CockroachDB was intended to be a global database from the beginning. The founders of Cockroach Labs wanted to ensure that data written in one location would be viewable immediately in another location 10,000 miles away. The use case was simple, but the work needed to make it happen was herculean.
The company is betting the farm that it can solve one of the largest challenges for web-scale applications. The approach it’s taking is clever, but it’s a bit complicated, particularly for the non-technical reader. Given its history and engineering talent, the company is in the process of pulling it off and making a big impact on the database market, making it a technology well worth understanding. In short, there’s value in digging into the details.
Using CockroachDB’s multiregion feature to segment data according to geographic proximity fulfills Cockroach Labs’ primary directive: To get data as close to the user as possible.
In part 1 of this EC-1, I provided a general overview and a look at the origins of Cockroach Labs. In this installment, I’m going to cover the technical details of the technology with an eye to the non-technical reader. I’m going to describe the CockroachDB technology through three questions:
- What makes reading and writing data over a global geography so hard?
- How does CockroachDB address the problem?
- What does it all mean for those using CockroachDB?
What makes reading and writing data over a global geography so hard?
Spencer Kimball, CEO and co-founder of Cockroach Labs, describes the situation this way:
There’s lots of other stuff you need to consider when building global applications, particularly around data management. Take, for example, the question and answer website Quora. Let’s say you live in Australia. You have an account and you store the particulars of your Quora user identity on a database partition in Australia.
But when you post a question, you actually don’t want that data to just be posted in Australia. You want that data to be posted everywhere so that all the answers to all the questions are the same for everybody, anywhere. You don’t want to have a situation where you answer a question in Sydney and then you can see it in Hong Kong, but you can’t see it in the EU. When that’s the case, you end up getting different answers depending where you are. That’s a huge problem.
Reading and writing data over a global geography is challenging for pretty much the same reason that it’s faster to get a pizza delivered from across the street than from across the city. The essential constraints of time and space apply. Whether it’s digital data or a pepperoni pizza, the further away you are from the source, the longer stuff takes to get to you.
The essential objective of data architecture is bringing data as close as possible to the consuming party. One approach is just to have an offline copy on your own device. This is why Amazon downloads an e-book onto your Kindle. There’s nothing between you and the data — no network, no firewall, nothing. You can’t get much closer to the data than holding it in your hand.
While a single download works for data that doesn’t change often, like an e-book, rapidly changing data such as the price of a stock requires a technology far more sophisticated. This is where databases come into play.
A database is intended to be a central location that handles massive amounts of reading and writing of data that occurs quickly, often at intervals of a fraction of second. While often only one author will write a Kindle book, a database is designed to allow millions, maybe billions of “authors” to write data to it and then read that new data once it’s written. It’s a very powerful technology, but it’s not magical. The constraints of time and space are always present.
Image Credits: Andriy Onufriyenko / Getty Images
Let’s go back to the Quora example Kimball describes above. A New York-based user writing the answer to a question to a database hosted in NYC is going to see that answer well before users in Sydney. Depending on the condition of the network, that lag could be anywhere from a half a second to a few seconds. As Kimball says, “That’s a huge problem.”
Global applications address this problem by setting up database servers all over the world. When a user makes a change in one nearby database server, it’s replicated to all the other database servers around the planet. Then when it comes time to read the data, users access the database server closest to them.
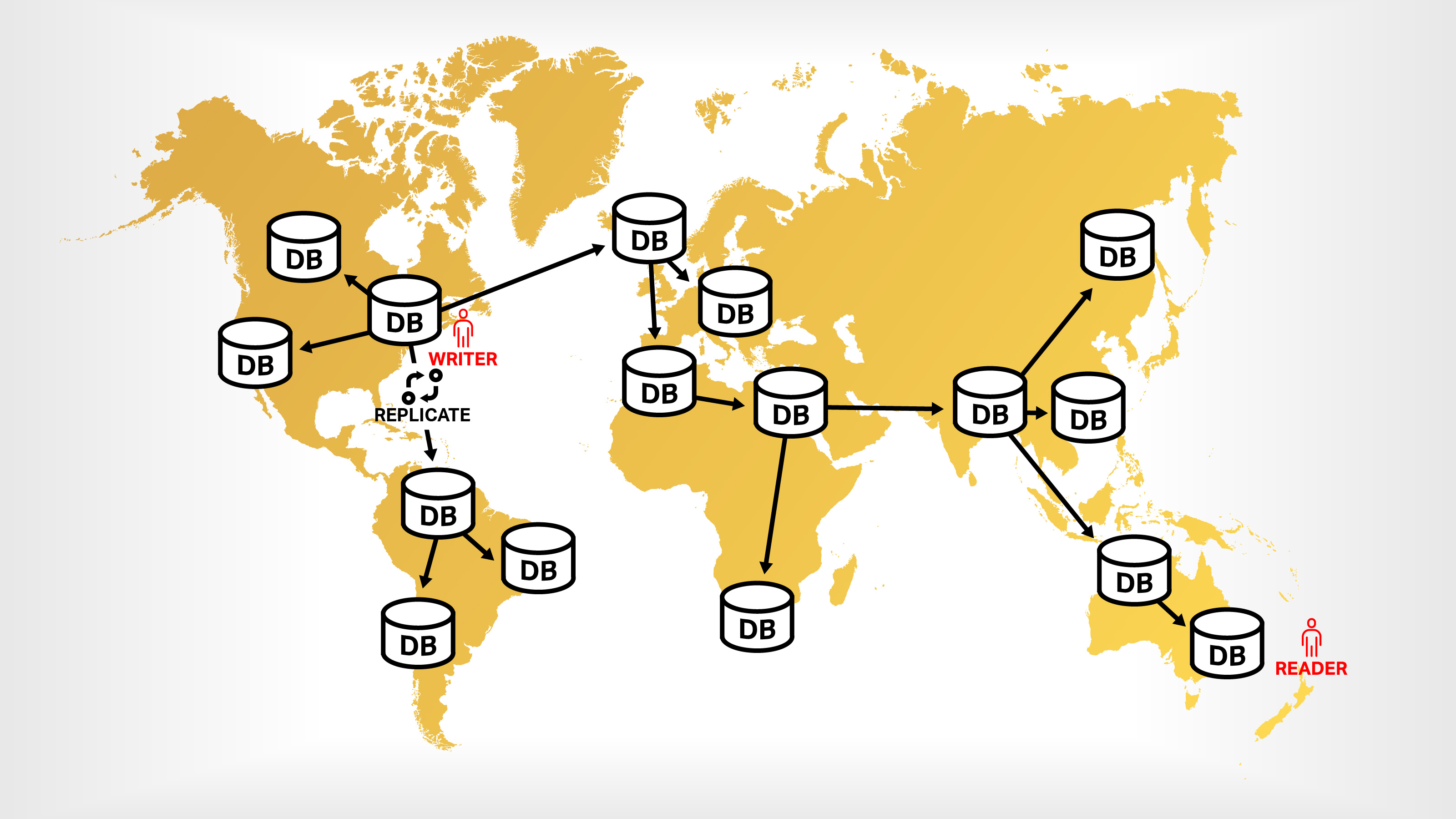
Figure 1. Under the right conditions, replicating data across the globe can allow users to read the latest write to a database. Image Credits: Bob Reselman with Bryce Durbin
Replication makes it so users don’t have to take a trip across the planet to read data, but it creates another problem: Synchronization. Again, let’s look at the Quora scenario, which is depicted in Figure 1.
Let’s say a user in NYC asks a question, “Who is the greatest guitarist of all time?” That user uploads the question to the NYC database server, and users in NYC will see the question immediately. Users in Sydney won’t see it for a second or two. Thus, the database server in Sydney is out of sync with the database server in NYC. Sydney will eventually get the new data as part of the worldwide replication process, but there will be lag. Once all the database servers catch up, if there’s no more activity against the guitarist question, things are in sync.
But then, somebody in Paris provides an answer, “Eric Clapton is the greatest guitarist of all time.” The user in Paris answers the question by making a write to a database server in Western Europe. At that point once again, all the other replicating database servers are out-of-sync. People in Paris know the Eric Clapton answer. But users in NYC don’t and neither do the users in Sydney. It’s going to take time for the replication to propagate so all the database servers know about Eric Clapton.
In a way, we’re back to where we started: The immutable law of time and space that says the closer you are to the data, the faster you can read it. Only in this case, instead of the distance being defined as the distance between user and database server, it’s the distance between the database servers themselves.
This problem of data inconsistency has been around for a long time, and in fact, it has a formal definition called the CAP theorem.
According to the CAP theorem (which stands for consistency, availability, partition), when you spread data out over many database servers or partitions (P), you must make a sacrifice. You can have the most consistent data (C) eventually or you can have older, inconsistent data available (A) immediately. What you can’t have is the most current data immediately.
This problem is what makes reading and writing data over a global geography hard, and it’s what CockroachDB is attempting to solve.
How does CockroachDB address the problem?

Cockroach Labs staff. Image Credits: Cockroach Labs
CockroachDB addresses the problem of writing and reading data as fast as possible on a global basis by placing geographic optimization front and center in its database design while also automating a lot of the detailed work around performance. According to Andy Woods, group product manager at Cockroach Labs, “This is about making it easy for you to have reliable, low-latency applications on a global scale.”
To this end, Cockroach Labs introduces a feature in database design called multiregion database architecture. Let’s dive into the details.
Understanding multiregion databases
To handle the scale of most datasets, database technologies often segment data using a logical strategy called sharding, which defines that certain data will be placed on certain database servers.
Traditionally, shards are based on some standardized feature of the dataset. For instance, the full range of zip codes could be subdivided into 10 categories based on the first number of the zip code. Each shard would be stored on a distinct computer, hard drive or even a data center, according to the given sharding logic.
The benefit of sharding is that it makes retrieving data easy. Whenever a user executes a query against data in a database, the database engine scours the database to retrieve and assemble the data according to criteria of the query. For example, “give me all the users who live in a range of zip codes between 50000 and 50009” would be directed to the database server that hosts that particular range of zip codes.
In a relational database, this means going through each table’s rows to find the data of interest. This can take a lot of time in a large database that might have millions of rows of data. However, when the rows are grouped together in close proximity on a computer’s hard disk or even within the same regional data center according to a logical rule, the amount of time to execute the query decreases, in many cases dramatically as depicted in Figure 2. Sharding data alleviates some of the burden imposed by the CAP theorem.
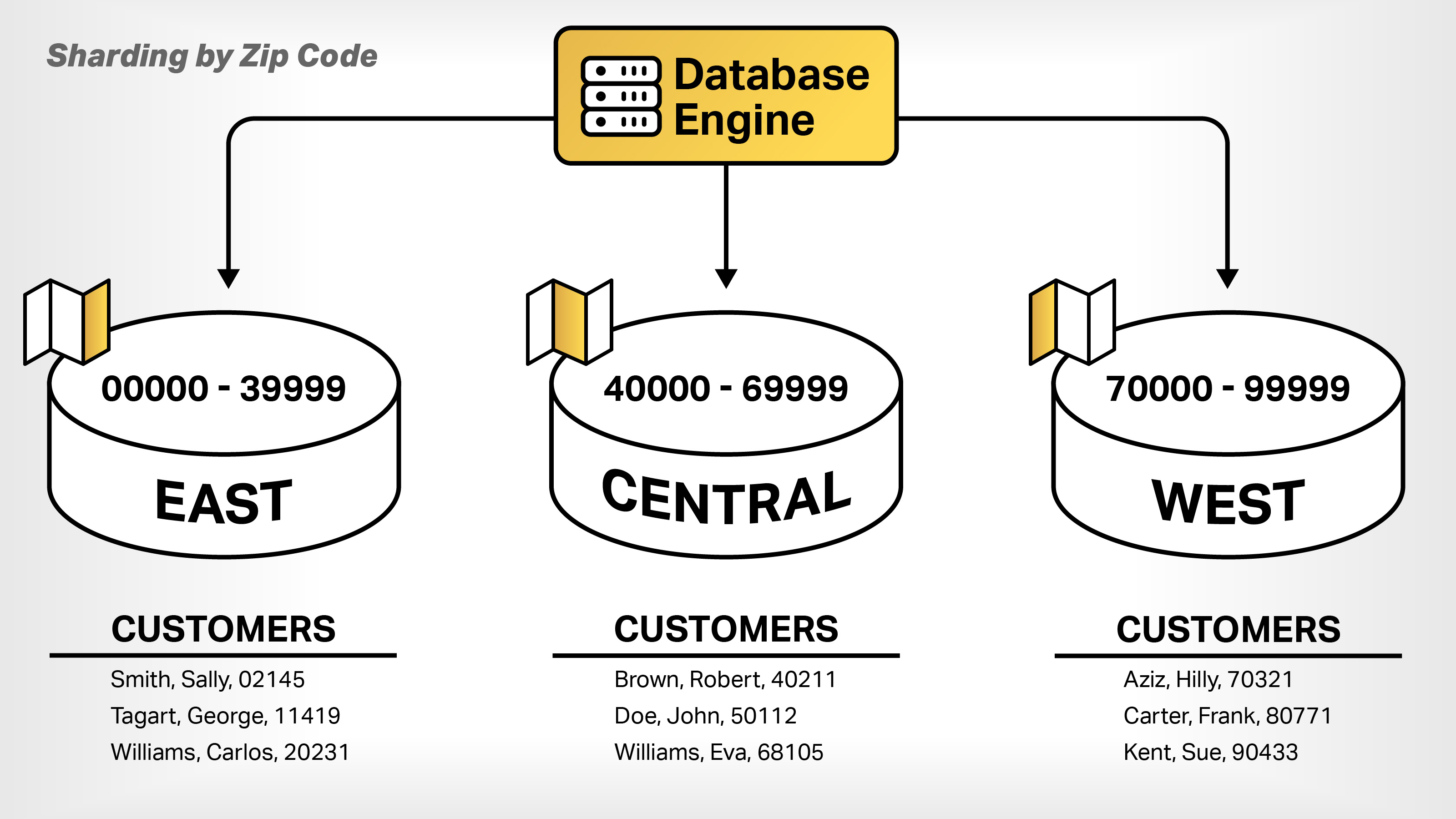
Figure 2. Sharding data according to region makes data retrieval faster. Image Credits: Bob Reselman with Bryce Durbin
The downside of sharding is that it takes a lot of technical know-how and ongoing administration to get it to work reliably. Doing something as simple as adding a new column to a table or changing the sharding logic are risky, time-consuming tasks that require a good deal of technical expertise. One wrong move and the company’s database can be in a world of pain.
Most sharding logic is based on data, but there is a different approach: Taking into account physical geography to group data based on where a user is located. In a multiregion database, data is segmented and spread out across a cluster of physical database servers according to a policy defined by geography. CockroachDB uses a multiregion database architecture to make a lot of the pain of sharding go away.
With CockroachDB, a database engineer will declare a logical database to be multiregion. Then the logical database or even individual tables will be assigned to one or many regions throughout the planet.
Figure 3 illustrates a CockroachDB database named MyDB that’s bound to database servers in the US EAST and US WEST regions. Notice that three tables in the MyDB database are bound to the US WEST region and one table is bound to the US EAST region. This is an example of using the multiregion feature to segment tables in a CockroachDB to specific geographic locations.
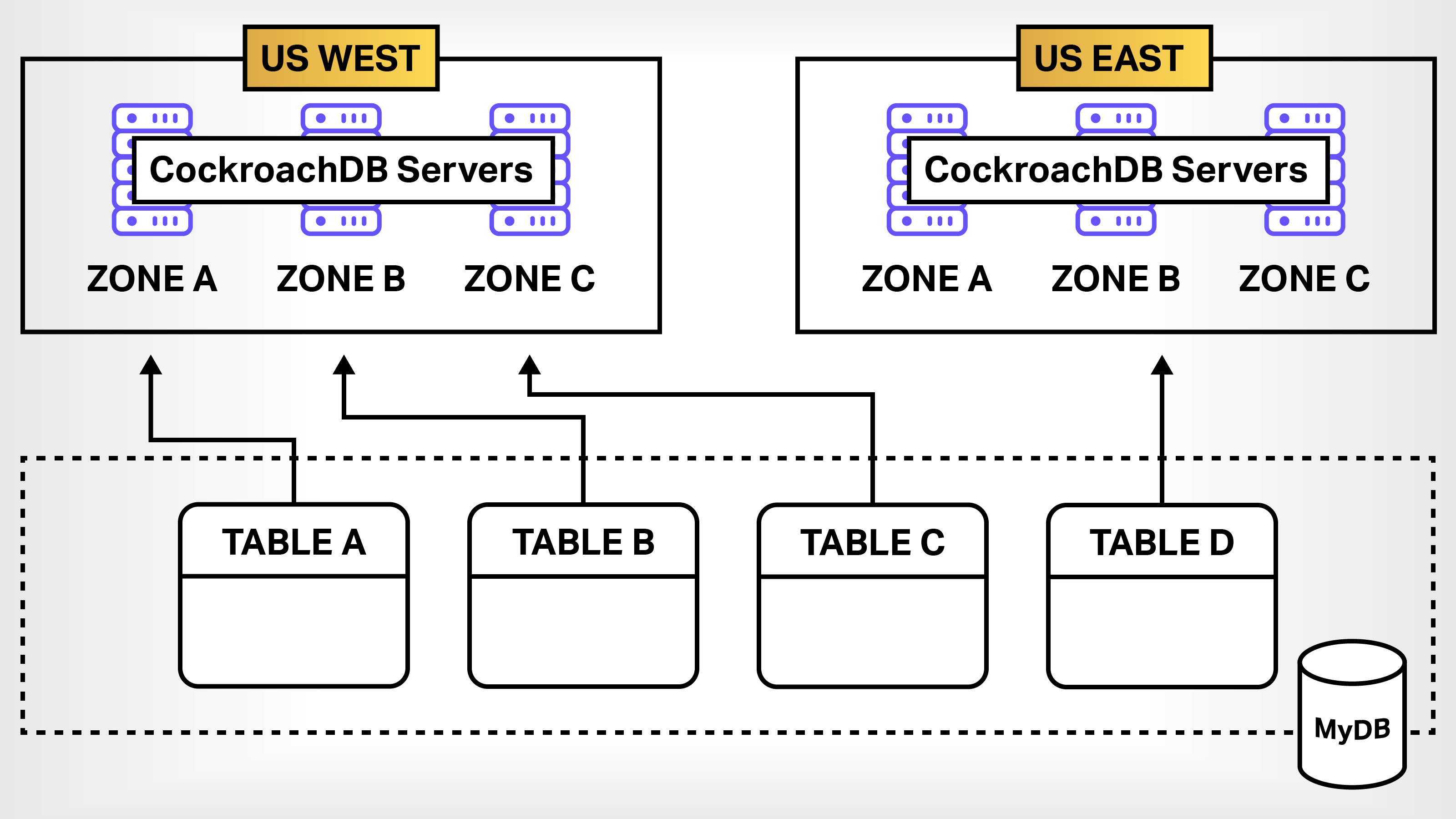
Figure 3. CockroachDB’s multiregion feature abstracts away data partitioning and replication according to region. Image Credits: Bob Reselman with Bryce Durbin
Using CockroachDB’s multiregion feature to segment data according to geographic proximity fulfills Cockroach Labs’ primary directive: To get data as close to the user as possible.
Understanding row-level partitioning
There’s more to this. Cockroach Labs takes the concept of geographical data segmentation even further by providing the ability to assign individual rows of a table to a region. This is called row-level geopartitioning, and in the world of database geekiness, it’s a very, very big deal. So much so, in fact, that Cockroach Labs offers it only to paying enterprise customers.
Take a look at Figure 4, which shows a simple table of customers listed by last name, first name, city, state and zip code.
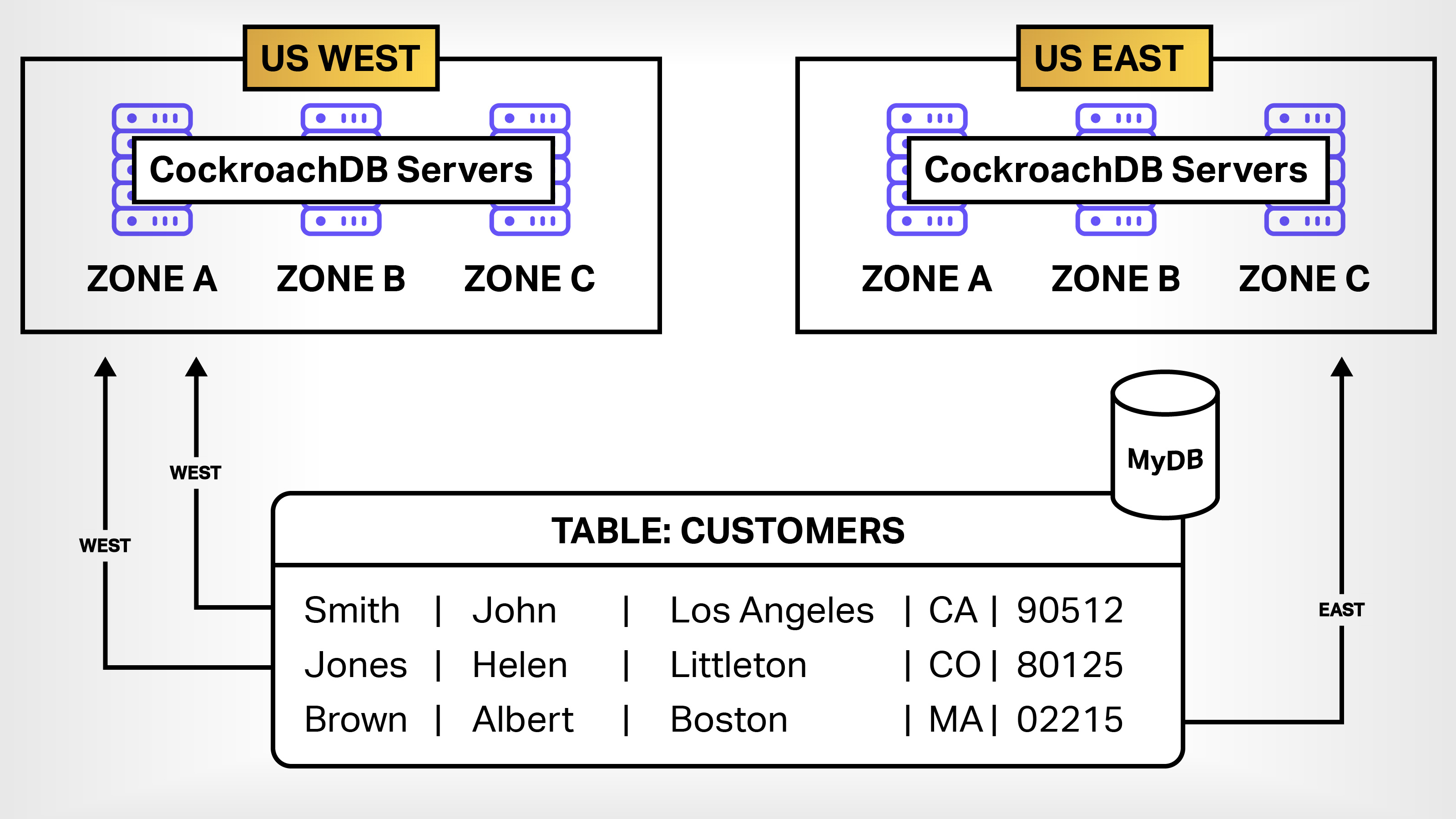
Figure 4. CockroachDB allows developers to assign rows in a table to specific geographic regions. Image Credits: Bob Reselman with Bryce Durbin
Notice that the first two rows of the table have customers with zip codes that correspond to the Western United States while the last row has a customer with a zip code that corresponds to the East Coast. When CockroachDB’s row-level partitioning feature is enabled, it automatically puts the data for the West Coast customers in the US WEST region and the East Coast customers in the US EAST region. The benefit is that applications running in the West Coast will access West Coast customer data lightning fast.
In a way, the company is trying to defy the essential principle the CAP theorem. Remember, in a partitioned database, you can have consistent data eventually or inconsistent data immediately, but you can’t have consistent data now. CockroachDB is cheating the theorem by focusing on the “P” — partitioning the data in a way that most users can have both consistent and available data most, if not all, of the time.
Row-level geopartitioning is a very big deal. It’s very hard to pull off. But it is well worth the effort because it provides the benefits of fine-grain sharding without the huge operational headaches. CockroachDB wants to do all the work.
What does it all mean for those using CockroachDB?
CockroachDB has a lot to offer companies that need to manage data on a global scale. The data management features that support partitioning, whether at the database, table or row levels, are done automatically by the CockroachDB server engine. It’s a powerful addition to database architecture.
But it does incur a learning curve. Developers will need to take some time to learn the enhancements that Cockroach Labs implemented in its version of SQL, the standard query language used to program databases.
CockroachDB has another feature that provides greater control over fault tolerance. called a Survival Goal. Fault tolerance is the ability of a database to recover from system failure. When you have a worldwide database infrastructure that can have hundreds, if not a few thousand, physical database servers, losing a server due to machine or network failure is commonplace.
A Survival Goal is a configuration setting by which a CockroachDB database administrator (DBA) declares how the logical database will replicate data across a cluster of database servers. Survival Goals loom large in Cockroach Labs’ approach to its database architecture. Developers and DBAs will need to take the time to learn how to work with Survival Goals, as it is a concept baked into the CockroachDB way of doing things.
Finally, a real-world impact that companies will encounter when deciding upon CockroachDB is accepting the degree of commitment that goes with adopting the technology. Deciding on a database is a big decision. When adopted, a database typically will be with a company for years, if not decades. Once a company chooses to use CockroachDB, it can be a career-enhancing or a career-ending event for those making the decision. It all depends on the success of the adoption. Careful planning about how the database fits with the architecture of an application is critical.
While it can be used for any application, CockroachDB is best suited for enterprises that want their users across the world to have lightning-fast access to global data in an accurate, reliable manner. There are simpler databases for applications with fewer requirements and less need for performance.
All that said, CockroachDB offers something special and unique for very valuable customers, and that makes its business incredibly interesting, the topic of the next part of this EC-1.
CockroachDB EC-1 Table of Contents
- Introduction
- Part 1: Origin story
- Part 2: Technical design
- Part 3: Developer relations and business
- Part 4: Competitive landscape and future
Also check out other EC-1s on Extra Crunch.