
Google first revealed BigQuery Omni, its Anthos-based multi-cloud data analytics solution, last summer. Today, at its annual Cloud Next event, the company announced that BigQuery Omni is generally available. What makes Omni different from similar services is that it allows its users to use the standard BigQuery interface they know to query data that sits on other clouds, including Microsoft’s Azure and AWS — all without having to move copies of their data between these clouds.
“Everyone knows a data silo is bad, but the reality is that right now, we are building data silos, just in different clouds,” Gerrit Kazmaier, Google’s VP & GM for Databases, Analytics & Looker, told me. “There is a new generation of data silos and we recognize that most of the companies in the world live in a multi-cloud reality, and with BigQuery Omni, we basically give them the possibility to do analytics across them — cross-cloud analytics, which I think is the ultimate in simplicity, because you don’t need to think anymore about where do I move my data and all of the repetition and redundancy in governing it. The single pane of glass and that single processing framework — it’s a feat of engineering that the team basically took BigQuery and brought many parts of it to other clouds.”
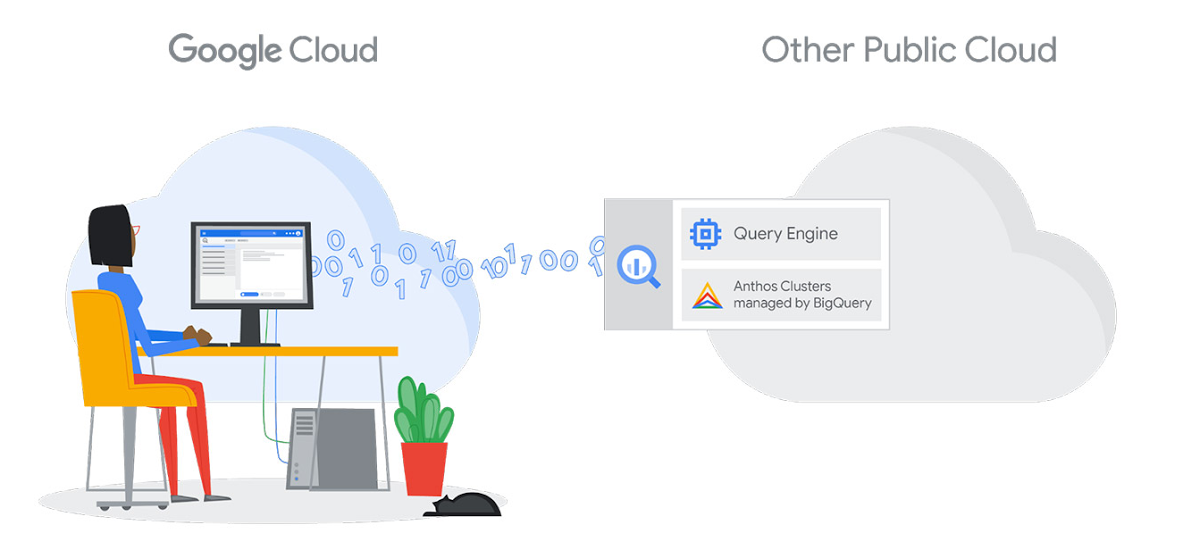
Image Credits: Google
A number of Google Cloud customers are already making good use of these capabilities. Kazmaier noted that Johnson & Johnson, for example, uses it to combine its data in Google Cloud with S3 data on AWS, while Electronic Arts uses it to combine advertising data with in-game purchases.
Talking about data silos, Google also today noted that Dataplex, a tool that allows enterprises to manage, monitor and govern their data across data lakes and warehouses, will also be generally available later this year. It is currently in preview.
Like so many of Google Cloud’s other announcements today, both of these services recognize that virtually every enterprise now operates in a multi-cloud environment — and almost by default, that means that a lot of valuable data is spread across systems. Using multiple systems to manage this data is cumbersome and error-prone, but most importantly, it’s hard (and often expensive) to combine all of this data in a single system. Google’s approach here is to just bring all of its own services to these various clouds and then manage them from GCP. That’s the approach it took with Anthos to manage Kubernetes clusters and, unsurprisingly, that now also allow it to run some core GCP services outside of its own cloud, too.