
Research in the field of machine learning and AI, now a key technology in practically every industry and company, is far too voluminous for anyone to read it all. This column, Perceptron (previously Deep Science), aims to collect some of the most relevant recent discoveries and papers — particularly in, but not limited to, artificial intelligence — and explain why they matter.
This month in AI, engineers at Penn State announced that they’ve created a chip that can process and classify nearly two billion images per second. Carnegie Mellon, meanwhile, has signed a $10.5 million U.S. Army contract to expand its use of AI in predictive maintenance. And at UC Berkeley, a team of scientists is applying AI research to solve climate problems, like understanding snow as a water resource.
The Penn State work aimed to overcome the limitations of traditional processors when applied to AI workloads — specifically recognizing and classifying images or the objects in them. Before a machine learning system can process an image, it must be captured by a camera’s image sensor (assuming it’s a real-world image), converted by the sensor from light to electrical signals, and then converted again into binary data. Only then can the system sufficiently “understand” the image to process, analyze and classify it.
Penn State engineers, including postdoctoral fellow Farshid Ashtiani, graduate student Alexander J. Geers and associate professor in electrical and systems engineering Firooz Aflatouni, designed a workaround that they claim removes the most time-consuming aspects of traditional chip-based AI image processing. Their 9.3-square-millimeter custom processor directly processes light received from an “object of interest” using what they call an “optical deep neural network.”

3D Rendering, computer board with circuits and chip. Image Credits: Xia Yuan / Getty Images
Essentially, the researchers’ processor uses “optical neurons” interconnected using optical wires, known as waveguides, to form a deep network of many layers. Information passes through the layers, with each step helping to classify the input image into one of its learned categories. Thanks to the chip’s ability to compute as light propagates through it to read and process optical signals directly, the researchers claim that the chip doesn’t need to store information and can perform an entire image classification in roughly half a nanosecond.
“We aren’t the first to come up with technology that reads optical signals directly,” Geers said in a statement, “but we are the first to create the complete system within a chip that is both compatible with existing technology and scalable to work with more complex data.” He expects the work will have applications in automatically detecting text in photos, helping self-driving cars recognize obstacles and other computer vision-related tasks.
Over at Carnegie Mellon, the college’s Auton Lab is focused on a different set of use cases: applying predictive maintenance techniques to everything from ground vehicles to power generators. Supported by the aforementioned contract, Auton Lab director Artur Dubrawski will lead an effort to conduct fundamental research to broaden the applicability of computer models of complex physical systems, known as digital twins, to many domains.
Digital twin technologies aren’t new. GE, AWS and other companies offer products that allow customers to model digital twins of machines. London-based SenSat creates digital twin models of locations for construction, mining and energy projects. Meanwhile, startups like Lacuna and Nexar are building digital twins of entire cities.
But digital twin technologies share the same limitations, chief among them inaccurate modeling proceeding from inaccurate data. As elsewhere, it’s garbage in, garbage out.
To address this and other blockers to bringing digital twins into wider use, Dubrawski’s team is collaborating with a range of stakeholders, such as clinicians in intensive care, to explore scenarios, including in healthcare. The Auton Lab aims to develop new, more efficient methods of “capturing human expertise” so that AI systems can understand contexts not well-represented in data, as well as methods for sharing that expertise with users.
One thing AI may soon have that some people seem to lack is common sense. DARPA has been funding a number of initiatives at different labs that aim to imbue robots with a general sense of what to do if things aren’t quite right when they’re walking, carrying something or gripping an object.
Ordinarily these models are quite brittle, failing miserably as soon as certain parameters are exceeded or unexpected events occur. Training “common sense” into them means they will be more flexible, with a general sense of how to salvage a situation. These aren’t particularly high-level concepts but just smarter ways of handling them. For instance, if something falls outside expected parameters, it can adjust other parameters to counteract it even if they aren’t specifically designed to do that.
This doesn’t mean robots are going to go around improvising everything — they just won’t fail quite so easily or so hard as they currently do. The current research shows that locomotion on rough terrain is better, shifting loads are carried better and unfamiliar objects are gripped better when “common sense” training is included.
The research team at UC Berkeley, by contrast, is lasering in on one domain in particular: climate change. The Berkeley AI Research Climate Initiative (BAIR) — which launched recently, organized by computer science doctoral candidates Colorado Reed and Medhini Narasimhan and computer science doctoral student Ritwik Gupta — seeks partners among climate experts, government agencies and industry to achieve goals meaningful for both climate and AI.
One of the first projects the initiative plans to tackle will use an AI technique to combine measurements from aircraft observations of snow and openly available weather and satellite data sources. AI will help to track the life cycle of snow, which isn’t currently possible without great effort, enabling the researchers to estimate and predict how much water is in the snow in the Sierra Nevada mountains — and forecast the impact on the region’s streamflow.
A press release detailing BAIR’s efforts notes that the state of snow impacts public health and the economy. Approximately 1.2 billion people rely on snow melt globally for water consumption or other purposes, and the Sierra mountains alone provide water for over half of California’s population.
Any technology or research done by the climate initiative will be openly published and won’t be exclusively licensed, Trevor Darrell, BAIR’s co-founding director and a Berkeley computer science professor, said.
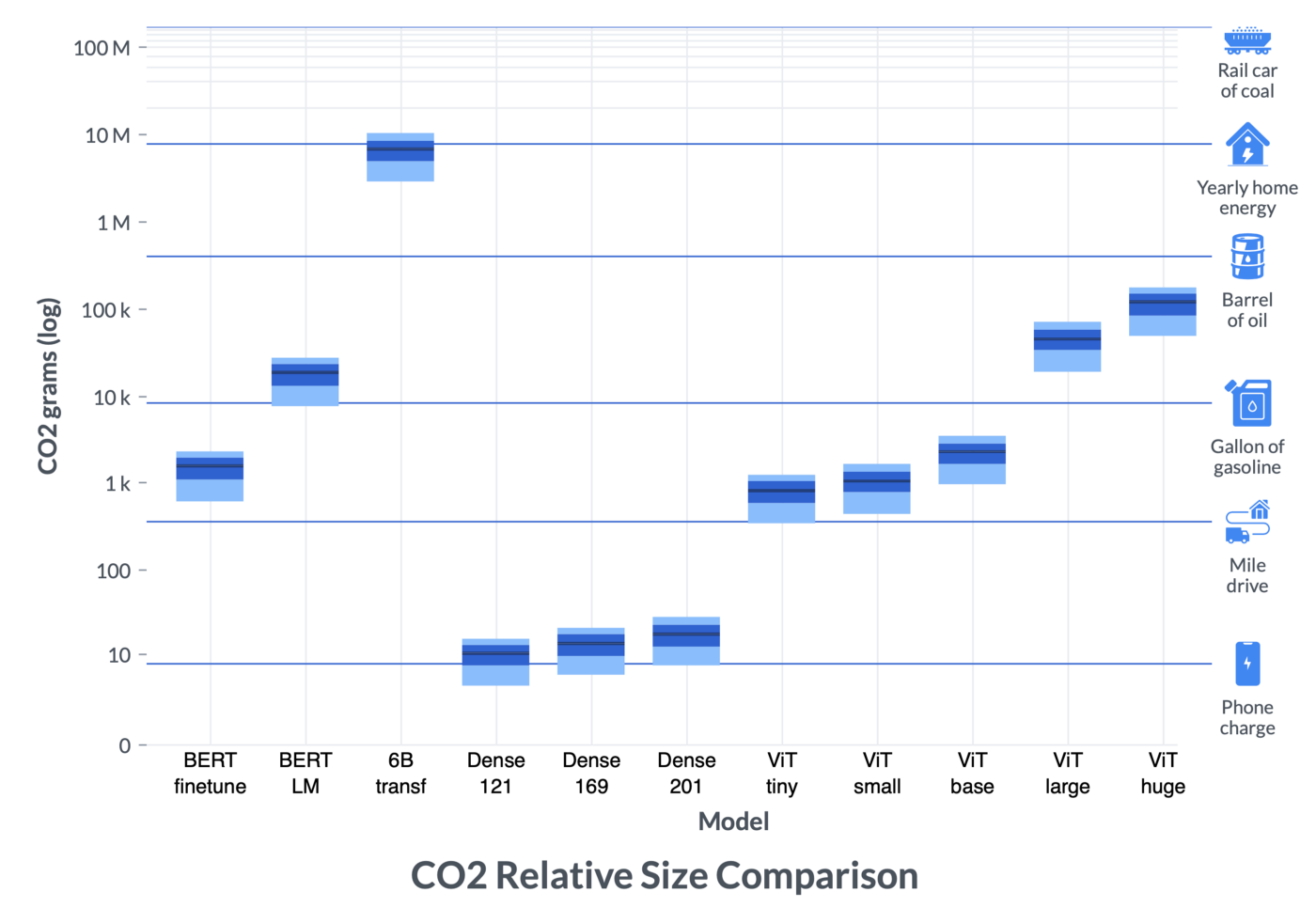
A chart showing CO2 output of different AI model training processes. Image Credits: AI2
AI itself is a contributor to climate change as well, though, as it takes enormous computing resources to train models like GPT-3 and DALL-E. The Allen Institute for AI (AI2) did a study on how these training periods could be done intelligently in order to reduce their impact on the climate. It’s not a trivial calculation: where electricity is coming from is constantly in flux and peaky usage like a day-long supercomputing run can’t just be split up to run next week when the sun is out and solar power is plentiful.
AI2’s work looks at the carbon intensity of training various models at various locations and times, part of a larger project at the Green Software Foundation to reduce the footprint of these important but energy-hogging processes.
Last but not least, OpenAI this week revealed Video PreTraining (VPT), a training technique that uses a small amount of labeled data to teach an AI system to complete tasks, like how to craft diamond tools in Minecraft. VPT entails searching the web for videos and having contractors produce data (e.g. 2,000 hours of videos labeled with mouse and keyboard actions), and then training a model to predict actions given past and future video frames. In the last step, the original videos from the web are labeled with the contractor data to train a system to predict actions given only past frames.
OpenAI used Minecraft as a test case for VPT, but the firm claims that the approach is quite general — representing a step toward “general computer-using agents.” In any case, the model is available in open source, as well as the contractor data OpenAI procured for its experiments.