
While some startups are trying to get people to leave spreadsheets behind, Canvas, which is developing a collaborative data exploration tool, is going all in with a spreadsheet-like interface for non-technical teams to access the information they need without bothering data teams.
Luke Zapart, who started Canvas in late 2020 with his former Flexport colleagues Ryan Buick and Will Pride, says the company is building a “Figma meets Looker” after experiencing the data-finding pain points while working at Flexport.
“Our data team would get swamped with mundane, tedious data requests that were more than they could handle, and then the business teams would give up on waiting for answers for days, and just essentially go to the business intelligence tool and hit the ‘export to CSV’ button and just pivot in Google Sheets,” Zapart explained. “Fundamentally, this resulted in a breakdown of trust between the business and the data sides of the house. That inspired us to leave Flexport and really try to understand its problem and solve it.”
The data space is “experiencing a renaissance” where traditional business intelligence tools are getting unbundled by focused, best-in-class tools, he added. However, business users are being locked out of many of the benefits of the modern data stack unless they are proficient in Structured Query Language (SQL) or have a well-staffed data team.
Canvas was created as a spreadsheet-based workspace that lets business teams make independent decisions without taking a SQL class, and gives data teams time to focus on their strategic work.
Here’s how it works: Users start with their own “blank canvas” and can choose the data they are looking for from a table of definitions the data team provides. Once you find the data, you can drag and drop the table on the canvas and interact with it in the same manner you would in Google Sheets. For example, use the “pivot” button to build out a certain metric and then create graphs or charts.
“You can interact with the chart and start to drag it around this canvas,” Buick said. “This is where it starts to look and feel more like Figma, and we really found that this is a new way of trying to work with data because it makes it much easier to iterate, prototype and just match your mental model of however you want to think about the problem you’re trying to solve. The cool part is that we know business teams are going to get stuck, so that is where collaboration comes into play — you can tag people on the team and ask them to check it out.”
In addition to reducing the number of questions to the data team, the company is seeing its tool being adopted by startups that have found Canvas to be an easy way to reuse business logic already modeled in DBT, Buick said.
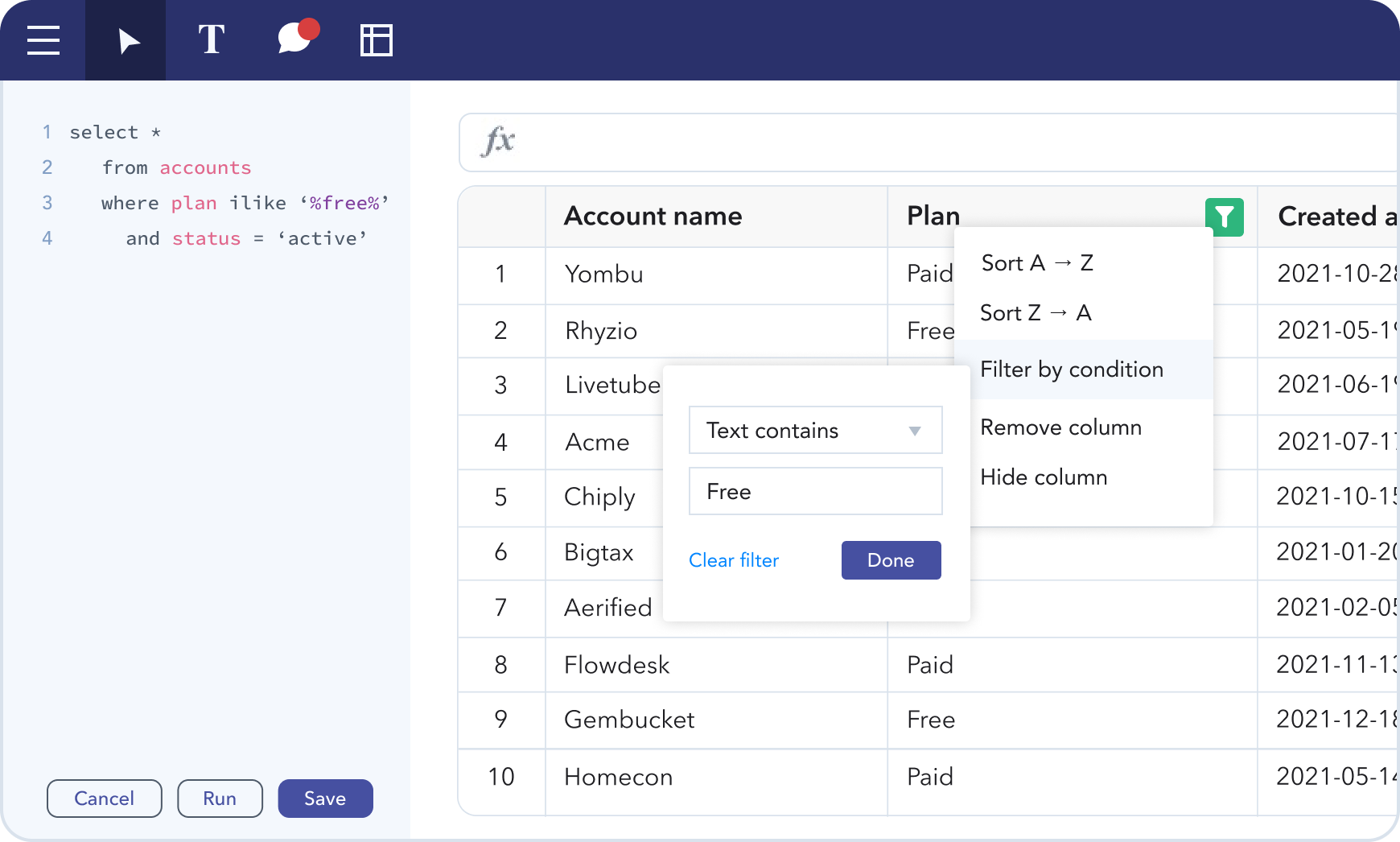
Canvas example. Image Credits: Canvas
On Friday, the company launched its platform to the public after raising $4.2 million in a round, led by Sequoia, with participation from Abstract Ventures, SV Angel and a group of two dozen individual investors. The list includes data experts Calvin French-Owen (Segment), Taylor Brown (Fivetran), Boris Jabes (Census) and Olivier Pomel (DataDog), operators Jack Altman (Lattice), Tony Xu (Doordash), Ryan Petersen (Flexport), Bryant Chou (Webflow), Max Mullen (Instacart) and angel investors.
Recognizing that it would be a huge task to build a data workspace for business teams, the Canvas founders decided to go after capital. Zapart said they were deliberate in the kinds of investors they wanted to work with, like world-class data experts and founders of companies in the data space.
The company has six employees currently and has a handful of paying customers and a number of design partners that it is working with. The new capital will go into hiring more engineers to build out the company’s roadmap, which includes self-serve models, and will engage in a series of product launches as it develops further go-to-market and product development strategies. Canvas will look into another round of funding when it gets to the first 10 to 20 customers, Zapart said.
Konstantine Buhler, partner at Sequoia, said the company has a “cohesive, technically strong team” and that the modern data stack has spawned opportunities for great companies to be built and to serve enterprise customers. In Canvas, he saw a company that is creating a collaborative front end to that entire stack.
“The upside is you have all your data in one place instead of downloading it into Excel and then doing pivot tables, all of which is pretty difficult,” Buhler added. “Here, you can just plug right into the system and see it right in front of you. The team has done amazing work together at Flexport and now they’re going after a problem that is very material and everyone can relate to it. The big vision is if we can create self-serve, that is a huge enabler as it democratizes access to data and makes everyone in the company empowered by data as opposed to just a few people who have full access.”