
Google today announced the launch of AlloyDB, a new fully managed PostgreSQL-compatible database service that the company claims to be twice as fast for transactional workloads as AWS’s comparable Aurora PostgreSQL (and four times faster than standard PostgreSQL for the same workloads and up to 100 times faster for analytical queries).
If you’re deep into the Google Cloud ecosystem, then a fully managed PostgreSQL database service may sound familiar. The company, after all, already offers CloudSQL for PostgreSQL and Spanner, Google Cloud’s fully managed relational database service also offers a PostgreSQL interface. But these are services that offer an interface that is compatible with PostgreSQL to allow developers with these skills to use these services. AlloyDB is the standard PostgreSQL database at its core, though the team did modify the kernel to allow it to use Google’s infrastructure to its fullest, all while allowing the team to stay up to date with new versions as they launch.
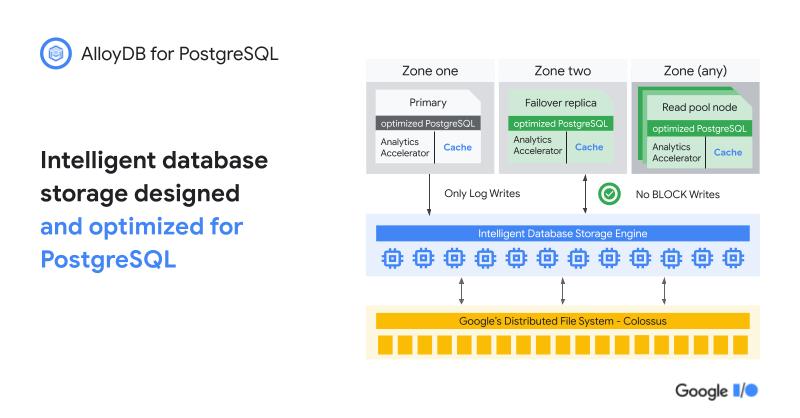
Image Credits: Google
Andi Gutmans, who joined Google as its GM and VP of Engineering for its database products in 2020 after a long stint at AWS, told me that one of the reasons the company is launching this new product is that while Google has done well in helping enterprise customers move their MySQL and PostgreSQL servers to the cloud with the help of services like CloudSQL, the company didn’t necessarily have the right offerings for those customers who wanted to move their legacy databases (Gutmans didn’t explicitly say so, but I think you can safely insert “Oracle” here) to an open source service.
“There are different reasons for that,” he told me. “First, they are actually using more than one cloud provider, so they want to have the flexibility to run everywhere. There are a lot of unfriendly licensing gimmicks, traditionally. Customers really, really hate that and, I would say, whereas probably two to three years ago, customers were just complaining about it, what I notice now is customers are really willing to invest resources to just get off these legacy databases. They are sick of being strapped and locked in.”
Add to that Postgres’ rise to becoming somewhat of a de facto standard for relational open source databases (and MySQL’s decline) and it becomes clear why Google decided that it wanted to be able to offer a dedicated high-performance PostgreSQL service.
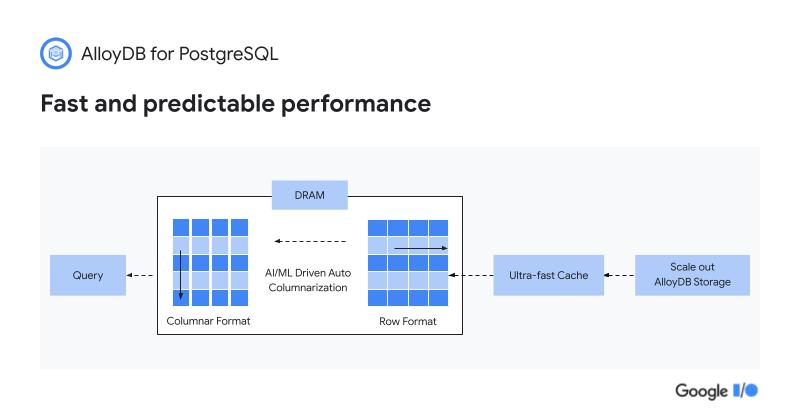
Image Credits: Google
Gutmans also noted that a lot of Google’s customers now want to use their relational databases for analytics use cases, so the team spent quite a lot of effort on making Postgres perform better for these users. Given Gutmans’ background at AWS, where he was the engineering owner for a number of AWS analytics services, that’s probably no surprise.
“When I joined AWS, it was an opportunity to stay in the developer space but really work on databases,” he explained. “That’s when I worked on things like graph databases and [Amazon] ElastiCache and, of course, got the opportunity to see how important and critical data is to customers. [ … ] That kind of audience was really a developer audience primarily, because that’s developers using databases to build their apps. Then I went into the analytics space at AWS, and I kind of discovered the other side of it. On one hand, the folks I was talking to were not necessarily developers anymore — a lot of them were on the business side or analysts — but I also then saw that these worlds are really converging.” These users wanted to get real-time insights from their data, run fraud detection algorithms over it or do real-time personalization or inventory management at scale.

Image Credits: Goolge
On the technical side, the AlloyDB team built on top of Google’s existing infrastructure, which disaggregates compute and storage. That’s the same infrastructure layer that runs Spanner, BigQuery and essentially all of Google’s services. This, Gutmans argued, already gives the service a leg up over its competition, in addition to the fact that AlloyDB specifically focuses on PostgreSQL and nothing else. “You don’t always get to optimize as much when you have to support more than one [database engine and query language]. We decided that what enterprises are asking us for [is] Postgres for these legacy database migrations, so let’s just do the best in Postgres.”
The changes the team made to the Postgres kernel, for example, now allow it to scale the system linearly to over 64 virtual cores while on the analytical side, the team built a custom machine learning-based caching service to learn a customer’s access patterns and then convert Postgres’ row format into an in-memory columnar format that can be analyzed significantly faster.
