with these generators a lot myself, part of the fun is seeing what it comes up with, but they frequently come up with nonsensical layouts or don’t “get” the prompt. Meta’s Make-A-Scene aims to fix that.
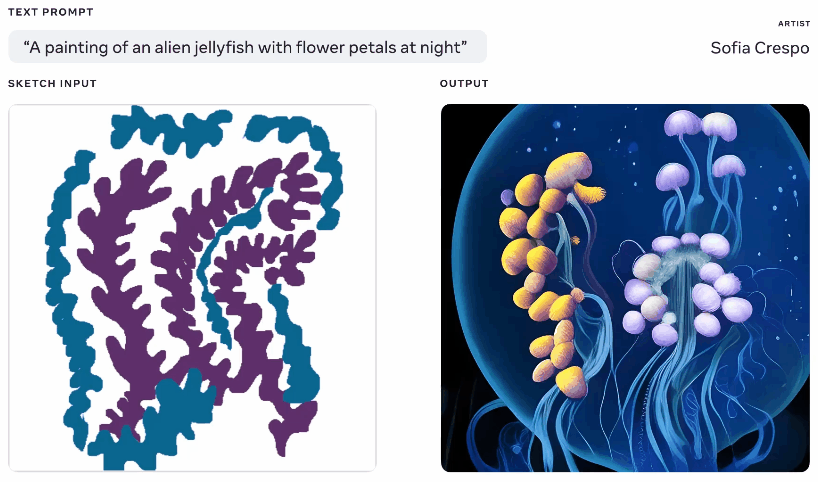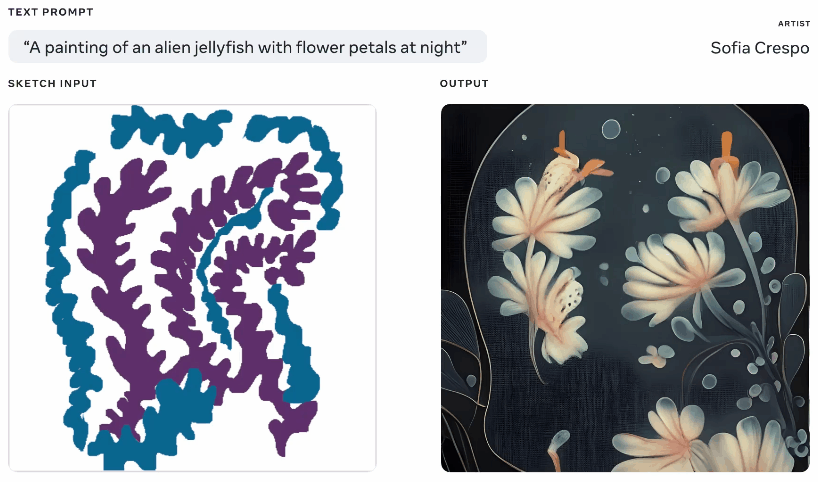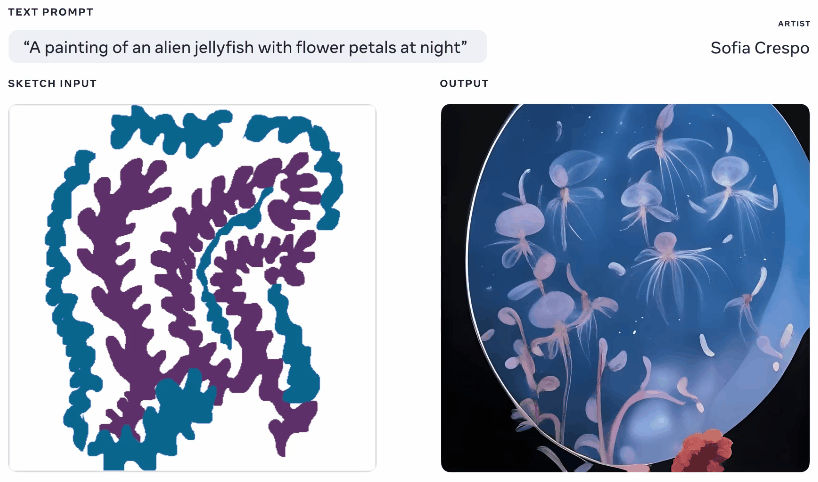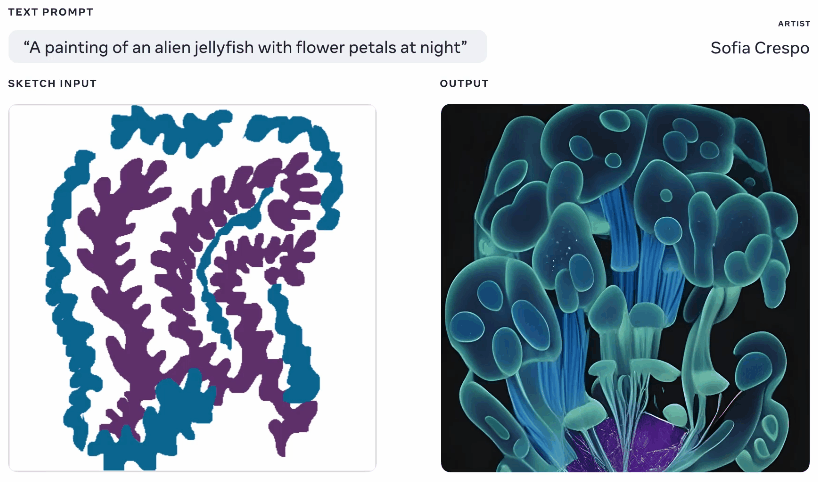
Animation of different generated images from the same text and sketch prompt. Image Credits: Meta
It’s not quite an original idea — you paint in a basic silhouette of what you’re talking about and it uses that as a foundation for generating an image on top of. We saw something like this in 2020 with Google’s nightmare generator. This is a similar concept but scaled up to allow it to create realistic images from text prompts using the sketch as a basis but with lots of room for interpretation. Could be useful for artists who have a general idea of what they’re thinking of but want to include the model’s unbounded and weird creativity.
Like most of these systems, Make-A-Scene isn’t actually available for public use, since like the others it’s pretty greedy computation-wise. Don’t worry, we’ll get decent versions of these things at home soon.